 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Image Restoration via Progressive PDE Integration
Nov 09, 2025Motion blur, caused by relative movement between camera and scene during exposure, significantly degrades image quality and impairs downstream computer vision tasks such as object detection, tracking, and recognition in dynamic environments. While deep learning-based motion deblurring methods have achieved remarkable progress, existing approaches face fundamental challenges in capturing the long-range spatial dependencies inherent in motion blur patterns. Traditional convolutional methods rely on limited receptive fields and require extremely deep networks to model global spatial relationships. These limitations motivate the need for alternative approaches that incorporate physical priors to guide feature evolution during restoration. In this paper, we propose a progressive training framework that integrates physics-informed PDE dynamics into state-of-the-art restoration architectures. By leveraging advection-diffusion equations to model feature evolution, our approach naturally captures the directional flow characteristics of motion blur while enabling principled global spatial modeling. Our PDE-enhanced deblurring models achieve superior restoration quality with minimal overhead, adding only approximately 1\% to inference GMACs while providing consistent improvements in perceptual quality across multiple state-of-the-art architectures. Comprehensive experiments on standard motion deblurring benchmarks demonstrate that our physics-informed approach improves PSNR and SSIM significantly across four diverse architectures, including FFTformer, NAFNet, Restormer, and Stripformer. These results validate that incorporating mathematical physics principles through PDE-based global layers can enhance deep learning-based image restoration, establishing a promising direction for physics-informed neural network design in computer vision applications.
ScarNet: A Novel Foundation Model for Automated Myocardial Scar Quantification from LGE in Cardiac MRI
Jan 02, 2025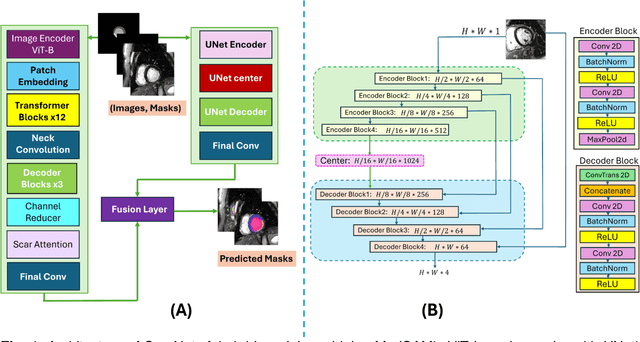
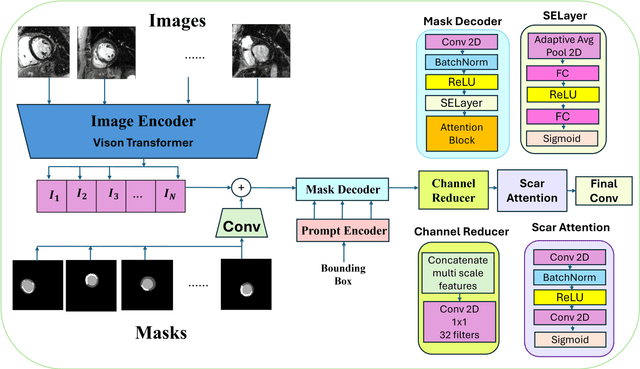
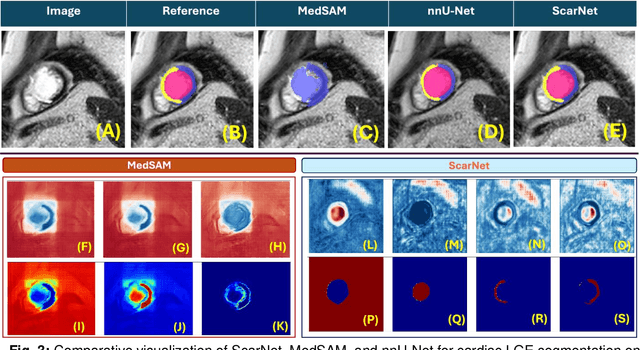
Background: Late Gadolinium Enhancement (LGE) imaging is the gold standard for assessing myocardial fibrosis and scarring, with left ventricular (LV) LGE extent predicting major adverse cardiac events (MACE). Despite its importance, routine LGE-based LV scar quantification is hindered by labor-intensive manual segmentation and inter-observer variability. Methods: We propose ScarNet, a hybrid model combining a transformer-based encoder from the Medical Segment Anything Model (MedSAM) with a convolution-based U-Net decoder, enhanced by tailored attention blocks. ScarNet was trained on 552 ischemic cardiomyopathy patients with expert segmentations of myocardial and scar boundaries and tested on 184 separate patients. Results: ScarNet achieved robust scar segmentation in 184 test patients, yielding a median Dice score of 0.912 (IQR: 0.863--0.944), significantly outperforming MedSAM (median Dice = 0.046, IQR: 0.043--0.047) and nnU-Net (median Dice = 0.638, IQR: 0.604--0.661). ScarNet demonstrated lower bias (-0.63%) and coefficient of variation (4.3%) compared to MedSAM (bias: -13.31%, CoV: 130.3%) and nnU-Net (bias: -2.46%, CoV: 20.3%). In Monte Carlo simulations with noise perturbations, ScarNet achieved significantly higher scar Dice (0.892 \pm 0.053, CoV = 5.9%) than MedSAM (0.048 \pm 0.112, CoV = 233.3%) and nnU-Net (0.615 \pm 0.537, CoV = 28.7%). Conclusion: ScarNet outperformed MedSAM and nnU-Net in accurately segmenting myocardial and scar boundaries in LGE images. The model exhibited robust performance across diverse image qualities and scar patterns.
DRL-STNet: Unsupervised Domain Adaptation for Cross-modality Medical Image Segmentation via Disentangled Representation Learning
Sep 26, 2024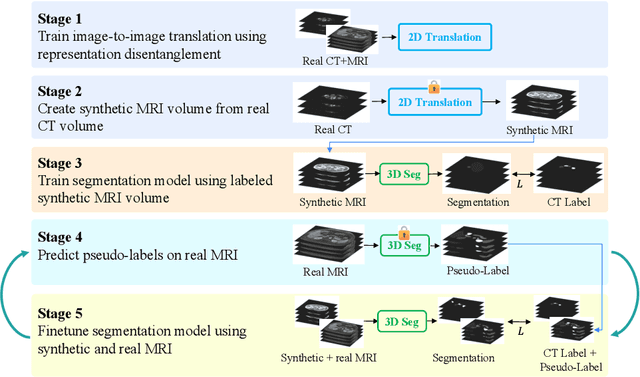

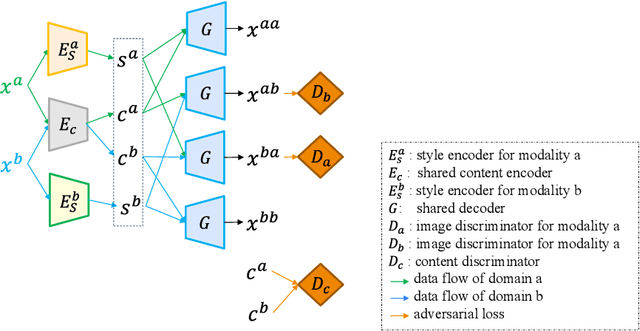
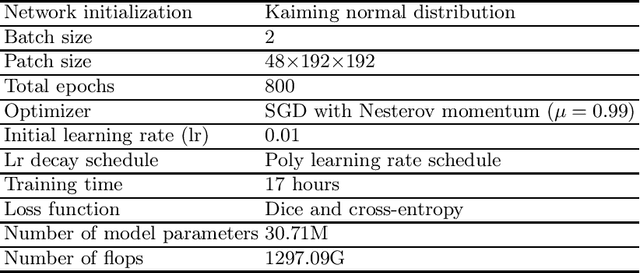
Unsupervised domain adaptation (UDA) is essential for medical image segmentation, especially in cross-modality data scenarios. UDA aims to transfer knowledge from a labeled source domain to an unlabeled target domain, thereby reducing the dependency on extensive manual annotations. This paper presents DRL-STNet, a novel framework for cross-modality medical image segmentation that leverages generative adversarial networks (GANs), disentangled representation learning (DRL), and self-training (ST). Our method leverages DRL within a GAN to translate images from the source to the target modality. Then, the segmentation model is initially trained with these translated images and corresponding source labels and then fine-tuned iteratively using a combination of synthetic and real images with pseudo-labels and real labels. The proposed framework exhibits superior performance in abdominal organ segmentation on the FLARE challenge dataset, surpassing state-of-the-art methods by 11.4% in the Dice similarity coefficient and by 13.1% in the Normalized Surface Dice metric, achieving scores of 74.21% and 80.69%, respectively. The average running time is 41 seconds, and the area under the GPU memory-time curve is 11,292 MB. These results indicate the potential of DRL-STNet for enhancing cross-modality medical image segmentation tasks.
A General Method to Incorporate Spatial Information into Loss Functions for GAN-based Super-resolution Models
Mar 15, 2024

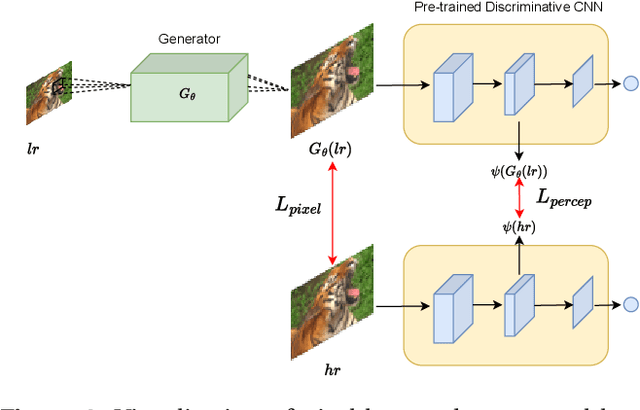
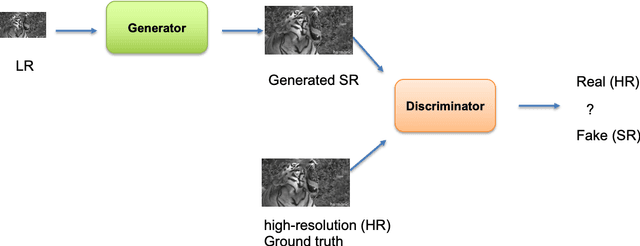
Generative Adversarial Networks (GANs) have shown great performance on super-resolution problems since they can generate more visually realistic images and video frames. However, these models often introduce side effects into the outputs, such as unexpected artifacts and noises. To reduce these artifacts and enhance the perceptual quality of the results, in this paper, we propose a general method that can be effectively used in most GAN-based super-resolution (SR) models by introducing essential spatial information into the training process. We extract spatial information from the input data and incorporate it into the training loss, making the corresponding loss a spatially adaptive (SA) one. After that, we utilize it to guide the training process. We will show that the proposed approach is independent of the methods used to extract the spatial information and independent of the SR tasks and models. This method consistently guides the training process towards generating visually pleasing SR images and video frames, substantially mitigating artifacts and noise, ultimately leading to enhanced perceptual quality.
Real-World Atmospheric Turbulence Correction via Domain Adaptation
Feb 12, 2024



Atmospheric turbulence, a common phenomenon in daily life, is primarily caused by the uneven heating of the Earth's surface. This phenomenon results in distorted and blurred acquired images or videos and can significantly impact downstream vision tasks, particularly those that rely on capturing clear, stable images or videos from outdoor environments, such as accurately detecting or recognizing objects. Therefore, people have proposed ways to simulate atmospheric turbulence and designed effective deep learning-based methods to remove the atmospheric turbulence effect. However, these synthesized turbulent images can not cover all the range of real-world turbulence effects. Though the models have achieved great performance for synthetic scenarios, there always exists a performance drop when applied to real-world cases. Moreover, reducing real-world turbulence is a more challenging task as there are no clean ground truth counterparts provided to the models during training. In this paper, we propose a real-world atmospheric turbulence mitigation model under a domain adaptation framework, which links the supervised simulated atmospheric turbulence correction with the unsupervised real-world atmospheric turbulence correction. We will show our proposed method enhances performance in real-world atmospheric turbulence scenarios, improving both image quality and downstream vision tasks.
Atmospheric Turbulence Correction via Variational Deep Diffusion
May 08, 2023



Atmospheric Turbulence (AT) correction is a challenging restoration task as it consists of two distortions: geometric distortion and spatially variant blur. Diffusion models have shown impressive accomplishments in photo-realistic image synthesis and beyond. In this paper, we propose a novel deep conditional diffusion model under a variational inference framework to solve the AT correction problem. We use this framework to improve performance by learning latent prior information from the input and degradation processes. We use the learned information to further condition the diffusion model. Experiments are conducted in a comprehensive synthetic AT dataset. We show that the proposed framework achieves good quantitative and qualitative results.
Fast and Robust Cascade Model for Multiple Degradation Single Image Super-Resolution
Nov 16, 2020
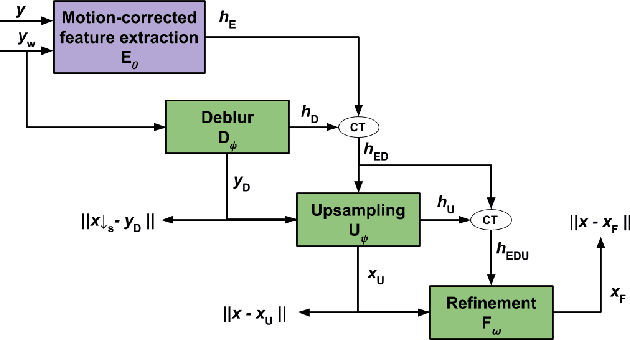

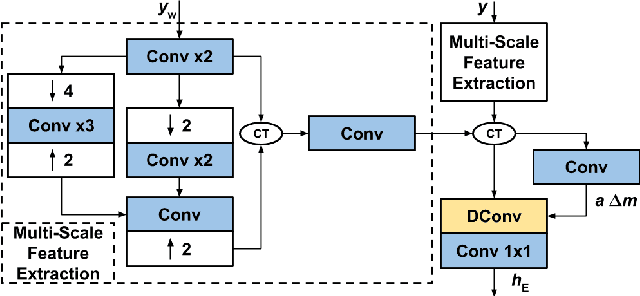
Single Image Super-Resolution (SISR) is one of the low-level computer vision problems that has received increased attention in the last few years. Current approaches are primarily based on harnessing the power of deep learning models and optimization techniques to reverse the degradation model. Owing to its hardness, isotropic blurring or Gaussians with small anisotropic deformations have been mainly considered. Here, we widen this scenario by including large non-Gaussian blurs that arise in real camera movements. Our approach leverages the degradation model and proposes a new formulation of the Convolutional Neural Network (CNN) cascade model, where each network sub-module is constrained to solve a specific degradation: deblurring or upsampling. A new densely connected CNN-architecture is proposed where the output of each sub-module is restricted using some external knowledge to focus it on its specific task. As far we know this use of domain-knowledge to module-level is a novelty in SISR. To fit the finest model, a final sub-module takes care of the residual errors propagated by the previous sub-modules. We check our model with three state of the art (SOTA) datasets in SISR and compare the results with the SOTA models. The results show that our model is the only one able to manage our wider set of deformations. Furthermore, our model overcomes all current SOTA methods for a standard set of deformations. In terms of computational load, our model also improves on the two closest competitors in terms of efficiency. Although the approach is non-blind and requires an estimation of the blur kernel, it shows robustness to blur kernel estimation errors, making it a good alternative to blind models.
A Single Video Super-Resolution GAN for Multiple Downsampling Operators based on Pseudo-Inverse Image Formation Models
Jul 02, 2019


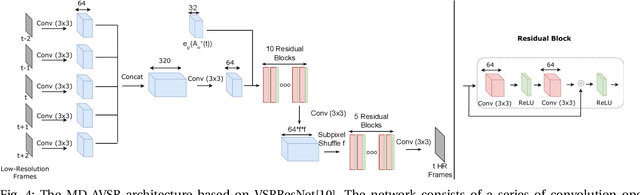
The popularity of high and ultra-high definition displays has led to the need for methods to improve the quality of videos already obtained at much lower resolutions. Current Video Super-Resolution methods are not robust to mismatch between training and testing degradation models since they are trained against a single degradation model (usually bicubic downsampling). This causes their performance to deteriorate in real-life applications. At the same time, the use of only the Mean Squared Error during learning causes the resulting images to be too smooth. In this work we propose a new Convolutional Neural Network for video super resolution which is robust to multiple degradation models. During training, which is performed on a large dataset of scenes with slow and fast motions, it uses the pseudo-inverse image formation model as part of the network architecture in conjunction with perceptual losses, in addition to a smoothness constraint that eliminates the artifacts originating from these perceptual losses. The experimental validation shows that our approach outperforms current state-of-the-art methods and is robust to multiple degradations.