 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Limited-Angle CT Reconstruction Through Diffusion-Based Sinogram Completion
May 26, 2025Limited Angle Computed Tomography (LACT) often faces significant challenges due to missing angular information. Unlike previous methods that operate in the image domain, we propose a new method that focuses on sinogram inpainting. We leverage MR-SDEs, a variant of diffusion models that characterize the diffusion process with mean-reverting stochastic differential equations, to fill in missing angular data at the projection level. Furthermore, by combining distillation with constraining the output of the model using the pseudo-inverse of the inpainting matrix, the diffusion process is accelerated and done in a step, enabling efficient and accurate sinogram completion. A subsequent post-processing module back-projects the inpainted sinogram into the image domain and further refines the reconstruction, effectively suppressing artifacts while preserving critical structural details. Quantitative experimental results demonstrate that the proposed method achieves state-of-the-art performance in both perceptual and fidelity quality, offering a promising solution for LACT reconstruction in scientific and clinical applications.
RN-SDEs: Limited-Angle CT Reconstruction with Residual Null-Space Diffusion Stochastic Differential Equations
Sep 20, 2024Computed tomography is a widely used imaging modality with applications ranging from medical imaging to material analysis. One major challenge arises from the lack of scanning information at certain angles, leading to distorted CT images with artifacts. This results in an ill-posed problem known as the Limited Angle Computed Tomography (LACT) reconstruction problem. To address this problem, we propose Residual Null-Space Diffusion Stochastic Differential Equations (RN-SDEs), which are a variant of diffusion models that characterize the diffusion process with mean-reverting (MR) stochastic differential equations. To demonstrate the generalizability of RN-SDEs, our experiments are conducted on two different LACT datasets, i.e., ChromSTEM and C4KC-KiTS. Through extensive experiments, we show that by leveraging learned Mean-Reverting SDEs as a prior and emphasizing data consistency using Range-Null Space Decomposition (RNSD) based rectification, RN-SDEs can restore high-quality images from severe degradation and achieve state-of-the-art performance in most LACT tasks. Additionally, we present a quantitative comparison of computational complexity and runtime efficiency, highlighting the superior effectiveness of our proposed approach.
VDPI: Video Deblurring with Pseudo-inverse Modeling
Sep 01, 2024



Video deblurring is a challenging task that aims to recover sharp sequences from blur and noisy observations. The image-formation model plays a crucial role in traditional model-based methods, constraining the possible solutions. However, this is only the case for some deep learning-based methods. Despite deep-learning models achieving better results, traditional model-based methods remain widely popular due to their flexibility. An increasing number of scholars combine the two to achieve better deblurring performance. This paper proposes introducing knowledge of the image-formation model into a deep learning network by using the pseudo-inverse of the blur. We use a deep network to fit the blurring and estimate pseudo-inverse. Then, we use this estimation, combined with a variational deep-learning network, to deblur the video sequence. Notably, our experimental results demonstrate that such modifications can significantly improve the performance of deep learning models for video deblurring. Furthermore, our experiments on different datasets achieved notable performance improvements, proving that our proposed method can generalize to different scenarios and cameras.
Self-Supervised Fine-tuning for Image Enhancement of Super-Resolution Deep Neural Networks
Dec 30, 2019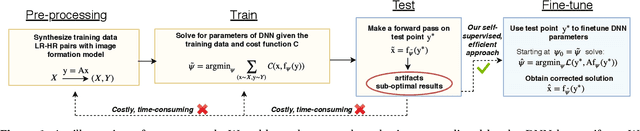



While Deep Neural Networks (DNNs) trained for image and video super-resolution regularly achieve new state-of-the-art performance, they also suffer from significant drawbacks. One of their limitations is their tendency to generate strong artifacts in their solution. This may occur when the low-resolution image formation model does not match that seen during training. Artifacts also regularly arise when training Generative Adversarial Networks for inverse imaging problems. In this paper, we propose an efficient, fully self-supervised approach to remove the observed artifacts. More specifically, at test time, given an image and its known image formation model, we fine-tune the parameters of the trained network and iteratively update them using a data consistency loss. We apply our method to image and video super-resolution neural networks and show that our proposed framework consistently enhances the solution originally provided by the neural network.