 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScarNet: A Novel Foundation Model for Automated Myocardial Scar Quantification from LGE in Cardiac MRI
Jan 02, 2025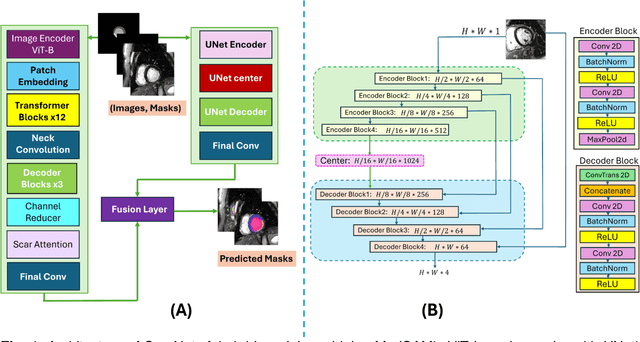
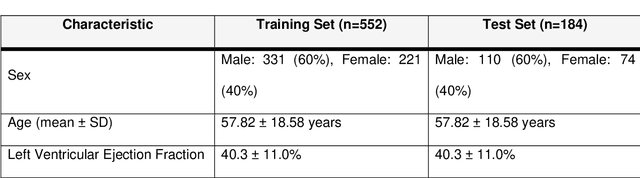
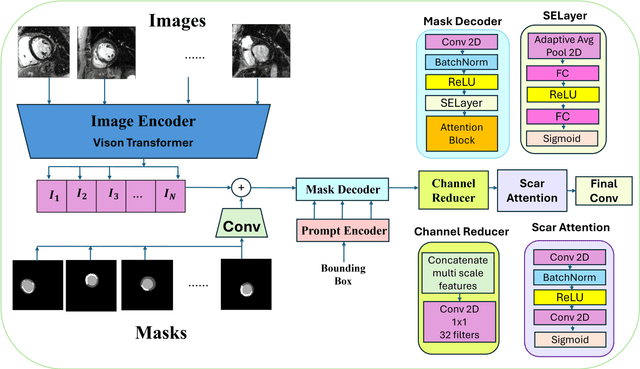
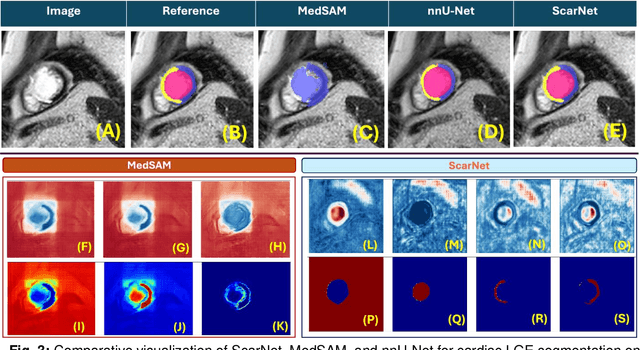
Background: Late Gadolinium Enhancement (LGE) imaging is the gold standard for assessing myocardial fibrosis and scarring, with left ventricular (LV) LGE extent predicting major adverse cardiac events (MACE). Despite its importance, routine LGE-based LV scar quantification is hindered by labor-intensive manual segmentation and inter-observer variability. Methods: We propose ScarNet, a hybrid model combining a transformer-based encoder from the Medical Segment Anything Model (MedSAM) with a convolution-based U-Net decoder, enhanced by tailored attention blocks. ScarNet was trained on 552 ischemic cardiomyopathy patients with expert segmentations of myocardial and scar boundaries and tested on 184 separate patients. Results: ScarNet achieved robust scar segmentation in 184 test patients, yielding a median Dice score of 0.912 (IQR: 0.863--0.944), significantly outperforming MedSAM (median Dice = 0.046, IQR: 0.043--0.047) and nnU-Net (median Dice = 0.638, IQR: 0.604--0.661). ScarNet demonstrated lower bias (-0.63%) and coefficient of variation (4.3%) compared to MedSAM (bias: -13.31%, CoV: 130.3%) and nnU-Net (bias: -2.46%, CoV: 20.3%). In Monte Carlo simulations with noise perturbations, ScarNet achieved significantly higher scar Dice (0.892 \pm 0.053, CoV = 5.9%) than MedSAM (0.048 \pm 0.112, CoV = 233.3%) and nnU-Net (0.615 \pm 0.537, CoV = 28.7%). Conclusion: ScarNet outperformed MedSAM and nnU-Net in accurately segmenting myocardial and scar boundaries in LGE images. The model exhibited robust performance across diverse image qualities and scar patterns.
2-Step Sparse-View CT Reconstruction with a Domain-Specific Perceptual Network
Dec 08, 2020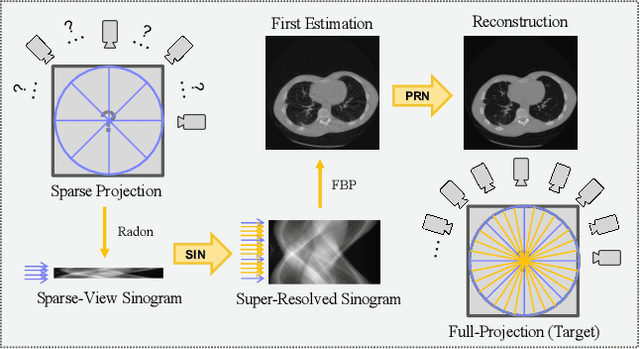
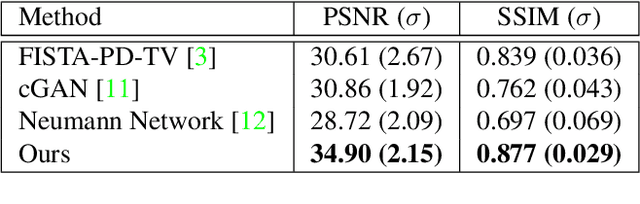
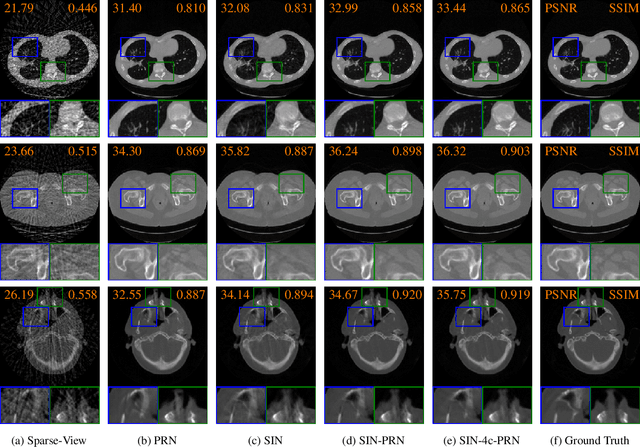
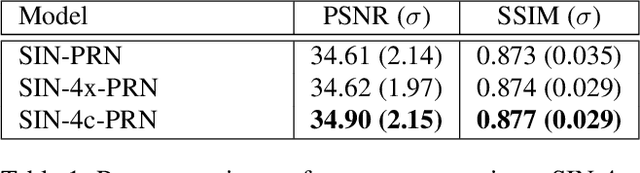
Computed tomography is widely used to examine internal structures in a non-destructive manner. To obtain high-quality reconstructions, one typically has to acquire a densely sampled trajectory to avoid angular undersampling. However, many scenarios require a sparse-view measurement leading to streak-artifacts if unaccounted for. Current methods do not make full use of the domain-specific information, and hence fail to provide reliable reconstructions for highly undersampled data. We present a novel framework for sparse-view tomography by decoupling the reconstruction into two steps: First, we overcome its ill-posedness using a super-resolution network, SIN, trained on the sparse projections. The intermediate result allows for a closed-form tomographic reconstruction with preserved details and highly reduced streak-artifacts. Second, a refinement network, PRN, trained on the reconstructions reduces any remaining artifacts. We further propose a light-weight variant of the perceptual-loss that enhances domain-specific information, boosting restoration accuracy. Our experiments demonstrate an improvement over current solutions by 4 dB.