 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll That Glisters Is Not Gold: A Benchmark for Reference-Free Counterfactual Financial Misinformation Detection
Jan 08, 2026We introduce RFC Bench, a benchmark for evaluating large language models on financial misinformation under realistic news. RFC Bench operates at the paragraph level and captures the contextual complexity of financial news where meaning emerges from dispersed cues. The benchmark defines two complementary tasks: reference free misinformation detection and comparison based diagnosis using paired original perturbed inputs. Experiments reveal a consistent pattern: performance is substantially stronger when comparative context is available, while reference free settings expose significant weaknesses, including unstable predictions and elevated invalid outputs. These results indicate that current models struggle to maintain coherent belief states without external grounding. By highlighting this gap, RFC Bench provides a structured testbed for studying reference free reasoning and advancing more reliable financial misinformation detection in real world settings.
FinCriticalED: A Visual Benchmark for Financial Fact-Level OCR Evaluation
Nov 19, 2025We introduce FinCriticalED (Financial Critical Error Detection), a visual benchmark for evaluating OCR and vision language models on financial documents at the fact level. Financial documents contain visually dense and table heavy layouts where numerical and temporal information is tightly coupled with structure. In high stakes settings, small OCR mistakes such as sign inversion or shifted dates can lead to materially different interpretations, while traditional OCR metrics like ROUGE and edit distance capture only surface level text similarity. \ficriticaled provides 500 image-HTML pairs with expert annotated financial facts covering over seven hundred numerical and temporal facts. It introduces three key contributions. First, it establishes the first fact level evaluation benchmark for financial document understanding, shifting evaluation from lexical overlap to domain critical factual correctness. Second, all annotations are created and verified by financial experts with strict quality control over signs, magnitudes, and temporal expressions. Third, we develop an LLM-as-Judge evaluation pipeline that performs structured fact extraction and contextual verification for visually complex financial documents. We benchmark OCR systems, open source vision language models, and proprietary models on FinCriticalED. Results show that although the strongest proprietary models achieve the highest factual accuracy, substantial errors remain in visually intricate numerical and temporal contexts. Through quantitative evaluation and expert case studies, FinCriticalED provides a rigorous foundation for advancing visual factual precision in financial and other precision critical domains.
RKEFino1: A Regulation Knowledge-Enhanced Large Language Model
Jun 06, 2025Recent advances in large language models (LLMs) hold great promise for financial applications but introduce critical accuracy and compliance challenges in Digital Regulatory Reporting (DRR). To address these issues, we propose RKEFino1, a regulation knowledge-enhanced financial reasoning model built upon Fino1, fine-tuned with domain knowledge from XBRL, CDM, and MOF. We formulate two QA tasks-knowledge-based and mathematical reasoning-and introduce a novel Numerical NER task covering financial entities in both sentences and tables. Experimental results demonstrate the effectiveness and generalization capacity of RKEFino1 in compliance-critical financial tasks. We have released our model on Hugging Face.
FinAudio: A Benchmark for Audio Large Language Models in Financial Applications
Mar 26, 2025Audio Large Language Models (AudioLLMs) have received widespread attention and have significantly improved performance on audio tasks such as conversation, audio understanding, and automatic speech recognition (ASR). Despite these advancements, there is an absence of a benchmark for assessing AudioLLMs in financial scenarios, where audio data, such as earnings conference calls and CEO speeches, are crucial resources for financial analysis and investment decisions. In this paper, we introduce \textsc{FinAudio}, the first benchmark designed to evaluate the capacity of AudioLLMs in the financial domain. We first define three tasks based on the unique characteristics of the financial domain: 1) ASR for short financial audio, 2) ASR for long financial audio, and 3) summarization of long financial audio. Then, we curate two short and two long audio datasets, respectively, and develop a novel dataset for financial audio summarization, comprising the \textsc{FinAudio} benchmark. Then, we evaluate seven prevalent AudioLLMs on \textsc{FinAudio}. Our evaluation reveals the limitations of existing AudioLLMs in the financial domain and offers insights for improving AudioLLMs. All datasets and codes will be released.
Enhancing Financial Time-Series Forecasting with Retrieval-Augmented Large Language Models
Feb 11, 2025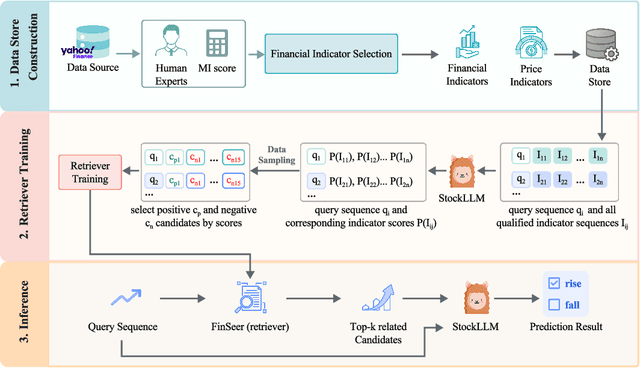

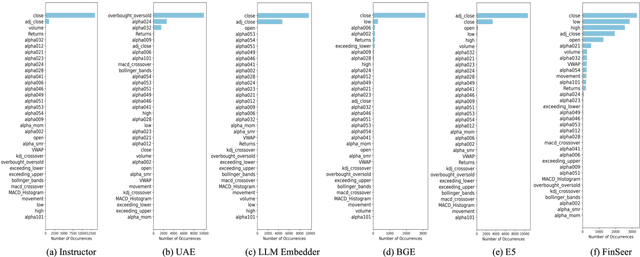
Stock movement prediction, a critical task in financial time-series forecasting, relies on identifying and retrieving key influencing factors from vast and complex datasets. However, traditional text-trained or numeric similarity-based retrieval methods often struggle to handle the intricacies of financial data. To address this, we propose the first retrieval-augmented generation (RAG) framework specifically designed for financial time-series forecasting. Our framework incorporates three key innovations: a fine-tuned 1B large language model (StockLLM) as its backbone, a novel candidate selection method enhanced by LLM feedback, and a training objective that maximizes the similarity between queries and historically significant sequences. These advancements enable our retriever, FinSeer, to uncover meaningful patterns while effectively minimizing noise in complex financial datasets. To support robust evaluation, we also construct new datasets that integrate financial indicators and historical stock prices. Experimental results demonstrate that our RAG framework outperforms both the baseline StockLLM and random retrieval methods, showcasing its effectiveness. FinSeer, as the retriever, achieves an 8% higher accuracy on the BIGDATA22 benchmark and retrieves more impactful sequences compared to existing retrieval methods. This work highlights the importance of tailored retrieval models in financial forecasting and provides a novel, scalable framework for future research in the field.
Retrieval-augmented Large Language Models for Financial Time Series Forecasting
Feb 09, 2025Stock movement prediction, a fundamental task in financial time-series forecasting, requires identifying and retrieving critical influencing factors from vast amounts of time-series data. However, existing text-trained or numeric similarity-based retrieval methods fall short in handling complex financial analysis. To address this, we propose the first retrieval-augmented generation (RAG) framework for financial time-series forecasting, featuring three key innovations: a fine-tuned 1B parameter large language model (StockLLM) as the backbone, a novel candidate selection method leveraging LLM feedback, and a training objective that maximizes similarity between queries and historically significant sequences. This enables our retriever, FinSeer, to uncover meaningful patterns while minimizing noise in complex financial data. We also construct new datasets integrating financial indicators and historical stock prices to train FinSeer and ensure robust evaluation. Experimental results demonstrate that our RAG framework outperforms bare StockLLM and random retrieval, highlighting its effectiveness, while FinSeer surpasses existing retrieval methods, achieving an 8\% higher accuracy on BIGDATA22 and retrieving more impactful sequences. This work underscores the importance of tailored retrieval models in financial forecasting and provides a novel framework for future research.
INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent
Dec 24, 2024



Recent advancements have underscored the potential of large language model (LLM)-based agents in financial decision-making. Despite this progress, the field currently encounters two main challenges: (1) the lack of a comprehensive LLM agent framework adaptable to a variety of financial tasks, and (2) the absence of standardized benchmarks and consistent datasets for assessing agent performance. To tackle these issues, we introduce \textsc{InvestorBench}, the first benchmark specifically designed for evaluating LLM-based agents in diverse financial decision-making contexts. InvestorBench enhances the versatility of LLM-enabled agents by providing a comprehensive suite of tasks applicable to different financial products, including single equities like stocks, cryptocurrencies and exchange-traded funds (ETFs). Additionally, we assess the reasoning and decision-making capabilities of our agent framework using thirteen different LLMs as backbone models, across various market environments and tasks. Furthermore, we have curated a diverse collection of open-source, multi-modal datasets and developed a comprehensive suite of environments for financial decision-making. This establishes a highly accessible platform for evaluating financial agents' performance across various scenarios.
UCFE: A User-Centric Financial Expertise Benchmark for Large Language Models
Oct 22, 2024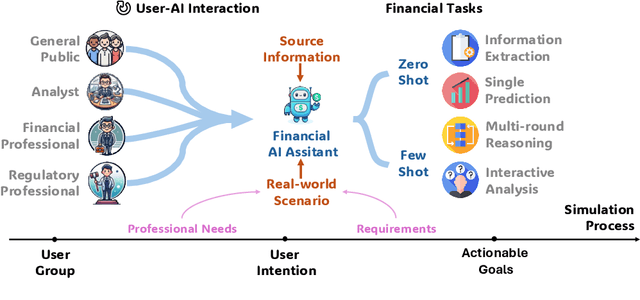
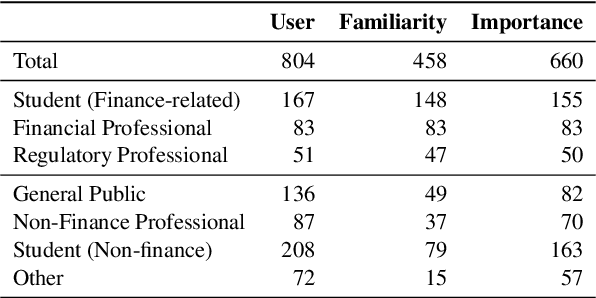
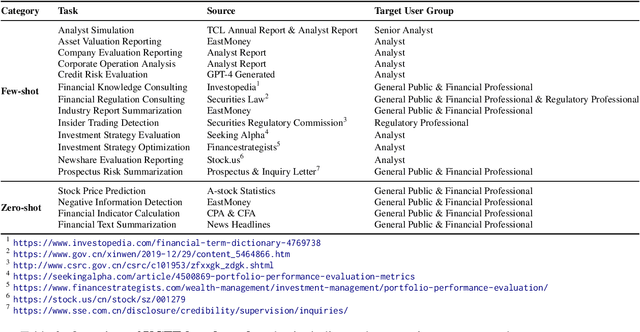
This paper introduces the UCFE: User-Centric Financial Expertise benchmark, an innovative framework designed to evaluate the ability of large language models (LLMs) to handle complex real-world financial tasks. UCFE benchmark adopts a hybrid approach that combines human expert evaluations with dynamic, task-specific interactions to simulate the complexities of evolving financial scenarios. Firstly, we conducted a user study involving 804 participants, collecting their feedback on financial tasks. Secondly, based on this feedback, we created our dataset that encompasses a wide range of user intents and interactions. This dataset serves as the foundation for benchmarking 12 LLM services using the LLM-as-Judge methodology. Our results show a significant alignment between benchmark scores and human preferences, with a Pearson correlation coefficient of 0.78, confirming the effectiveness of the UCFE dataset and our evaluation approach. UCFE benchmark not only reveals the potential of LLMs in the financial sector but also provides a robust framework for assessing their performance and user satisfaction. The benchmark dataset and evaluation code are available.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
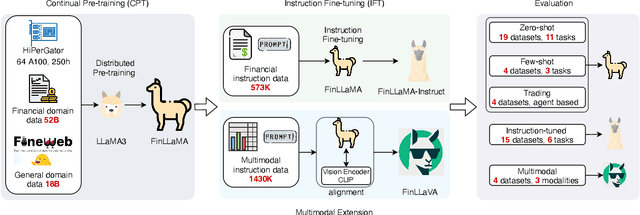
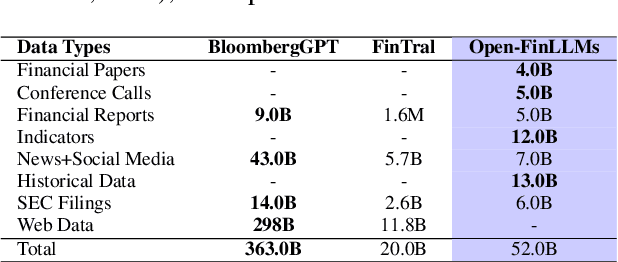
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
Jul 10, 2024


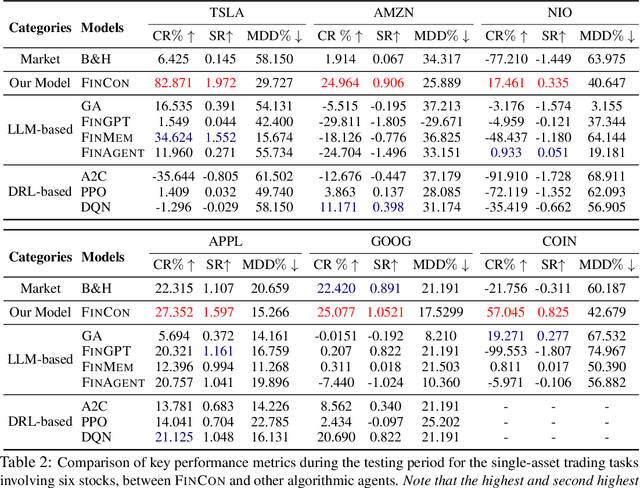
Large language models (LLMs) have demonstrated notable potential in conducting complex tasks and are increasingly utilized in various financial applications. However, high-quality sequential financial investment decision-making remains challenging. These tasks require multiple interactions with a volatile environment for every decision, demanding sufficient intelligence to maximize returns and manage risks. Although LLMs have been used to develop agent systems that surpass human teams and yield impressive investment returns, opportunities to enhance multi-sourced information synthesis and optimize decision-making outcomes through timely experience refinement remain unexplored. Here, we introduce the FinCon, an LLM-based multi-agent framework with CONceptual verbal reinforcement tailored for diverse FINancial tasks. Inspired by effective real-world investment firm organizational structures, FinCon utilizes a manager-analyst communication hierarchy. This structure allows for synchronized cross-functional agent collaboration towards unified goals through natural language interactions and equips each agent with greater memory capacity than humans. Additionally, a risk-control component in FinCon enhances decision quality by episodically initiating a self-critiquing mechanism to update systematic investment beliefs. The conceptualized beliefs serve as verbal reinforcement for the future agent's behavior and can be selectively propagated to the appropriate node that requires knowledge updates. This feature significantly improves performance while reducing unnecessary peer-to-peer communication costs. Moreover, FinCon demonstrates strong generalization capabilities in various financial tasks, including single stock trading and portfolio management.