 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterVid: Counterfactual Video Generation for Mitigating Action and Temporal Hallucinations in Video-Language Models
Jan 08, 2026Video-language models (VLMs) achieve strong multimodal understanding but remain prone to hallucinations, especially when reasoning about actions and temporal order. Existing mitigation strategies, such as textual filtering or random video perturbations, often fail to address the root cause: over-reliance on language priors rather than fine-grained visual dynamics. We propose a scalable framework for counterfactual video generation that synthesizes videos differing only in actions or temporal structure while preserving scene context. Our pipeline combines multimodal LLMs for action proposal and editing guidance with diffusion-based image and video models to generate semantic hard negatives at scale. Using this framework, we build CounterVid, a synthetic dataset of ~26k preference pairs targeting action recognition and temporal reasoning. We further introduce MixDPO, a unified Direct Preference Optimization approach that jointly leverages textual and visual preferences. Fine-tuning Qwen2.5-VL with MixDPO yields consistent improvements, notably in temporal ordering, and transfers effectively to standard video hallucination benchmarks. Code and models will be made publicly available.
What Happens Next? Next Scene Prediction with a Unified Video Model
Dec 15, 2025



Recent unified models for joint understanding and generation have significantly advanced visual generation capabilities. However, their focus on conventional tasks like text-to-video generation has left the temporal reasoning potential of unified models largely underexplored. To address this gap, we introduce Next Scene Prediction (NSP), a new task that pushes unified video models toward temporal and causal reasoning. Unlike text-to-video generation, NSP requires predicting plausible futures from preceding context, demanding deeper understanding and reasoning. To tackle this task, we propose a unified framework combining Qwen-VL for comprehension and LTX for synthesis, bridged by a latent query embedding and a connector module. This model is trained in three stages on our newly curated, large-scale NSP dataset: text-to-video pre-training, supervised fine-tuning, and reinforcement learning (via GRPO) with our proposed causal consistency reward. Experiments demonstrate our model achieves state-of-the-art performance on our benchmark, advancing the capability of generalist multimodal systems to anticipate what happens next.
ScarNet: A Novel Foundation Model for Automated Myocardial Scar Quantification from LGE in Cardiac MRI
Jan 02, 2025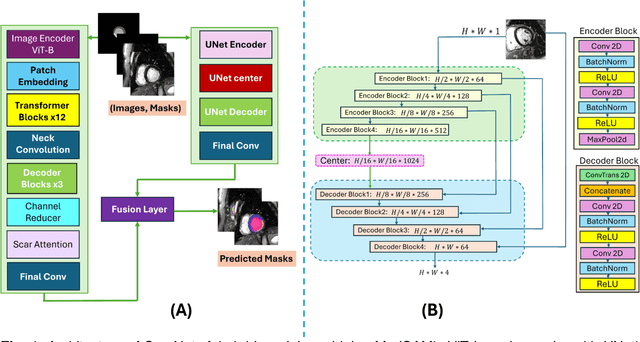
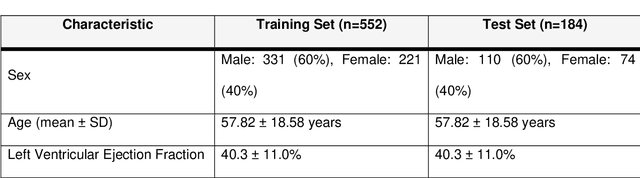
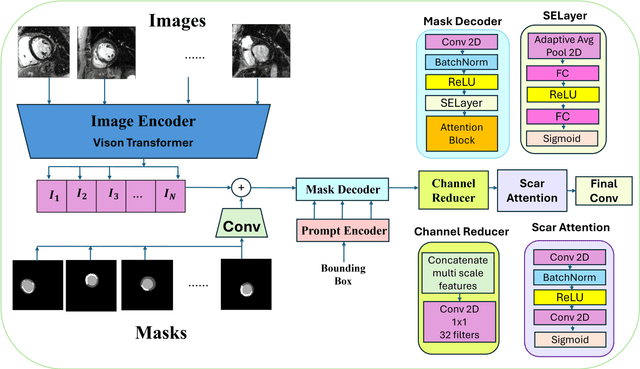
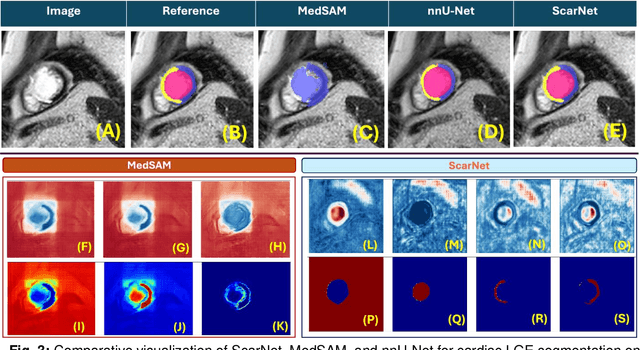
Background: Late Gadolinium Enhancement (LGE) imaging is the gold standard for assessing myocardial fibrosis and scarring, with left ventricular (LV) LGE extent predicting major adverse cardiac events (MACE). Despite its importance, routine LGE-based LV scar quantification is hindered by labor-intensive manual segmentation and inter-observer variability. Methods: We propose ScarNet, a hybrid model combining a transformer-based encoder from the Medical Segment Anything Model (MedSAM) with a convolution-based U-Net decoder, enhanced by tailored attention blocks. ScarNet was trained on 552 ischemic cardiomyopathy patients with expert segmentations of myocardial and scar boundaries and tested on 184 separate patients. Results: ScarNet achieved robust scar segmentation in 184 test patients, yielding a median Dice score of 0.912 (IQR: 0.863--0.944), significantly outperforming MedSAM (median Dice = 0.046, IQR: 0.043--0.047) and nnU-Net (median Dice = 0.638, IQR: 0.604--0.661). ScarNet demonstrated lower bias (-0.63%) and coefficient of variation (4.3%) compared to MedSAM (bias: -13.31%, CoV: 130.3%) and nnU-Net (bias: -2.46%, CoV: 20.3%). In Monte Carlo simulations with noise perturbations, ScarNet achieved significantly higher scar Dice (0.892 \pm 0.053, CoV = 5.9%) than MedSAM (0.048 \pm 0.112, CoV = 233.3%) and nnU-Net (0.615 \pm 0.537, CoV = 28.7%). Conclusion: ScarNet outperformed MedSAM and nnU-Net in accurately segmenting myocardial and scar boundaries in LGE images. The model exhibited robust performance across diverse image qualities and scar patterns.
HoloChrome: Polychromatic Illumination for Speckle Reduction in Holographic Near-Eye Displays
Oct 31, 2024Holographic displays hold the promise of providing authentic depth cues, resulting in enhanced immersive visual experiences for near-eye applications. However, current holographic displays are hindered by speckle noise, which limits accurate reproduction of color and texture in displayed images. We present HoloChrome, a polychromatic holographic display framework designed to mitigate these limitations. HoloChrome utilizes an ultrafast, wavelength-adjustable laser and a dual-Spatial Light Modulator (SLM) architecture, enabling the multiplexing of a large set of discrete wavelengths across the visible spectrum. By leveraging spatial separation in our dual-SLM setup, we independently manipulate speckle patterns across multiple wavelengths. This novel approach effectively reduces speckle noise through incoherent averaging achieved by wavelength multiplexing. Our method is complementary to existing speckle reduction techniques, offering a new pathway to address this challenge. Furthermore, the use of polychromatic illumination broadens the achievable color gamut compared to traditional three-color primary holographic displays. Our simulations and tabletop experiments validate that HoloChrome significantly reduces speckle noise and expands the color gamut. These advancements enhance the performance of holographic near-eye displays, moving us closer to practical, immersive next-generation visual experiences.
Practical High-Contrast Holography
Oct 25, 2024Holographic displays are a promising technology for immersive visual experiences, and their potential for compact form factor makes them a strong candidate for head-mounted displays. However, at the short propagation distances needed for a compact, head-mounted architecture, image contrast is low when using a traditional phase-only spatial light modulator (SLM). Although a complex SLM could restore contrast, these modulators require bulky lenses to optically co-locate the amplitude and phase components, making them poorly suited for a compact head-mounted design. In this work, we introduce a novel architecture to improve contrast: by adding a low resolution amplitude SLM a short distance away from the phase modulator, we demonstrate peak signal-to-noise ratio improvement up to 31 dB in simulation compared to phase-only, even when the amplitude modulator is 60$\times$ lower resolution than its phase counterpart. We analyze the relationship between diffraction angle and amplitude modulator pixel size, and validate the concept with a benchtop experimental prototype. By showing that low resolution modulation is sufficient to improve contrast, we pave the way towards practical high-contrast holography in a compact form factor.
DRL-STNet: Unsupervised Domain Adaptation for Cross-modality Medical Image Segmentation via Disentangled Representation Learning
Sep 26, 2024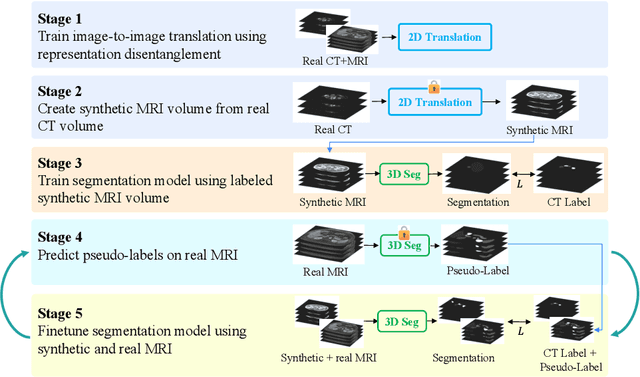

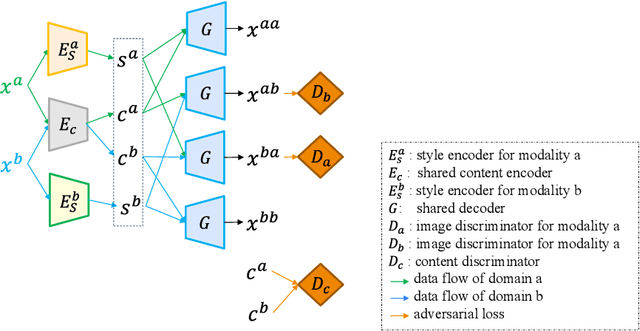
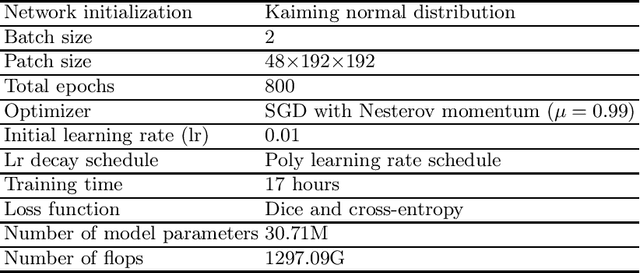
Unsupervised domain adaptation (UDA) is essential for medical image segmentation, especially in cross-modality data scenarios. UDA aims to transfer knowledge from a labeled source domain to an unlabeled target domain, thereby reducing the dependency on extensive manual annotations. This paper presents DRL-STNet, a novel framework for cross-modality medical image segmentation that leverages generative adversarial networks (GANs), disentangled representation learning (DRL), and self-training (ST). Our method leverages DRL within a GAN to translate images from the source to the target modality. Then, the segmentation model is initially trained with these translated images and corresponding source labels and then fine-tuned iteratively using a combination of synthetic and real images with pseudo-labels and real labels. The proposed framework exhibits superior performance in abdominal organ segmentation on the FLARE challenge dataset, surpassing state-of-the-art methods by 11.4% in the Dice similarity coefficient and by 13.1% in the Normalized Surface Dice metric, achieving scores of 74.21% and 80.69%, respectively. The average running time is 41 seconds, and the area under the GPU memory-time curve is 11,292 MB. These results indicate the potential of DRL-STNet for enhancing cross-modality medical image segmentation tasks.
Multisource Holography
Sep 19, 2023
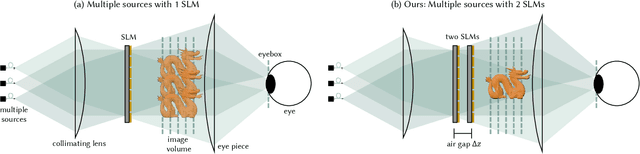
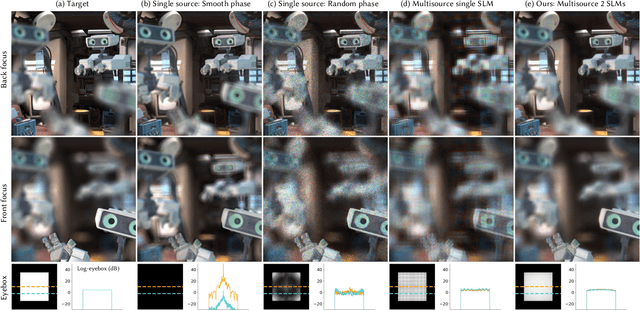
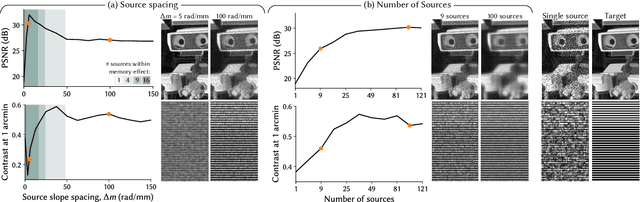
Holographic displays promise several benefits including high quality 3D imagery, accurate accommodation cues, and compact form-factors. However, holography relies on coherent illumination which can create undesirable speckle noise in the final image. Although smooth phase holograms can be speckle-free, their non-uniform eyebox makes them impractical, and speckle mitigation with partially coherent sources also reduces resolution. Averaging sequential frames for speckle reduction requires high speed modulators and consumes temporal bandwidth that may be needed elsewhere in the system. In this work, we propose multisource holography, a novel architecture that uses an array of sources to suppress speckle in a single frame without sacrificing resolution. By using two spatial light modulators, arranged sequentially, each source in the array can be controlled almost independently to create a version of the target content with different speckle. Speckle is then suppressed when the contributions from the multiple sources are averaged at the image plane. We introduce an algorithm to calculate multisource holograms, analyze the design space, and demonstrate up to a 10 dB increase in peak signal-to-noise ratio compared to an equivalent single source system. Finally, we validate the concept with a benchtop experimental prototype by producing both 2D images and focal stacks with natural defocus cues.
Stochastic Light Field Holography
Jul 12, 2023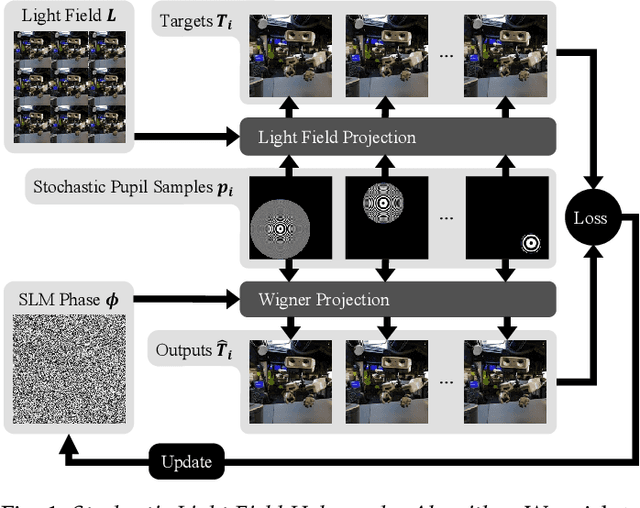


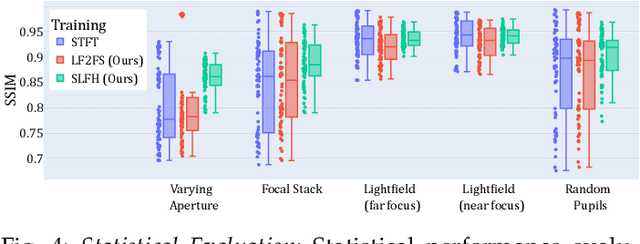
The Visual Turing Test is the ultimate goal to evaluate the realism of holographic displays. Previous studies have focused on addressing challenges such as limited \'etendue and image quality over a large focal volume, but they have not investigated the effect of pupil sampling on the viewing experience in full 3D holograms. In this work, we tackle this problem with a novel hologram generation algorithm motivated by matching the projection operators of incoherent Light Field and coherent Wigner Function light transport. To this end, we supervise hologram computation using synthesized photographs, which are rendered on-the-fly using Light Field refocusing from stochastically sampled pupil states during optimization. The proposed method produces holograms with correct parallax and focus cues, which are important for passing the Visual Turing Test. We validate that our approach compares favorably to state-of-the-art CGH algorithms that use Light Field and Focal Stack supervision. Our experiments demonstrate that our algorithm significantly improves the realism of the viewing experience for a variety of different pupil states.
medXGAN: Visual Explanations for Medical Classifiers through a Generative Latent Space
Apr 17, 2022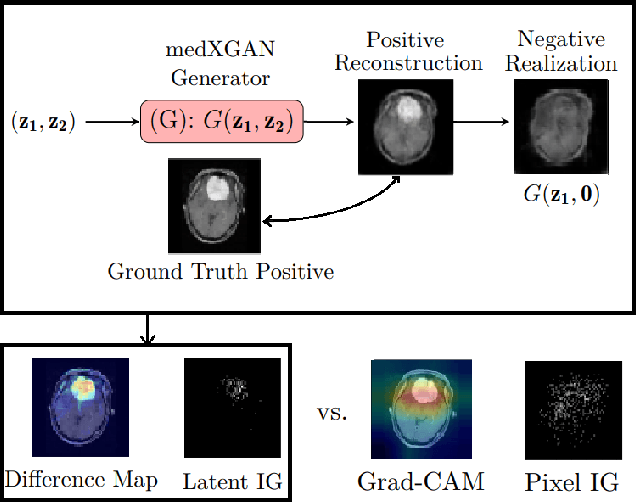

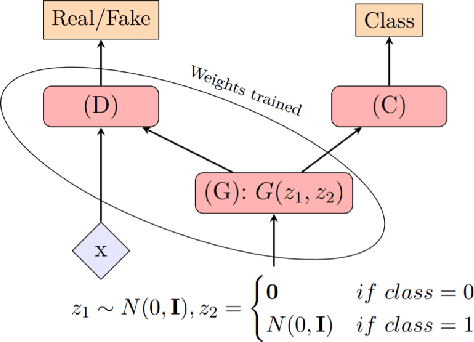

Despite the surge of deep learning in the past decade, some users are skeptical to deploy these models in practice due to their black-box nature. Specifically, in the medical space where there are severe potential repercussions, we need to develop methods to gain confidence in the models' decisions. To this end, we propose a novel medical imaging generative adversarial framework, medXGAN (medical eXplanation GAN), to visually explain what a medical classifier focuses on in its binary predictions. By encoding domain knowledge of medical images, we are able to disentangle anatomical structure and pathology, leading to fine-grained visualization through latent interpolation. Furthermore, we optimize the latent space such that interpolation explains how the features contribute to the classifier's output. Our method outperforms baselines such as Gradient-Weighted Class Activation Mapping (Grad-CAM) and Integrated Gradients in localization and explanatory ability. Additionally, a combination of the medXGAN with Integrated Gradients can yield explanations more robust to noise. The code is available at: https://avdravid.github.io/medXGAN_page/.
Investigating the Potential of Auxiliary-Classifier GANs for Image Classification in Low Data Regimes
Jan 22, 2022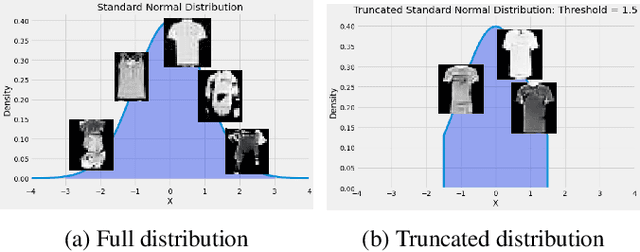
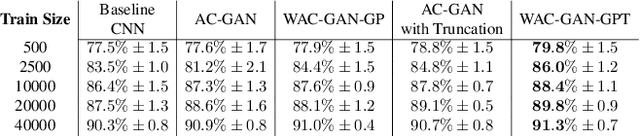
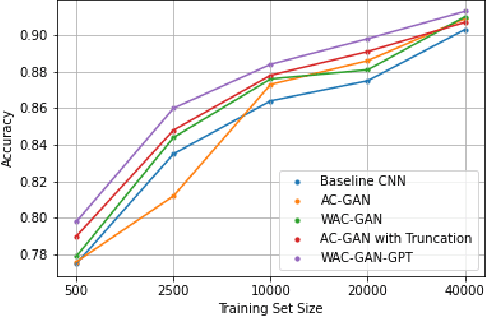

Generative Adversarial Networks (GANs) have shown promise in augmenting datasets and boosting convolutional neural networks' (CNN) performance on image classification tasks. But they introduce more hyperparameters to tune as well as the need for additional time and computational power to train supplementary to the CNN. In this work, we examine the potential for Auxiliary-Classifier GANs (AC-GANs) as a 'one-stop-shop' architecture for image classification, particularly in low data regimes. Additionally, we explore modifications to the typical AC-GAN framework, changing the generator's latent space sampling scheme and employing a Wasserstein loss with gradient penalty to stabilize the simultaneous training of image synthesis and classification. Through experiments on images of varying resolutions and complexity, we demonstrate that AC-GANs show promise in image classification, achieving competitive performance with standard CNNs. These methods can be employed as an 'all-in-one' framework with particular utility in the absence of large amounts of training data.