 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Method to Incorporate Spatial Information into Loss Functions for GAN-based Super-resolution Models
Mar 15, 2024

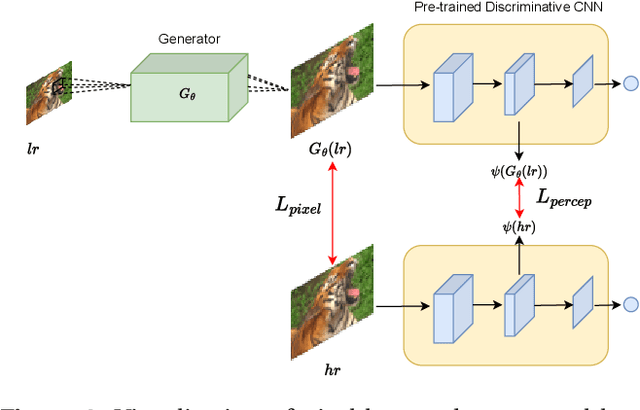
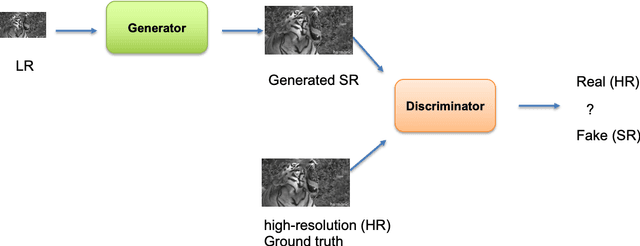
Generative Adversarial Networks (GANs) have shown great performance on super-resolution problems since they can generate more visually realistic images and video frames. However, these models often introduce side effects into the outputs, such as unexpected artifacts and noises. To reduce these artifacts and enhance the perceptual quality of the results, in this paper, we propose a general method that can be effectively used in most GAN-based super-resolution (SR) models by introducing essential spatial information into the training process. We extract spatial information from the input data and incorporate it into the training loss, making the corresponding loss a spatially adaptive (SA) one. After that, we utilize it to guide the training process. We will show that the proposed approach is independent of the methods used to extract the spatial information and independent of the SR tasks and models. This method consistently guides the training process towards generating visually pleasing SR images and video frames, substantially mitigating artifacts and noise, ultimately leading to enhanced perceptual quality.
Self-Supervised Fine-tuning for Image Enhancement of Super-Resolution Deep Neural Networks
Dec 30, 2019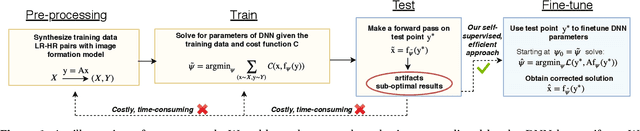



While Deep Neural Networks (DNNs) trained for image and video super-resolution regularly achieve new state-of-the-art performance, they also suffer from significant drawbacks. One of their limitations is their tendency to generate strong artifacts in their solution. This may occur when the low-resolution image formation model does not match that seen during training. Artifacts also regularly arise when training Generative Adversarial Networks for inverse imaging problems. In this paper, we propose an efficient, fully self-supervised approach to remove the observed artifacts. More specifically, at test time, given an image and its known image formation model, we fine-tune the parameters of the trained network and iteratively update them using a data consistency loss. We apply our method to image and video super-resolution neural networks and show that our proposed framework consistently enhances the solution originally provided by the neural network.
A Single Video Super-Resolution GAN for Multiple Downsampling Operators based on Pseudo-Inverse Image Formation Models
Jul 02, 2019


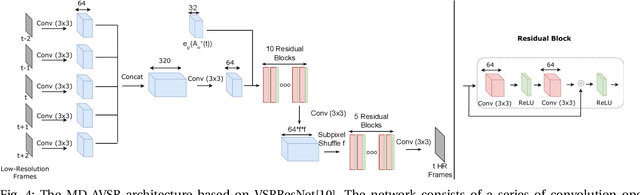
The popularity of high and ultra-high definition displays has led to the need for methods to improve the quality of videos already obtained at much lower resolutions. Current Video Super-Resolution methods are not robust to mismatch between training and testing degradation models since they are trained against a single degradation model (usually bicubic downsampling). This causes their performance to deteriorate in real-life applications. At the same time, the use of only the Mean Squared Error during learning causes the resulting images to be too smooth. In this work we propose a new Convolutional Neural Network for video super resolution which is robust to multiple degradation models. During training, which is performed on a large dataset of scenes with slow and fast motions, it uses the pseudo-inverse image formation model as part of the network architecture in conjunction with perceptual losses, in addition to a smoothness constraint that eliminates the artifacts originating from these perceptual losses. The experimental validation shows that our approach outperforms current state-of-the-art methods and is robust to multiple degradations.
Generative Adversarial Networks and Perceptual Losses for Video Super-Resolution
Jun 14, 2018



Video super-resolution has become one of the most critical problems in video processing. In the deep learning literature, recent works have shown the benefits of using perceptual losses to improve the performance on various image restoration tasks; however, these have yet to be applied for video super-resolution. In this work, we present the use of a very deep residual neural network, VSRResNet, for performing high-quality video super-resolution. We show that VSRResNet surpasses the current state-of-the-art VSR model, when compared with the PSNR/SSIM metric across most scale factors. Furthermore, we train this architecture with a convex combination of adversarial, feature-space and pixel-space loss to obtain the VSRResFeatGAN model. Finally, we compare the resulting VSR model with current state-of-the-art models using the PSNR, SSIM, and a novel perceptual distance metric, the PercepDist metric. With this latter metric, we show that the VSRResFeatGAN outperforms current state-of-the-art SR models, both quantitatively and qualitatively.