 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Effectiveness of Noise Pretraining for Implicit Neural Representations
Mar 30, 2026The approximation and convergence properties of implicit neural representations (INRs) are known to be highly sensitive to parameter initialization strategies. While several data-driven initialization methods demonstrate significant improvements over standard random sampling, the reasons for their success -- specifically, whether they encode classical statistical signal priors or more complex features -- remain poorly understood. In this study, we explore this phenomenon through a series of experimental analyses leveraging noise pretraining. We pretrain INRs on diverse noise classes (e.g., Gaussian, Dead Leaves, Spectral) and measure their ability to both fit unseen signals and encode priors for an inverse imaging task (denoising). Our analyses on image and video data reveal a surprising finding: simply pretraining on unstructured noise (Uniform, Gaussian) dramatically improves signal fitting capacity compared to all other baselines. However, unstructured noise also yields poor deep image priors for denoising. In contrast, we also find that noise with the classic $1/|f^α|$ spectral structure of natural images achieves an excellent balance of signal fitting and inverse imaging capabilities, performing on par with the best data-driven initialization methods. This finding enables more efficient INR training in applications lacking sufficient prior domain-specific data. For more details, visit project page at https://kushalvyas.github.io/noisepretraining.html
Demystifying Low-Rank Knowledge Distillation in Large Language Models: Convergence, Generalization, and Information-Theoretic Guarantees
Mar 22, 2026Knowledge distillation has emerged as a powerful technique for compressing large language models (LLMs) into efficient, deployable architectures while preserving their advanced capabilities. Recent advances in low-rank knowledge distillation, particularly methods like Low-Rank Clone (LRC), have demonstrated remarkable empirical success, achieving comparable performance to full-parameter distillation with significantly reduced training data and computational overhead. However, the theoretical foundations underlying these methods remain poorly understood. In this paper, we establish a rigorous theoretical framework for low-rank knowledge distillation in language models. We prove that under mild assumptions, low-rank projection preserves the optimization dynamics, yielding explicit convergence rates of $O(1/\sqrt{T})$. We derive generalization bounds that characterize the fundamental trade-off between model compression and generalization capability, showing that the generalization error scales with the rank parameter as $O(r(m+n)/\sqrt{n})$. Furthermore, we provide an information-theoretic analysis of the activation cloning mechanism, revealing its role in maximizing the mutual information between the teacher's and student's intermediate representations. Our theoretical results offer principled guidelines for rank selection, mathematically suggesting an optimal rank $r^* = O(\sqrt{n})$ where $n$ is the sample size. Experimental validation on standard language modeling benchmarks confirms our theoretical predictions, demonstrating that the empirical convergence, rank scaling, and generalization behaviors align closely with our bounds.
Autonomous Sea Turtle Robot for Marine Fieldwork
Feb 24, 2026Autonomous robots can transform how we observe marine ecosystems, but close-range operation in reefs and other cluttered habitats remains difficult. Vehicles must maneuver safely near animals and fragile structures while coping with currents, variable illumination and limited sensing. Previous approaches simplify these problems by leveraging soft materials and bioinspired swimming designs, but such platforms remain limited in terms of deployable autonomy. Here we present a sea turtle-inspired autonomous underwater robot that closed the gap between bioinspired locomotion and field-ready autonomy through a tightly integrated, vision-driven control stack. The robot combines robust depth-heading stabilization with obstacle avoidance and target-centric control, enabling it to track and interact with moving objects in complex terrain. We validate the robot in controlled pool experiments and in a live coral reef exhibit at the New England Aquarium, demonstrating stable operation and reliable tracking of fast-moving marine animals and human divers. To the best of our knowledge, this is the first integrated biomimetic robotic system, combining novel hardware, control, and field experiments, deployed to track and monitor real marine animals in their natural environment. During off-tether experiments, we demonstrate safe navigation around obstacles (91\% success rate in the aquarium exhibit) and introduce a low-compute onboard tracking mode. Together, these results establish a practical route toward soft-rigid hybrid, bioinspired underwater robots capable of minimally disruptive exploration and close-range monitoring in sensitive ecosystems.
Enhancing Self-Correction in Large Language Models through Multi-Perspective Reflection
Jan 12, 2026While Chain-of-Thought (CoT) prompting advances LLM reasoning, challenges persist in consistency, accuracy, and self-correction, especially for complex or ethically sensitive tasks. Existing single-dimensional reflection methods offer insufficient improvements. We propose MyGO Poly-Reflective Chain-of-Thought (PR-CoT), a novel methodology employing structured multi-perspective reflection. After initial CoT, PR-CoT guides the LLM to self-assess its reasoning across multiple predefined angles: logical consistency, information completeness, biases/ethics, and alternative solutions. Implemented purely via prompt engineering, this process refines the initial CoT into a more robust and accurate final answer without model retraining. Experiments across arithmetic, commonsense, ethical decision-making, and logical puzzles, using GPT-three point five and GPT-four models, demonstrate PR-CoT's superior performance. It significantly outperforms traditional CoT and existing reflection methods in logical consistency and error correction, with notable gains in nuanced domains like ethical decision-making. Ablation studies, human evaluations, and qualitative analyses further validate the contribution of each reflection perspective and the overall efficacy of our poly-reflective paradigm in fostering more reliable LLM reasoning.
Enabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
ScarNet: A Novel Foundation Model for Automated Myocardial Scar Quantification from LGE in Cardiac MRI
Jan 02, 2025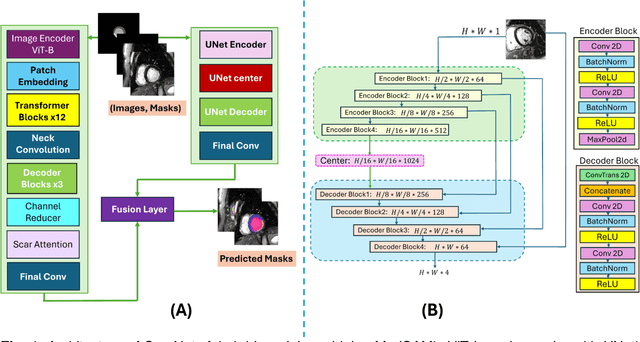
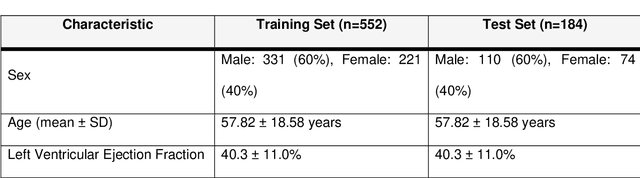
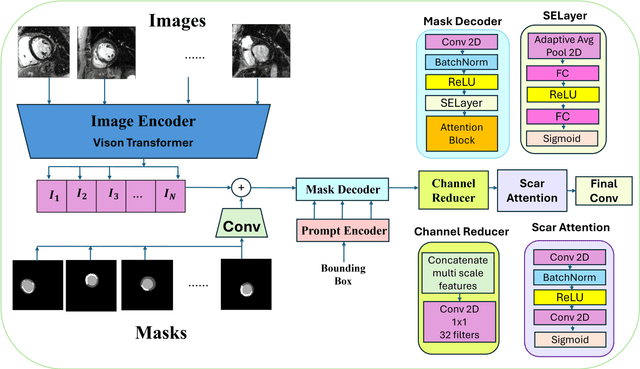
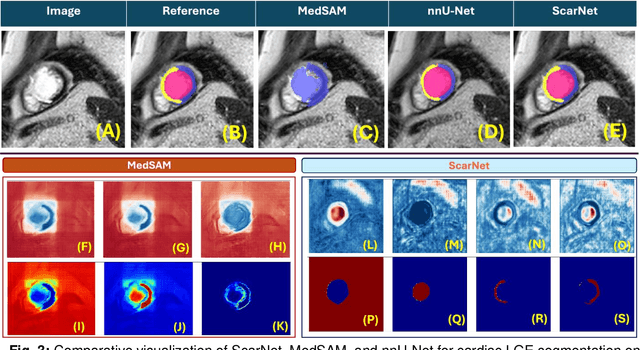
Background: Late Gadolinium Enhancement (LGE) imaging is the gold standard for assessing myocardial fibrosis and scarring, with left ventricular (LV) LGE extent predicting major adverse cardiac events (MACE). Despite its importance, routine LGE-based LV scar quantification is hindered by labor-intensive manual segmentation and inter-observer variability. Methods: We propose ScarNet, a hybrid model combining a transformer-based encoder from the Medical Segment Anything Model (MedSAM) with a convolution-based U-Net decoder, enhanced by tailored attention blocks. ScarNet was trained on 552 ischemic cardiomyopathy patients with expert segmentations of myocardial and scar boundaries and tested on 184 separate patients. Results: ScarNet achieved robust scar segmentation in 184 test patients, yielding a median Dice score of 0.912 (IQR: 0.863--0.944), significantly outperforming MedSAM (median Dice = 0.046, IQR: 0.043--0.047) and nnU-Net (median Dice = 0.638, IQR: 0.604--0.661). ScarNet demonstrated lower bias (-0.63%) and coefficient of variation (4.3%) compared to MedSAM (bias: -13.31%, CoV: 130.3%) and nnU-Net (bias: -2.46%, CoV: 20.3%). In Monte Carlo simulations with noise perturbations, ScarNet achieved significantly higher scar Dice (0.892 \pm 0.053, CoV = 5.9%) than MedSAM (0.048 \pm 0.112, CoV = 233.3%) and nnU-Net (0.615 \pm 0.537, CoV = 28.7%). Conclusion: ScarNet outperformed MedSAM and nnU-Net in accurately segmenting myocardial and scar boundaries in LGE images. The model exhibited robust performance across diverse image qualities and scar patterns.
FinLoRA: Finetuning Quantized Financial Large Language Models Using Low-Rank Adaptation
Dec 16, 2024



Finetuned large language models (LLMs) have shown remarkable performance in financial tasks, such as sentiment analysis and information retrieval. Due to privacy concerns, finetuning and deploying Financial LLMs (FinLLMs) locally are crucial for institutions. However, finetuning FinLLMs poses challenges including GPU memory constraints and long input sequences. In this paper, we employ quantized low-rank adaptation (QLoRA) to finetune FinLLMs, which leverage low-rank matrix decomposition and quantization techniques to significantly reduce computational requirements while maintaining high model performance. We also employ data and pipeline parallelism to enable local finetuning using cost-effective, widely accessible GPUs. Experiments on financial datasets demonstrate that our method achieves substantial improvements in accuracy, GPU memory usage, and time efficiency, underscoring the potential of lowrank methods for scalable and resource-efficient LLM finetuning.
DRL-STNet: Unsupervised Domain Adaptation for Cross-modality Medical Image Segmentation via Disentangled Representation Learning
Sep 26, 2024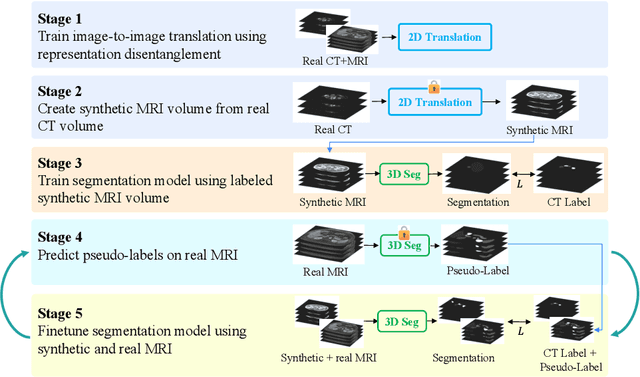

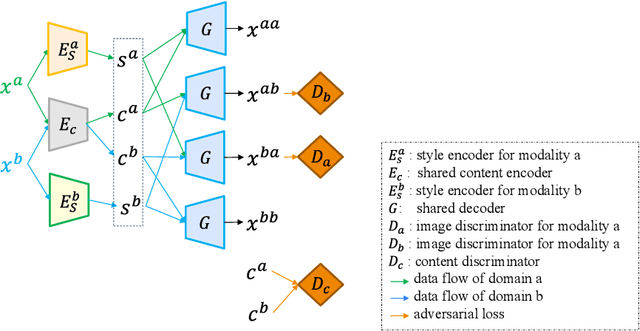
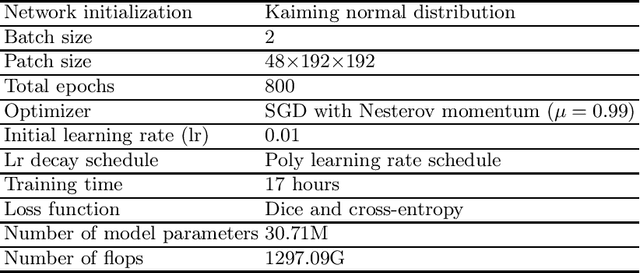
Unsupervised domain adaptation (UDA) is essential for medical image segmentation, especially in cross-modality data scenarios. UDA aims to transfer knowledge from a labeled source domain to an unlabeled target domain, thereby reducing the dependency on extensive manual annotations. This paper presents DRL-STNet, a novel framework for cross-modality medical image segmentation that leverages generative adversarial networks (GANs), disentangled representation learning (DRL), and self-training (ST). Our method leverages DRL within a GAN to translate images from the source to the target modality. Then, the segmentation model is initially trained with these translated images and corresponding source labels and then fine-tuned iteratively using a combination of synthetic and real images with pseudo-labels and real labels. The proposed framework exhibits superior performance in abdominal organ segmentation on the FLARE challenge dataset, surpassing state-of-the-art methods by 11.4% in the Dice similarity coefficient and by 13.1% in the Normalized Surface Dice metric, achieving scores of 74.21% and 80.69%, respectively. The average running time is 41 seconds, and the area under the GPU memory-time curve is 11,292 MB. These results indicate the potential of DRL-STNet for enhancing cross-modality medical image segmentation tasks.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
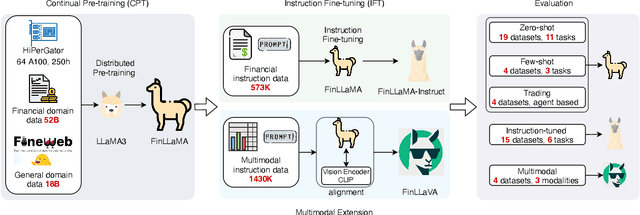
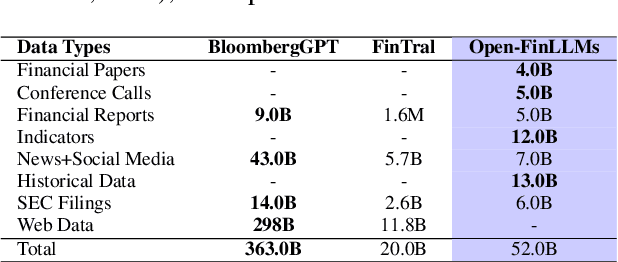
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
Pegasus-v1 Technical Report
Apr 23, 2024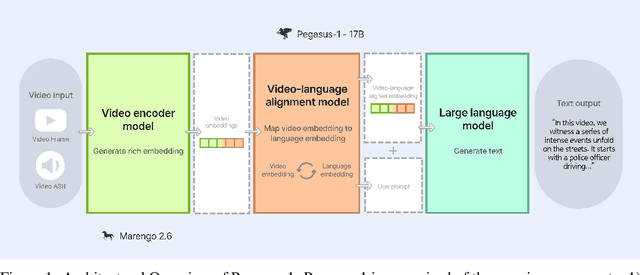
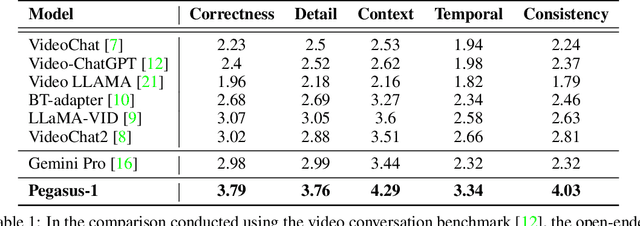


This technical report introduces Pegasus-1, a multimodal language model specialized in video content understanding and interaction through natural language. Pegasus-1 is designed to address the unique challenges posed by video data, such as interpreting spatiotemporal information, to offer nuanced video content comprehension across various lengths. This technical report overviews Pegasus-1's architecture, training strategies, and its performance in benchmarks on video conversation, zero-shot video question answering, and video summarization. We also explore qualitative characteristics of Pegasus-1 , demonstrating its capabilities as well as its limitations, in order to provide readers a balanced view of its current state and its future direction.