 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoGS: Training-Free Gaussian Splat Simplification
Mar 17, 20263D Gaussian Splat (3DGS) enables high-fidelity, real-time novel view synthesis by representing scenes with large sets of anisotropic primitives, but often requires millions of Splats, incurring significant storage and transmission costs. Most existing compression methods rely on GPU-intensive post-training optimization with calibrated images, limiting practical deployment. We introduce NanoGS, a training-free and lightweight framework for Gaussian Splat simplification. Instead of relying on image-based rendering supervision, NanoGS formulates simplification as local pairwise merging over a sparse spatial graph. The method approximates a pair of Gaussians with a single primitive using mass preserved moment matching and evaluates merge quality through a principled merge cost between the original mixture and its approximation. By restricting merge candidates to local neighborhoods and selecting compatible pairs efficiently, NanoGS produces compact Gaussian representations while preserving scene structure and appearance. NanoGS operates directly on existing Gaussian Splat models, runs efficiently on CPU, and preserves the standard 3DGS parameterization, enabling seamless integration with existing rendering pipelines. Experiments demonstrate that NanoGS substantially reduces primitive count while maintaining high rendering fidelity, providing an efficient and practical solution for Gaussian Splat simplification. Our project website is available at https://saliteta.github.io/NanoGS/.
IDU: Incremental Dynamic Update of Existing 3D Virtual Environments with New Imagery Data
Aug 25, 2025For simulation and training purposes, military organizations have made substantial investments in developing high-resolution 3D virtual environments through extensive imaging and 3D scanning. However, the dynamic nature of battlefield conditions-where objects may appear or vanish over time-makes frequent full-scale updates both time-consuming and costly. In response, we introduce the Incremental Dynamic Update (IDU) pipeline, which efficiently updates existing 3D reconstructions, such as 3D Gaussian Splatting (3DGS), with only a small set of newly acquired images. Our approach starts with camera pose estimation to align new images with the existing 3D model, followed by change detection to pinpoint modifications in the scene. A 3D generative AI model is then used to create high-quality 3D assets of the new elements, which are seamlessly integrated into the existing 3D model. The IDU pipeline incorporates human guidance to ensure high accuracy in object identification and placement, with each update focusing on a single new object at a time. Experimental results confirm that our proposed IDU pipeline significantly reduces update time and labor, offering a cost-effective and targeted solution for maintaining up-to-date 3D models in rapidly evolving military scenarios.
Splat Feature Solver
Aug 17, 2025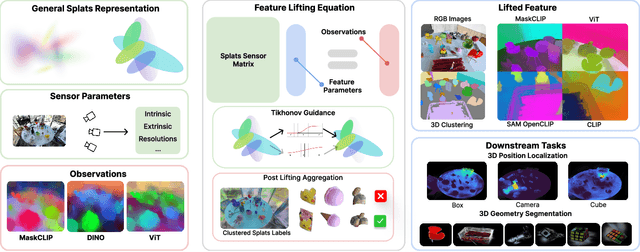
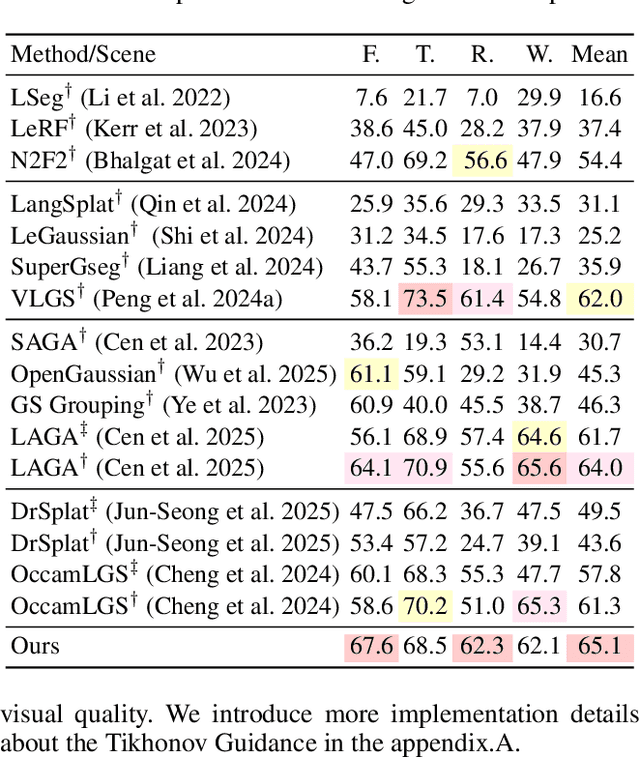
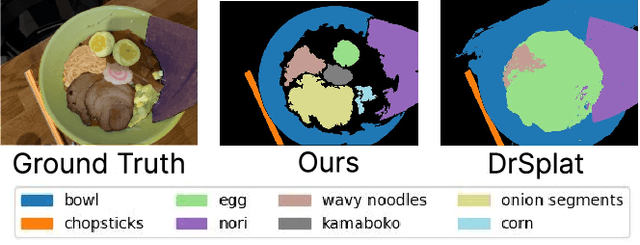
Feature lifting has emerged as a crucial component in 3D scene understanding, enabling the attachment of rich image feature descriptors (e.g., DINO, CLIP) onto splat-based 3D representations. The core challenge lies in optimally assigning rich general attributes to 3D primitives while addressing the inconsistency issues from multi-view images. We present a unified, kernel- and feature-agnostic formulation of the feature lifting problem as a sparse linear inverse problem, which can be solved efficiently in closed form. Our approach admits a provable upper bound on the global optimal error under convex losses for delivering high quality lifted features. To address inconsistencies and noise in multi-view observations, we introduce two complementary regularization strategies to stabilize the solution and enhance semantic fidelity. Tikhonov Guidance enforces numerical stability through soft diagonal dominance, while Post-Lifting Aggregation filters noisy inputs via feature clustering. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on open-vocabulary 3D segmentation benchmarks, outperforming training-based, grouping-based, and heuristic-forward baselines while producing the lifted features in minutes. Code is available at \href{https://github.com/saliteta/splat-distiller.git}{\textbf{github}}. We also have a \href{https://splat-distiller.pages.dev/}
Dual Classification Head Self-training Network for Cross-scene Hyperspectral Image Classification
Feb 25, 2025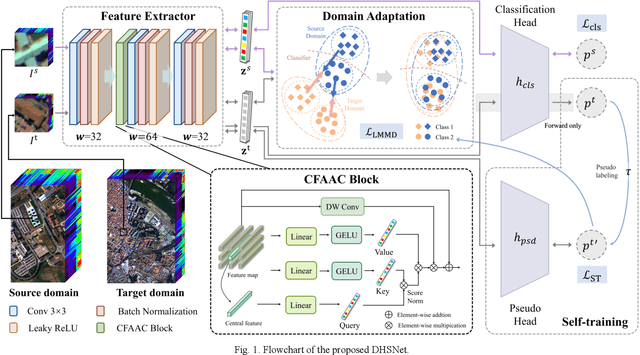
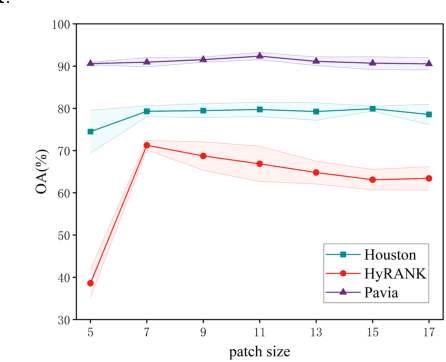
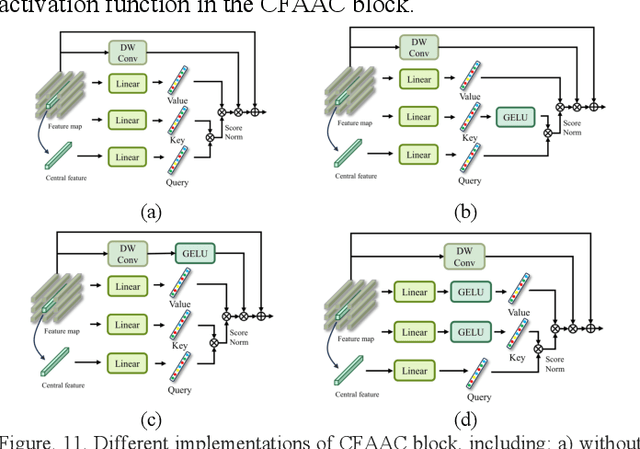

Due to the difficulty of obtaining labeled data for hyperspectral images (HSIs), cross-scene classification has emerged as a widely adopted approach in the remote sensing community. It involves training a model using labeled data from a source domain (SD) and unlabeled data from a target domain (TD), followed by inferencing on the TD. However, variations in the reflectance spectrum of the same object between the SD and the TD, as well as differences in the feature distribution of the same land cover class, pose significant challenges to the performance of cross-scene classification. To address this issue, we propose a dual classification head self-training network (DHSNet). This method aligns class-wise features across domains, ensuring that the trained classifier can accurately classify TD data of different classes. We introduce a dual classification head self-training strategy for the first time in the cross-scene HSI classification field. The proposed approach mitigates domain gap while preventing the accumulation of incorrect pseudo-labels in the model. Additionally, we incorporate a novel central feature attention mechanism to enhance the model's capacity to learn scene-invariant features across domains. Experimental results on three cross-scene HSI datasets demonstrate that the proposed DHSNET significantly outperforms other state-of-the-art approaches. The code for DHSNet will be available at https://github.com/liurongwhm.
Deformable Beta Splatting
Jan 27, 2025



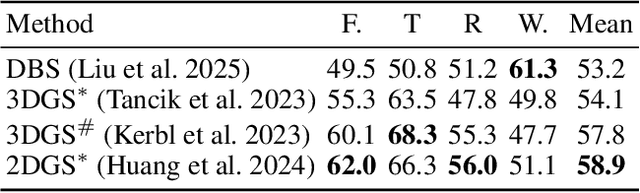
3D Gaussian Splatting (3DGS) has advanced radiance field reconstruction by enabling real-time rendering. However, its reliance on Gaussian kernels for geometry and low-order Spherical Harmonics (SH) for color encoding limits its ability to capture complex geometries and diverse colors. We introduce Deformable Beta Splatting (DBS), a deformable and compact approach that enhances both geometry and color representation. DBS replaces Gaussian kernels with deformable Beta Kernels, which offer bounded support and adaptive frequency control to capture fine geometric details with higher fidelity while achieving better memory efficiency. In addition, we extended the Beta Kernel to color encoding, which facilitates improved representation of diffuse and specular components, yielding superior results compared to SH-based methods. Furthermore, Unlike prior densification techniques that depend on Gaussian properties, we mathematically prove that adjusting regularized opacity alone ensures distribution-preserved Markov chain Monte Carlo (MCMC), independent of the splatting kernel type. Experimental results demonstrate that DBS achieves state-of-the-art visual quality while utilizing only 45% of the parameters and rendering 1.5x faster than 3DGS-based methods. Notably, for the first time, splatting-based methods outperform state-of-the-art Neural Radiance Fields, highlighting the superior performance and efficiency of DBS for real-time radiance field rendering.
SplatMAP: Online Dense Monocular SLAM with 3D Gaussian Splatting
Jan 14, 2025
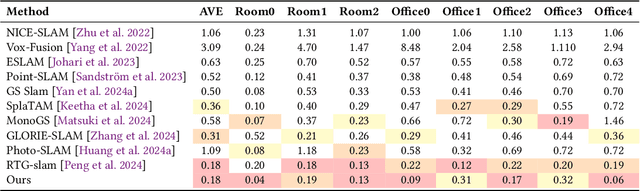

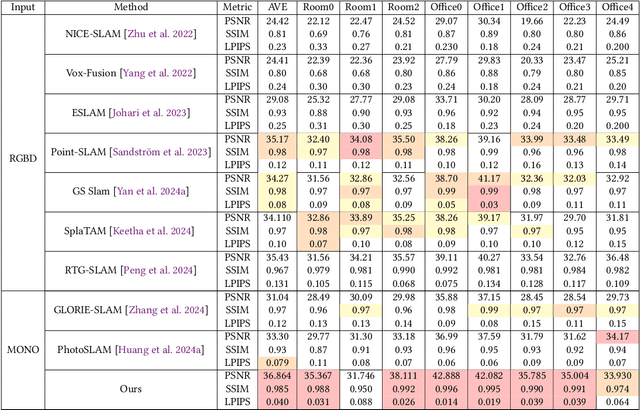
Achieving high-fidelity 3D reconstruction from monocular video remains challenging due to the inherent limitations of traditional methods like Structure-from-Motion (SfM) and monocular SLAM in accurately capturing scene details. While differentiable rendering techniques such as Neural Radiance Fields (NeRF) address some of these challenges, their high computational costs make them unsuitable for real-time applications. Additionally, existing 3D Gaussian Splatting (3DGS) methods often focus on photometric consistency, neglecting geometric accuracy and failing to exploit SLAM's dynamic depth and pose updates for scene refinement. We propose a framework integrating dense SLAM with 3DGS for real-time, high-fidelity dense reconstruction. Our approach introduces SLAM-Informed Adaptive Densification, which dynamically updates and densifies the Gaussian model by leveraging dense point clouds from SLAM. Additionally, we incorporate Geometry-Guided Optimization, which combines edge-aware geometric constraints and photometric consistency to jointly optimize the appearance and geometry of the 3DGS scene representation, enabling detailed and accurate SLAM mapping reconstruction. Experiments on the Replica and TUM-RGBD datasets demonstrate the effectiveness of our approach, achieving state-of-the-art results among monocular systems. Specifically, our method achieves a PSNR of 36.864, SSIM of 0.985, and LPIPS of 0.040 on Replica, representing improvements of 10.7%, 6.4%, and 49.4%, respectively, over the previous SOTA. On TUM-RGBD, our method outperforms the closest baseline by 10.2%, 6.6%, and 34.7% in the same metrics. These results highlight the potential of our framework in bridging the gap between photometric and geometric dense 3D scene representations, paving the way for practical and efficient monocular dense reconstruction.
FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
Jul 10, 2024


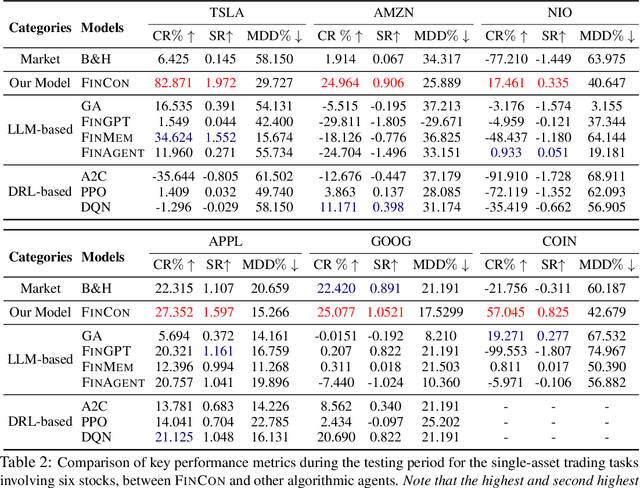
Large language models (LLMs) have demonstrated notable potential in conducting complex tasks and are increasingly utilized in various financial applications. However, high-quality sequential financial investment decision-making remains challenging. These tasks require multiple interactions with a volatile environment for every decision, demanding sufficient intelligence to maximize returns and manage risks. Although LLMs have been used to develop agent systems that surpass human teams and yield impressive investment returns, opportunities to enhance multi-sourced information synthesis and optimize decision-making outcomes through timely experience refinement remain unexplored. Here, we introduce the FinCon, an LLM-based multi-agent framework with CONceptual verbal reinforcement tailored for diverse FINancial tasks. Inspired by effective real-world investment firm organizational structures, FinCon utilizes a manager-analyst communication hierarchy. This structure allows for synchronized cross-functional agent collaboration towards unified goals through natural language interactions and equips each agent with greater memory capacity than humans. Additionally, a risk-control component in FinCon enhances decision quality by episodically initiating a self-critiquing mechanism to update systematic investment beliefs. The conceptualized beliefs serve as verbal reinforcement for the future agent's behavior and can be selectively propagated to the appropriate node that requires knowledge updates. This feature significantly improves performance while reducing unnecessary peer-to-peer communication costs. Moreover, FinCon demonstrates strong generalization capabilities in various financial tasks, including single stock trading and portfolio management.
AtomGS: Atomizing Gaussian Splatting for High-Fidelity Radiance Field
May 22, 20243D Gaussian Splatting (3DGS) has recently advanced radiance field reconstruction by offering superior capabilities for novel view synthesis and real-time rendering speed. However, its strategy of blending optimization and adaptive density control might lead to sub-optimal results; it can sometimes yield noisy geometry and blurry artifacts due to prioritizing optimizing large Gaussians at the cost of adequately densifying smaller ones. To address this, we introduce AtomGS, consisting of Atomized Proliferation and Geometry-Guided Optimization. The Atomized Proliferation constrains ellipsoid Gaussians of various sizes into more uniform-sized Atom Gaussians. The strategy enhances the representation of areas with fine features by placing greater emphasis on densification in accordance with scene details. In addition, we proposed a Geometry-Guided Optimization approach that incorporates an Edge-Aware Normal Loss. This optimization method effectively smooths flat surfaces while preserving intricate details. Our evaluation shows that AtomGS outperforms existing state-of-the-art methods in rendering quality. Additionally, it achieves competitive accuracy in geometry reconstruction and offers a significant improvement in training speed over other SDF-based methods. More interactive demos can be found in our website (https://rongliu-leo.github.io/AtomGS/).
WeakSurg: Weakly supervised surgical instrument segmentation using temporal equivariance and semantic continuity
Mar 14, 2024
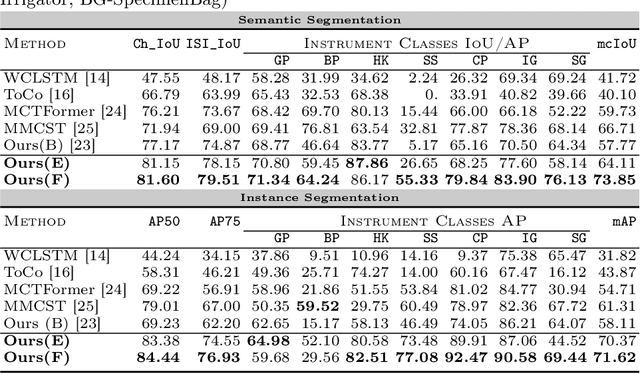


Weakly supervised surgical instrument segmentation with only instrument presence labels has been rarely explored in surgical domain. To mitigate the highly under-constrained challenges, we extend a two-stage weakly supervised segmentation paradigm with temporal attributes from two perspectives. From a temporal equivariance perspective, we propose a prototype-based temporal equivariance regulation loss to enhance pixel-wise consistency between adjacent features. From a semantic continuity perspective, we propose a class-aware temporal semantic continuity loss to constrain the semantic consistency between a global view of target frame and local non-discriminative regions of adjacent reference frame. To the best of our knowledge, WeakSurg is the first instrument-presence-only weakly supervised segmentation architecture to take temporal information into account for surgical scenarios. Extensive experiments are validated on Cholec80, an open benchmark for phase and instrument recognition. We annotate instance-wise instrument labels with fixed time-steps which are double checked by a clinician with 3-years experience. Our results show that WeakSurg compares favorably with state-of-the-art methods not only on semantic segmentation metrics but also on instance segmentation metrics.
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Dec 03, 2023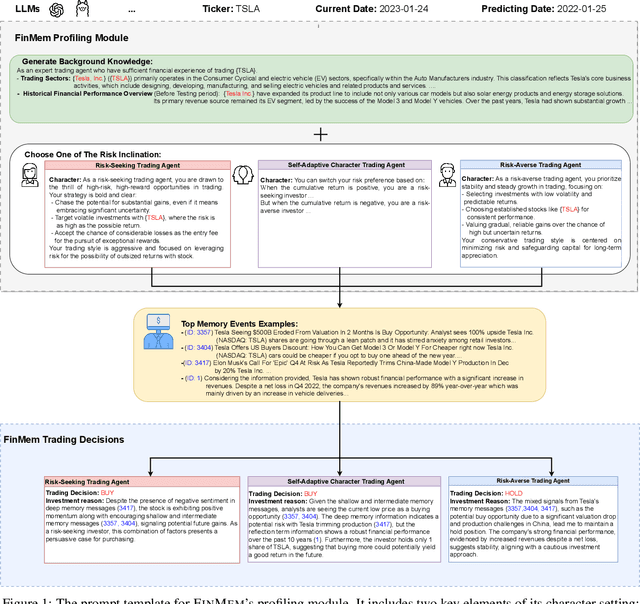
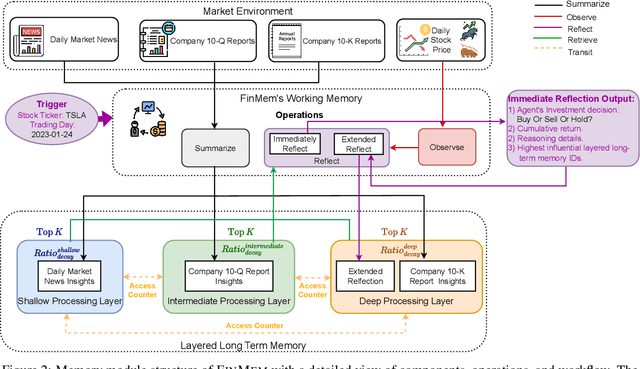


Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMem}, a novel LLM-based agent framework devised for financial decision-making. It encompasses three core modules: Profiling, to customize the agent's characteristics; Memory, with layered message processing, to aid the agent in assimilating hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMem}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMem} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks. We then fine-tuned the agent's perceptual span and character setting to achieve a significantly enhanced trading performance. Collectively, \textsc{FinMem} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.