 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll That Glisters Is Not Gold: A Benchmark for Reference-Free Counterfactual Financial Misinformation Detection
Jan 08, 2026We introduce RFC Bench, a benchmark for evaluating large language models on financial misinformation under realistic news. RFC Bench operates at the paragraph level and captures the contextual complexity of financial news where meaning emerges from dispersed cues. The benchmark defines two complementary tasks: reference free misinformation detection and comparison based diagnosis using paired original perturbed inputs. Experiments reveal a consistent pattern: performance is substantially stronger when comparative context is available, while reference free settings expose significant weaknesses, including unstable predictions and elevated invalid outputs. These results indicate that current models struggle to maintain coherent belief states without external grounding. By highlighting this gap, RFC Bench provides a structured testbed for studying reference free reasoning and advancing more reliable financial misinformation detection in real world settings.
RAAR: Retrieval Augmented Agentic Reasoning for Cross-Domain Misinformation Detection
Jan 08, 2026Cross-domain misinformation detection is challenging, as misinformation arises across domains with substantial differences in knowledge and discourse. Existing methods often rely on single-perspective cues and struggle to generalize to challenging or underrepresented domains, while reasoning large language models (LLMs), though effective on complex tasks, are limited to same-distribution data. To address these gaps, we introduce RAAR, the first retrieval-augmented agentic reasoning framework for cross-domain misinformation detection. To enable cross-domain transfer beyond same-distribution assumptions, RAAR retrieves multi-perspective source-domain evidence aligned with each target sample's semantics, sentiment, and writing style. To overcome single-perspective modeling and missing systematic reasoning, RAAR constructs verifiable multi-step reasoning paths through specialized multi-agent collaboration, where perspective-specific agents produce complementary analyses and a summary agent integrates them under verifier guidance. RAAR further applies supervised fine-tuning and reinforcement learning to train a single multi-task verifier to enhance verification and reasoning capabilities. Based on RAAR, we trained the RAAR-8b and RAAR-14b models. Evaluation on three cross-domain misinformation detection tasks shows that RAAR substantially enhances the capabilities of the base models and outperforms other cross-domain methods, advanced LLMs, and LLM-based adaptation approaches. The project will be released at https://github.com/lzw108/RAAR.
INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent
Dec 24, 2024



Recent advancements have underscored the potential of large language model (LLM)-based agents in financial decision-making. Despite this progress, the field currently encounters two main challenges: (1) the lack of a comprehensive LLM agent framework adaptable to a variety of financial tasks, and (2) the absence of standardized benchmarks and consistent datasets for assessing agent performance. To tackle these issues, we introduce \textsc{InvestorBench}, the first benchmark specifically designed for evaluating LLM-based agents in diverse financial decision-making contexts. InvestorBench enhances the versatility of LLM-enabled agents by providing a comprehensive suite of tasks applicable to different financial products, including single equities like stocks, cryptocurrencies and exchange-traded funds (ETFs). Additionally, we assess the reasoning and decision-making capabilities of our agent framework using thirteen different LLMs as backbone models, across various market environments and tasks. Furthermore, we have curated a diverse collection of open-source, multi-modal datasets and developed a comprehensive suite of environments for financial decision-making. This establishes a highly accessible platform for evaluating financial agents' performance across various scenarios.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Dec 03, 2023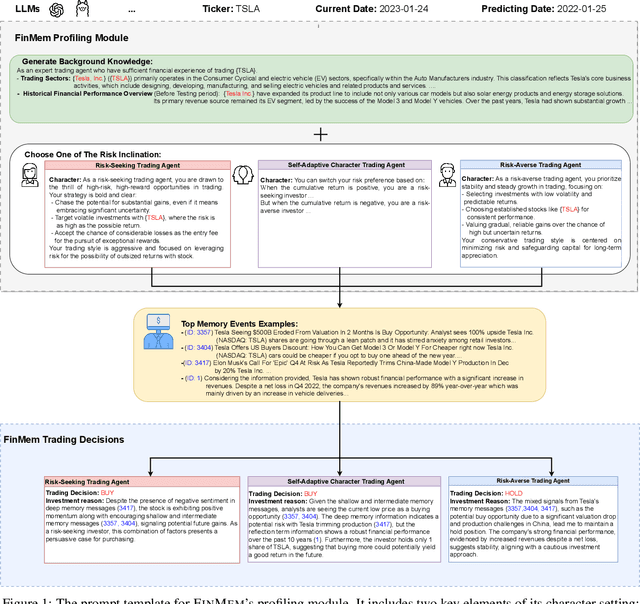
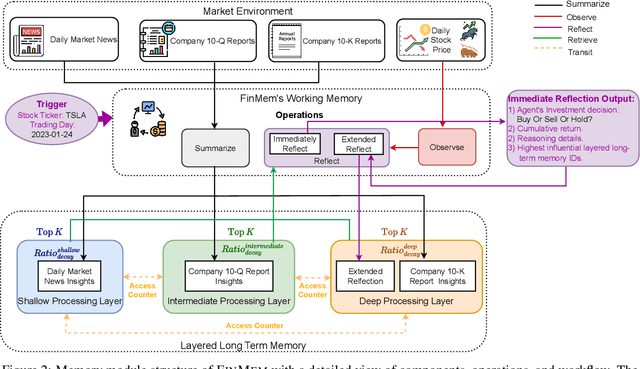


Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMem}, a novel LLM-based agent framework devised for financial decision-making. It encompasses three core modules: Profiling, to customize the agent's characteristics; Memory, with layered message processing, to aid the agent in assimilating hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMem}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMem} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks. We then fine-tuned the agent's perceptual span and character setting to achieve a significantly enhanced trading performance. Collectively, \textsc{FinMem} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.