 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Listen, Look, Drive: Coupling Audio Instructions for User-aware VLA-based Autonomous Driving
Jan 17, 2026Vision Language Action (VLA) models promise an open-vocabulary interface that can translate perceptual ambiguity into semantically grounded driving decisions, yet they still treat language as a static prior fixed at inference time. As a result, the model must infer continuously shifting objectives from pixels alone, yielding delayed or overly conservative maneuvers. We argue that effective VLAs for autonomous driving need an online channel in which users can influence driving with specific intentions. To this end, we present EchoVLA, a user-aware VLA that couples camera streams with in situ audio instructions. We augment the nuScenes dataset with temporally aligned, intent-specific speech commands generated by converting ego-motion descriptions into synthetic audios. Further, we compose emotional speech-trajectory pairs into a multimodal Chain-of-Thought (CoT) for fine-tuning a Multimodal Large Model (MLM) based on Qwen2.5-Omni. Specifically, we synthesize the audio-augmented dataset with different emotion types paired with corresponding driving behaviors, leveraging the emotional cues embedded in tone, pitch, and speech tempo to reflect varying user states, such as urgent or hesitant intentions, thus enabling our EchoVLA to interpret not only the semantic content but also the emotional context of audio commands for more nuanced and emotionally adaptive driving behavior. In open-loop benchmarks, our approach reduces the average L2 error by $59.4\%$ and the collision rate by $74.4\%$ compared to the baseline of vision-only perception. More experiments on nuScenes dataset validate that EchoVLA not only steers the trajectory through audio instructions, but also modulates driving behavior in response to the emotions detected in the user's speech.
MIND: From Passive Mimicry to Active Reasoning through Capability-Aware Multi-Perspective CoT Distillation
Jan 07, 2026While Large Language Models (LLMs) have emerged with remarkable capabilities in complex tasks through Chain-of-Thought reasoning, practical resource constraints have sparked interest in transferring these abilities to smaller models. However, achieving both domain performance and cross-domain generalization remains challenging. Existing approaches typically restrict students to following a single golden rationale and treat different reasoning paths independently. Due to distinct inductive biases and intrinsic preferences, alongside the student's evolving capacity and reasoning preferences during training, a teacher's "optimal" rationale could act as out-of-distribution noise. This misalignment leads to a degeneration of the student's latent reasoning distribution, causing suboptimal performance. To bridge this gap, we propose MIND, a capability-adaptive framework that transitions distillation from passive mimicry to active cognitive construction. We synthesize diverse teacher perspectives through a novel "Teaching Assistant" network. By employing a Feedback-Driven Inertia Calibration mechanism, this network utilizes inertia-filtered training loss to align supervision with the student's current adaptability, effectively enhancing performance while mitigating catastrophic forgetting. Extensive experiments demonstrate that MIND achieves state-of-the-art performance on both in-distribution and out-of-distribution benchmarks, and our sophisticated latent space analysis further confirms the mechanism of reasoning ability internalization.
Search Self-play: Pushing the Frontier of Agent Capability without Supervision
Oct 21, 2025Reinforcement learning with verifiable rewards (RLVR) has become the mainstream technique for training LLM agents. However, RLVR highly depends on well-crafted task queries and corresponding ground-truth answers to provide accurate rewards, which requires massive human efforts and hinders the RL scaling processes, especially under agentic scenarios. Although a few recent works explore task synthesis methods, the difficulty of generated agentic tasks can hardly be controlled to provide effective RL training advantages. To achieve agentic RLVR with higher scalability, we explore self-play training for deep search agents, in which the learning LLM utilizes multi-turn search engine calling and acts simultaneously as both a task proposer and a problem solver. The task proposer aims to generate deep search queries with well-defined ground-truth answers and increasing task difficulty. The problem solver tries to handle the generated search queries and output the correct answer predictions. To ensure that each generated search query has accurate ground truth, we collect all the searching results from the proposer's trajectory as external knowledge, then conduct retrieval-augmentation generation (RAG) to test whether the proposed query can be correctly answered with all necessary search documents provided. In this search self-play (SSP) game, the proposer and the solver co-evolve their agent capabilities through both competition and cooperation. With substantial experimental results, we find that SSP can significantly improve search agents' performance uniformly on various benchmarks without any supervision under both from-scratch and continuous RL training setups. The code is at https://github.com/Alibaba-Quark/SSP.
RAU: Reference-based Anatomical Understanding with Vision Language Models
Sep 26, 2025Anatomical understanding through deep learning is critical for automatic report generation, intra-operative navigation, and organ localization in medical imaging; however, its progress is constrained by the scarcity of expert-labeled data. A promising remedy is to leverage an annotated reference image to guide the interpretation of an unlabeled target. Although recent vision-language models (VLMs) exhibit non-trivial visual reasoning, their reference-based understanding and fine-grained localization remain limited. We introduce RAU, a framework for reference-based anatomical understanding with VLMs. We first show that a VLM learns to identify anatomical regions through relative spatial reasoning between reference and target images, trained on a moderately sized dataset. We validate this capability through visual question answering (VQA) and bounding box prediction. Next, we demonstrate that the VLM-derived spatial cues can be seamlessly integrated with the fine-grained segmentation capability of SAM2, enabling localization and pixel-level segmentation of small anatomical regions, such as vessel segments. Across two in-distribution and two out-of-distribution datasets, RAU consistently outperforms a SAM2 fine-tuning baseline using the same memory setup, yielding more accurate segmentations and more reliable localization. More importantly, its strong generalization ability makes it scalable to out-of-distribution datasets, a property crucial for medical image applications. To the best of our knowledge, RAU is the first to explore the capability of VLMs for reference-based identification, localization, and segmentation of anatomical structures in medical images. Its promising performance highlights the potential of VLM-driven approaches for anatomical understanding in automated clinical workflows.
Advancing Limited-Angle CT Reconstruction Through Diffusion-Based Sinogram Completion
May 26, 2025Limited Angle Computed Tomography (LACT) often faces significant challenges due to missing angular information. Unlike previous methods that operate in the image domain, we propose a new method that focuses on sinogram inpainting. We leverage MR-SDEs, a variant of diffusion models that characterize the diffusion process with mean-reverting stochastic differential equations, to fill in missing angular data at the projection level. Furthermore, by combining distillation with constraining the output of the model using the pseudo-inverse of the inpainting matrix, the diffusion process is accelerated and done in a step, enabling efficient and accurate sinogram completion. A subsequent post-processing module back-projects the inpainted sinogram into the image domain and further refines the reconstruction, effectively suppressing artifacts while preserving critical structural details. Quantitative experimental results demonstrate that the proposed method achieves state-of-the-art performance in both perceptual and fidelity quality, offering a promising solution for LACT reconstruction in scientific and clinical applications.
Bayesian learning of the optimal action-value function in a Markov decision process
May 03, 2025
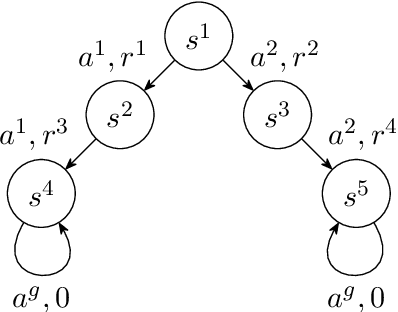

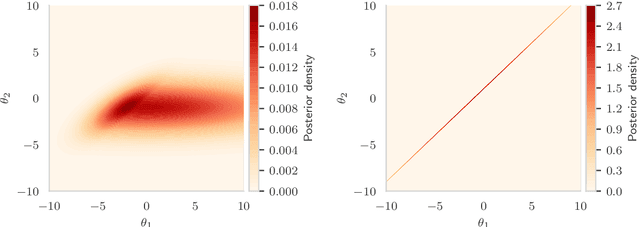
The Markov Decision Process (MDP) is a popular framework for sequential decision-making problems, and uncertainty quantification is an essential component of it to learn optimal decision-making strategies. In particular, a Bayesian framework is used to maintain beliefs about the optimal decisions and the unknown ingredients of the model, which are also to be learned from the data, such as the rewards and state dynamics. However, many existing Bayesian approaches for learning the optimal decision-making strategy are based on unrealistic modelling assumptions and utilise approximate inference techniques. This raises doubts whether the benefits of Bayesian uncertainty quantification are fully realised or can be relied upon. We focus on infinite-horizon and undiscounted MDPs, with finite state and action spaces, and a terminal state. We provide a full Bayesian framework, from modelling to inference to decision-making. For modelling, we introduce a likelihood function with minimal assumptions for learning the optimal action-value function based on Bellman's optimality equations, analyse its properties, and clarify connections to existing works. For deterministic rewards, the likelihood is degenerate and we introduce artificial observation noise to relax it, in a controlled manner, to facilitate more efficient Monte Carlo-based inference. For inference, we propose an adaptive sequential Monte Carlo algorithm to both sample from and adjust the sequence of relaxed posterior distributions. For decision-making, we choose actions using samples from the posterior distribution over the optimal strategies. While commonly done, we provide new insight that clearly shows that it is a generalisation of Thompson sampling from multi-arm bandit problems. Finally, we evaluate our framework on the Deep Sea benchmark problem and demonstrate the exploration benefits of posterior sampling in MDPs.
NTC-KWS: Noise-aware CTC for Robust Keyword Spotting
Dec 17, 2024



In recent years, there has been a growing interest in designing small-footprint yet effective Connectionist Temporal Classification based keyword spotting (CTC-KWS) systems. They are typically deployed on low-resource computing platforms, where limitations on model size and computational capacity create bottlenecks under complicated acoustic scenarios. Such constraints often result in overfitting and confusion between keywords and background noise, leading to high false alarms. To address these issues, we propose a noise-aware CTC-based KWS (NTC-KWS) framework designed to enhance model robustness in noisy environments, particularly under extremely low signal-to-noise ratios. Our approach introduces two additional noise-modeling wildcard arcs into the training and decoding processes based on weighted finite state transducer (WFST) graphs: self-loop arcs to address noise insertion errors and bypass arcs to handle masking and interference caused by excessive noise. Experiments on clean and noisy Hey Snips show that NTC-KWS outperforms state-of-the-art (SOTA) end-to-end systems and CTC-KWS baselines across various acoustic conditions, with particularly strong performance in low SNR scenarios.
RN-SDEs: Limited-Angle CT Reconstruction with Residual Null-Space Diffusion Stochastic Differential Equations
Sep 20, 2024Computed tomography is a widely used imaging modality with applications ranging from medical imaging to material analysis. One major challenge arises from the lack of scanning information at certain angles, leading to distorted CT images with artifacts. This results in an ill-posed problem known as the Limited Angle Computed Tomography (LACT) reconstruction problem. To address this problem, we propose Residual Null-Space Diffusion Stochastic Differential Equations (RN-SDEs), which are a variant of diffusion models that characterize the diffusion process with mean-reverting (MR) stochastic differential equations. To demonstrate the generalizability of RN-SDEs, our experiments are conducted on two different LACT datasets, i.e., ChromSTEM and C4KC-KiTS. Through extensive experiments, we show that by leveraging learned Mean-Reverting SDEs as a prior and emphasizing data consistency using Range-Null Space Decomposition (RNSD) based rectification, RN-SDEs can restore high-quality images from severe degradation and achieve state-of-the-art performance in most LACT tasks. Additionally, we present a quantitative comparison of computational complexity and runtime efficiency, highlighting the superior effectiveness of our proposed approach.
BitDistiller: Unleashing the Potential of Sub-4-Bit LLMs via Self-Distillation
Feb 16, 2024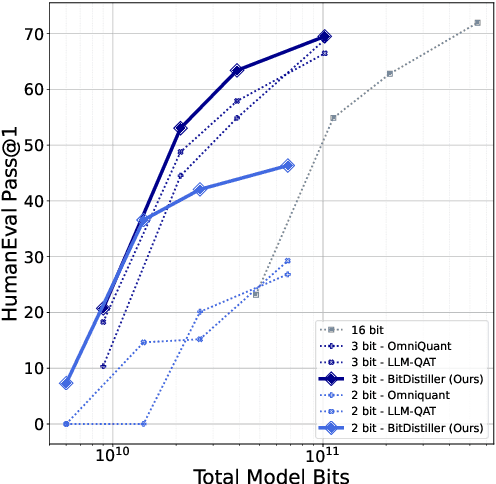
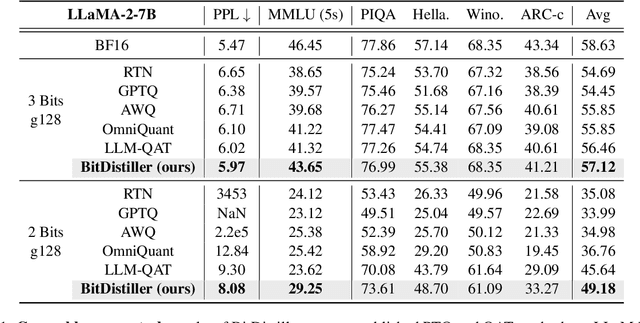

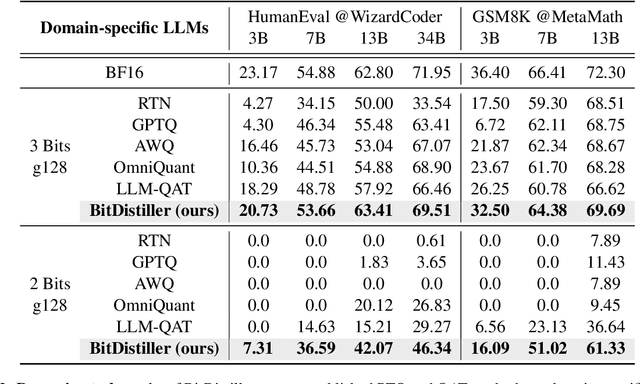
The upscaling of Large Language Models (LLMs) has yielded impressive advances in natural language processing, yet it also poses significant deployment challenges. Weight quantization has emerged as a widely embraced solution to reduce memory and computational demands. This paper introduces BitDistiller, a framework that synergizes Quantization-Aware Training (QAT) with Knowledge Distillation (KD) to boost the performance of LLMs at ultra-low precisions (sub-4-bit). Specifically, BitDistiller first incorporates a tailored asymmetric quantization and clipping technique to maximally preserve the fidelity of quantized weights, and then proposes a novel Confidence-Aware Kullback-Leibler Divergence (CAKLD) objective, which is employed in a self-distillation manner to enable faster convergence and superior model performance. Empirical evaluations demonstrate that BitDistiller significantly surpasses existing methods in both 3-bit and 2-bit configurations on general language understanding and complex reasoning benchmarks. Notably, BitDistiller is shown to be more cost-effective, demanding fewer data and training resources. The code is available at https://github.com/DD-DuDa/BitDistiller.