 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeVStereo: A NeRF-Driven NVS-Stereo Architecture for High-Fidelity 3D Tasks
Feb 05, 2026In modern dense 3D reconstruction, feed-forward systems (e.g., VGGT, pi3) focus on end-to-end matching and geometry prediction but do not explicitly output the novel view synthesis (NVS). Neural rendering-based approaches offer high-fidelity NVS and detailed geometry from posed images, yet they typically assume fixed camera poses and can be sensitive to pose errors. As a result, it remains non-trivial to obtain a single framework that can offer accurate poses, reliable depth, high-quality rendering, and accurate 3D surfaces from casually captured views. We present NeVStereo, a NeRF-driven NVS-stereo architecture that aims to jointly deliver camera poses, multi-view depth, novel view synthesis, and surface reconstruction from multi-view RGB-only inputs. NeVStereo combines NeRF-based NVS for stereo-friendly renderings, confidence-guided multi-view depth estimation, NeRF-coupled bundle adjustment for pose refinement, and an iterative refinement stage that updates both depth and the radiance field to improve geometric consistency. This design mitigated the common NeRF-based issues such as surface stacking, artifacts, and pose-depth coupling. Across indoor, outdoor, tabletop, and aerial benchmarks, our experiments indicate that NeVStereo achieves consistently strong zero-shot performance, with up to 36% lower depth error, 10.4% improved pose accuracy, 4.5% higher NVS fidelity, and state-of-the-art mesh quality (F1 91.93%, Chamfer 4.35 mm) compared to existing prestigious methods.
SplatMAP: Online Dense Monocular SLAM with 3D Gaussian Splatting
Jan 14, 2025
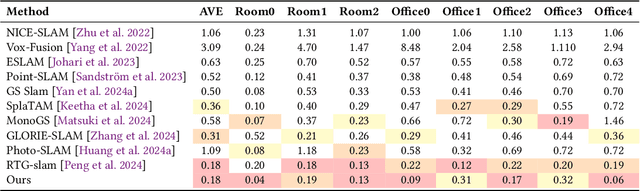

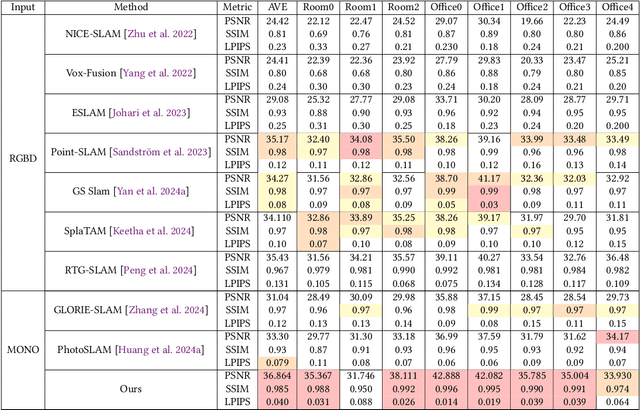
Achieving high-fidelity 3D reconstruction from monocular video remains challenging due to the inherent limitations of traditional methods like Structure-from-Motion (SfM) and monocular SLAM in accurately capturing scene details. While differentiable rendering techniques such as Neural Radiance Fields (NeRF) address some of these challenges, their high computational costs make them unsuitable for real-time applications. Additionally, existing 3D Gaussian Splatting (3DGS) methods often focus on photometric consistency, neglecting geometric accuracy and failing to exploit SLAM's dynamic depth and pose updates for scene refinement. We propose a framework integrating dense SLAM with 3DGS for real-time, high-fidelity dense reconstruction. Our approach introduces SLAM-Informed Adaptive Densification, which dynamically updates and densifies the Gaussian model by leveraging dense point clouds from SLAM. Additionally, we incorporate Geometry-Guided Optimization, which combines edge-aware geometric constraints and photometric consistency to jointly optimize the appearance and geometry of the 3DGS scene representation, enabling detailed and accurate SLAM mapping reconstruction. Experiments on the Replica and TUM-RGBD datasets demonstrate the effectiveness of our approach, achieving state-of-the-art results among monocular systems. Specifically, our method achieves a PSNR of 36.864, SSIM of 0.985, and LPIPS of 0.040 on Replica, representing improvements of 10.7%, 6.4%, and 49.4%, respectively, over the previous SOTA. On TUM-RGBD, our method outperforms the closest baseline by 10.2%, 6.6%, and 34.7% in the same metrics. These results highlight the potential of our framework in bridging the gap between photometric and geometric dense 3D scene representations, paving the way for practical and efficient monocular dense reconstruction.
Let's Roll: Synthetic Dataset Analysis for Pedestrian Detection Across Different Shutter Types
Sep 15, 2023



Computer vision (CV) pipelines are typically evaluated on datasets processed by image signal processing (ISP) pipelines even though, for resource-constrained applications, an important research goal is to avoid as many ISP steps as possible. In particular, most CV datasets consist of global shutter (GS) images even though most cameras today use a rolling shutter (RS). This paper studies the impact of different shutter mechanisms on machine learning (ML) object detection models on a synthetic dataset that we generate using the advanced simulation capabilities of Unreal Engine 5 (UE5). In particular, we train and evaluate mainstream detection models with our synthetically-generated paired GS and RS datasets to ascertain whether there exists a significant difference in detection accuracy between these two shutter modalities, especially when capturing low-speed objects (e.g., pedestrians). The results of this emulation framework indicate the performance between them are remarkably congruent for coarse-grained detection (mean average precision (mAP) for IOU=0.5), but have significant differences for fine-grained measures of detection accuracy (mAP for IOU=0.5:0.95). This implies that ML pipelines might not need explicit correction for RS for many object detection applications, but mitigating RS effects in ISP-less ML pipelines that target fine-grained location of the objects may need additional research.
FireFly A Synthetic Dataset for Ember Detection in Wildfire
Aug 06, 2023This paper presents "FireFly", a synthetic dataset for ember detection created using Unreal Engine 4 (UE4), designed to overcome the current lack of ember-specific training resources. To create the dataset, we present a tool that allows the automated generation of the synthetic labeled dataset with adjustable parameters, enabling data diversity from various environmental conditions, making the dataset both diverse and customizable based on user requirements. We generated a total of 19,273 frames that have been used to evaluate FireFly on four popular object detection models. Further to minimize human intervention, we leveraged a trained model to create a semi-automatic labeling process for real-life ember frames. Moreover, we demonstrated an up to 8.57% improvement in mean Average Precision (mAP) in real-world wildfire scenarios compared to models trained exclusively on a small real dataset.
Self-Attentive Pooling for Efficient Deep Learning
Sep 19, 2022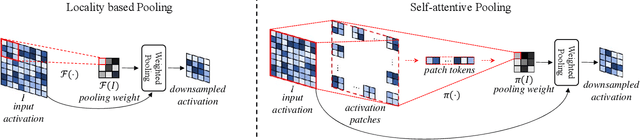
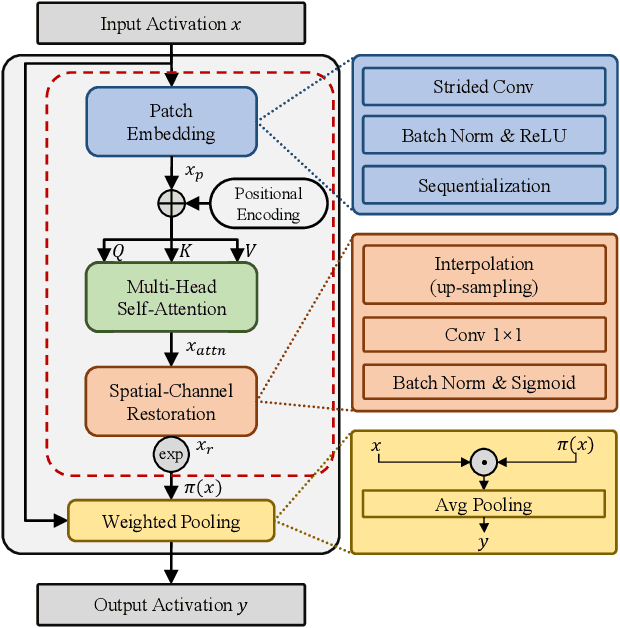
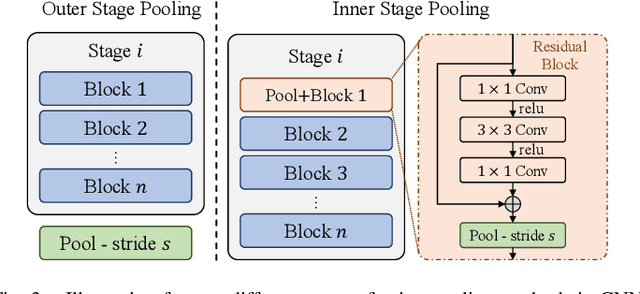

Efficient custom pooling techniques that can aggressively trim the dimensions of a feature map and thereby reduce inference compute and memory footprint for resource-constrained computer vision applications have recently gained significant traction. However, prior pooling works extract only the local context of the activation maps, limiting their effectiveness. In contrast, we propose a novel non-local self-attentive pooling method that can be used as a drop-in replacement to the standard pooling layers, such as max/average pooling or strided convolution. The proposed self-attention module uses patch embedding, multi-head self-attention, and spatial-channel restoration, followed by sigmoid activation and exponential soft-max. This self-attention mechanism efficiently aggregates dependencies between non-local activation patches during down-sampling. Extensive experiments on standard object classification and detection tasks with various convolutional neural network (CNN) architectures demonstrate the superiority of our proposed mechanism over the state-of-the-art (SOTA) pooling techniques. In particular, we surpass the test accuracy of existing pooling techniques on different variants of MobileNet-V2 on ImageNet by an average of 1.2%. With the aggressive down-sampling of the activation maps in the initial layers (providing up to 22x reduction in memory consumption), our approach achieves 1.43% higher test accuracy compared to SOTA techniques with iso-memory footprints. This enables the deployment of our models in memory-constrained devices, such as micro-controllers (without losing significant accuracy), because the initial activation maps consume a significant amount of on-chip memory for high-resolution images required for complex vision tasks. Our proposed pooling method also leverages the idea of channel pruning to further reduce memory footprints.