 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStand for Something or Fall for Everything: Predict Misinformation Spread with Stance-Aware Graph Neural Networks
Oct 04, 2023



Although pervasive spread of misinformation on social media platforms has become a pressing challenge, existing platform interventions have shown limited success in curbing its dissemination. In this study, we propose a stance-aware graph neural network (stance-aware GNN) that leverages users' stances to proactively predict misinformation spread. As different user stances can form unique echo chambers, we customize four information passing paths in stance-aware GNN, while the trainable attention weights provide explainability by highlighting each structure's importance. Evaluated on a real-world dataset, stance-aware GNN outperforms benchmarks by 32.65% and exceeds advanced GNNs without user stance by over 4.69%. Furthermore, the attention weights indicate that users' opposition stances have a higher impact on their neighbors' behaviors than supportive ones, which function as social correction to halt misinformation propagation. Overall, our study provides an effective predictive model for platforms to combat misinformation, and highlights the impact of user stances in the misinformation propagation.
Empirical Analysis of Multi-Task Learning for Reducing Model Bias in Toxic Comment Detection
Sep 26, 2019
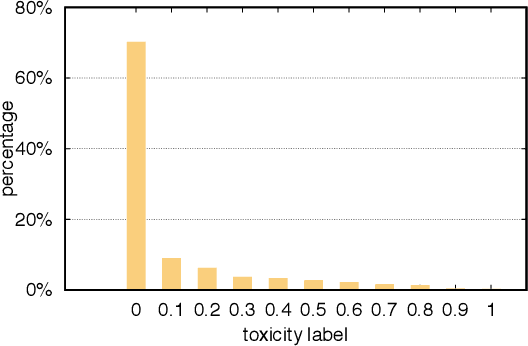

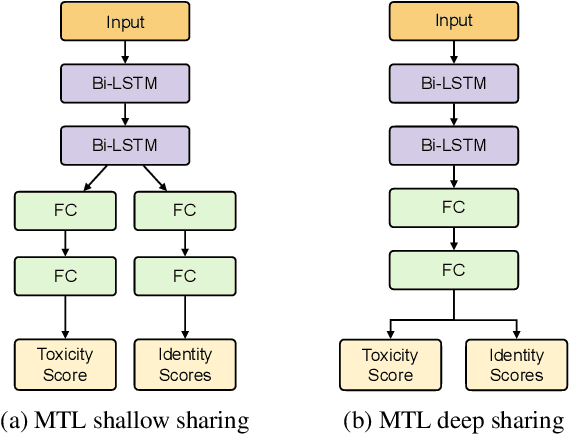
With the recent rise of toxicity in online conversations on social media platforms, using modern machine learning algorithms for toxic comment detection has become a central focus of many online applications. Researchers and companies have developed a variety of shallow and deep learning models to identify toxicity in online conversations, reviews, or comments with mixed successes. However, these existing approaches have learned to incorrectly associate non-toxic comments that have certain trigger-words (e.g. gay, lesbian, black, muslim) as a potential source of toxicity. In this paper, we evaluate dozens of state-of-the-art models with the specific focus of reducing model bias towards these commonly-attacked identity groups. We propose a multi-task learning model with an attention layer that jointly learns to predict the toxicity of a comment as well as the identities present in the comments in order to reduce this bias. We then compare our model to an array of shallow and deep-learning models using metrics designed especially to test for unintended model bias within these identity groups.