 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstra: a generalizable report generation foundation model for 3D computed tomography
Jun 01, 2026CT interpretation requires radiologists to review hundreds of volumetric slices per examination, making reporting time-consuming and highly expertise-dependent. Automated CT report generation offers a promising route to improving clinical efficiency, yet the field still lacks a generalizable CT report generation foundation model that supports multi-region reporting and remains robust across external real-world cohorts. Intrinsic inconsistencies in reporting style and diagnostic terminology across cohorts make naive joint training prone to noisy textual supervision, thereby limiting model generalizability. Here we present Astra, a generalizable CT report generation foundation model trained on 90,678 thoracoabdominal CT-report pairs (CTRgDB) with 353,671 abnormalities spanning eight organ systems. By harmonizing report style and further refining diagnostic consistency via reinforcement learning, Astra achieves style-consistent and diagnostically accurate report generation across diverse anatomical regions and institutions. Evaluating on CTRgDB and six external cohorts, Astra achieves state-of-the-art performance with a 44.1% average improvement in fine-grained diagnostic metrics (P<0.001). In real-world clinical workflows, Astra assistance accelerates chest report drafting by 29.6% and improves abdominal report completeness by 11.3% (P<0.001). Furthermore, Astra also demonstrates broad utility as a foundation for CT AI development, improving downstream diagnostic performance and scaling vision-language pretrain through high-quality report synthesis. Overall, Astra serves as a broadly accessible clinical assistant and a pivotal infrastructure for the next generation of AI-powered healthcare.
A physics-informed foundation model for quantitative diffusion MRI
May 29, 2026Understanding the human brain requires access to its microscopic tissue architecture. Diffusion magnetic resonance imaging (MRI) provides the only noninvasive window into whole-brain microstructure in vivo, yet reliable quantitative mapping remains confined to specialized research settings requiring dense sampling and optimized acquisition protocols. To address this gap, we present a physics-informed generative microstructure network (PIGMENT) that learns a universal generative prior of human brain microstructure and adapts it zero-shot to each participant's measured data to recover subject-specific maps. Trained on 11375 scans spanning multiple sites, vendors, and field strengths, PIGMENT enabled reliable quantitative mapping for tensor, kurtosis, and NODDI models across external datasets from five independent centers. It remains effective where conventional fitting becomes unreliable, recovering meaningful maps from extremely sparse acquisitions while supporting downstream tractography and structural connectivity mapping. PIGMENT estimates demonstrated strong biological validity, preserving submillimeter cortical microarchitectural patterns and early-childhood white matter developmental trajectories from 10-fold accelerated scans. Furthermore, PIGMENT enables reliable quantitative tensor mapping on cost-efficient low-field systems and the extraction of tumor-related biomarkers using ultra-fast clinical protocols. Together, these results establish PIGMENT as a physics-informed foundation model that extends quantitative diffusion MRI into regimes traditionally too sparse, heterogeneous, or clinically constrained for reliable analysis.
OA-WAM: Object-Addressable World Action Model for Robust Robot Manipulation
May 07, 2026World Action Models (WAMs) enhance Vision-Language-Action policies by jointly predicting scene evolution and robot actions, but existing methods usually represent the predicted world as holistic images, video tokens, or global latents. These representations are difficult for an action decoder to address when an instruction refers to a particular object, especially under scene shifts where object identity is entangled with context. We propose OA-WAM, an Object-Addressable World Action Model for robust robot manipulation. OA-WAM decomposes each frame into N+1 slot states, with one robot slot and N object slots. Each slot contains a persistent address vector and a time-varying content vector, and is fused with text, image, proprioception, and past-action tokens in a block-causal sequence. A world head predicts next-frame slot states, while a flow-matching action head decodes a 16-step continuous action chunk in the same forward pass. Addressability is enforced by routing cross-slot attention through address-only keys and resetting the address slice at every transformer layer, separating which object to act on from what that object currently is without adding extra tokens. OA-WAM matches strong VLA and WAM baselines on LIBERO (97.8%) and SimplerEnv (79.3%), reaches state-of-the-art performance on the most relevant LIBERO-Plus geometric axes, and remains competitive on the seven-axis aggregate. A causal slot-intervention test yields a swap-binding cosine of 0.87, versus at most 0.09 for holistic baselines. These results suggest that addressable object states provide an effective interface for robust world-action modeling under scene perturbations.
Neural Federated Learning for Livestock Growth Prediction
Apr 01, 2026Livestock growth prediction is essential for optimising farm management and improving the efficiency and sustainability of livestock production, yet it remains underexplored due to limited large-scale datasets and privacy concerns surrounding farm-level data. Existing biophysical models rely on fixed formulations, while most machine learning approaches are trained on small, isolated datasets, limiting their robustness and generalisability. To address these challenges, we propose LivestockFL, the first federated learning framework specifically designed for livestock growth prediction. LivestockFL enables collaborative model training across distributed farms without sharing raw data, thereby preserving data privacy while alleviating data sparsity, particularly for farms with limited historical records. The framework employs a neural architecture based on a Gated Recurrent Unit combined with a multilayer perceptron to model temporal growth patterns from historical weight records and auxiliary features. We further introduce LivestockPFL, a novel personalised federated learning framework that extends the above federated learning framework with a personalized prediction head trained on each farm's local data, producing farm-specific predictors. Experiments on a real-world dataset demonstrate the effectiveness and practicality of the proposed approaches.
ArthroCut: Autonomous Policy Learning for Robotic Bone Resection in Knee Arthroplasty
Mar 04, 2026Despite rapid commercialization of surgical robots, their autonomy and real-time decision-making remain limited in practice. To address this gap, we propose ArthroCut, an autonomous policy learning framework that upgrades knee arthroplasty robots from assistive execution to context-aware action generation. ArthroCut fine-tunes a Qwen--VL backbone on a self-built, time-synchronized multimodal dataset from 21 complete cases (23,205 RGB--D pairs), integrating preoperative CT/MR, intraoperative NDI tracking of bones and end effector, RGB--D surgical video, robot state, and textual intent. The method operates on two complementary token families -- Preoperative Imaging Tokens (PIT) to encode patient-specific anatomy and planned resection planes, and Time-Aligned Surgical Tokens (TAST) to fuse real-time visual, geometric, and kinematic evidence -- and emits an interpretable action grammar under grammar/safety-constrained decoding. In bench-top experiments on a knee prosthesis across seven trials, ArthroCut achieves an average success rate of 86% over the six standard resections, significantly outperforming strong baselines trained under the same protocol. Ablations show that TAST is the principal driver of reliability while PIT provides essential anatomical grounding, and their combination yields the most stable multi-plane execution. These results indicate that aligning preoperative geometry with time-aligned intraoperative perception and translating that alignment into tokenized, constrained actions is an effective path toward robust, interpretable autonomy in orthopedic robotic surgery.
Towards Fair Large Language Model-based Recommender Systems without Costly Retraining
Jan 24, 2026Large Language Models (LLMs) have revolutionized Recommender Systems (RS) through advanced generative user modeling. However, LLM-based RS (LLM-RS) often inadvertently perpetuates bias present in the training data, leading to severe fairness issues. Addressing these fairness problems in LLM-RS faces two significant challenges. 1) Existing debiasing methods, designed for specific bias types, lack the generality to handle diverse or emerging biases in real-world applications. 2) Debiasing methods relying on retraining are computationally infeasible given the massive parameter scale of LLMs. To overcome these challenges, we propose FUDLR (Fast Unified Debiasing for LLM-RS). The core idea is to reformulate the debiasing problem as an efficient machine unlearning task with two stages. First, FUDLR identifies bias-inducing samples to unlearn through a novel bias-agnostic mask, optimized to balance fairness improvement with accuracy preservation. Its bias-agnostic design allows adaptability to various or co-existing biases simply by incorporating different fairness metrics. Second, FUDLR performs efficient debiasing by estimating and removing the influence of identified samples on model parameters. Extensive experiments demonstrate that FUDLR effectively and efficiently improves fairness while preserving recommendation accuracy, offering a practical path toward socially responsible LLM-RS. The code and data are available at https://github.com/JinLi-i/FUDLR.
Native Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
RcAE: Recursive Reconstruction Framework for Unsupervised Industrial Anomaly Detection
Dec 12, 2025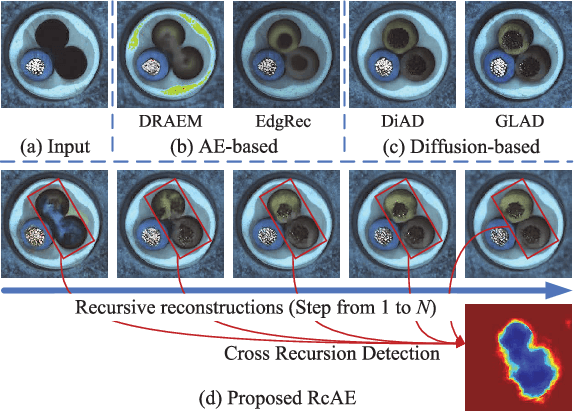
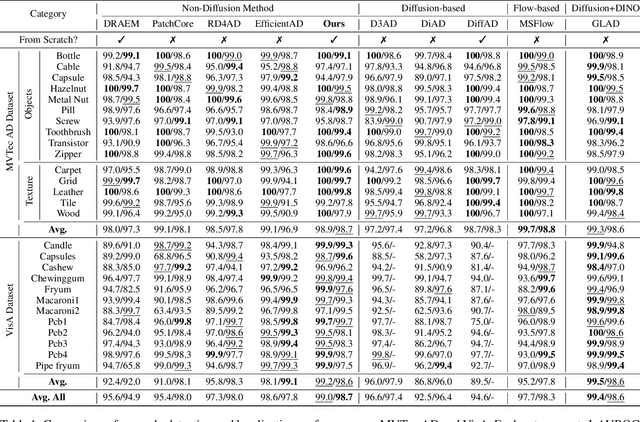
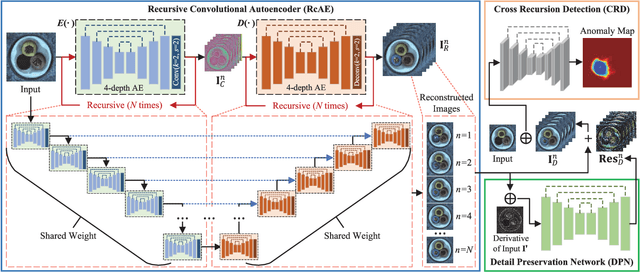
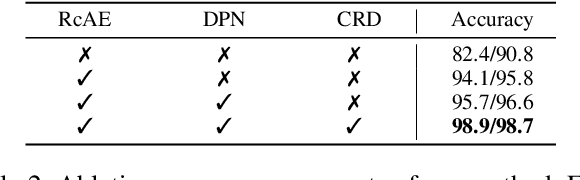
Unsupervised industrial anomaly detection requires accurately identifying defects without labeled data. Traditional autoencoder-based methods often struggle with incomplete anomaly suppression and loss of fine details, as their single-pass decoding fails to effectively handle anomalies with varying severity and scale. We propose a recursive architecture for autoencoder (RcAE), which performs reconstruction iteratively to progressively suppress anomalies while refining normal structures. Unlike traditional single-pass models, this recursive design naturally produces a sequence of reconstructions, progressively exposing suppressed abnormal patterns. To leverage this reconstruction dynamics, we introduce a Cross Recursion Detection (CRD) module that tracks inconsistencies across recursion steps, enhancing detection of both subtle and large-scale anomalies. Additionally, we incorporate a Detail Preservation Network (DPN) to recover high-frequency textures typically lost during reconstruction. Extensive experiments demonstrate that our method significantly outperforms existing non-diffusion methods, and achieves performance on par with recent diffusion models with only 10% of their parameters and offering substantially faster inference. These results highlight the practicality and efficiency of our approach for real-world applications.
A Survey of TinyML Applications in Beekeeping for Hive Monitoring and Management
Sep 10, 2025Honey bee colonies are essential for global food security and ecosystem stability, yet they face escalating threats from pests, diseases, and environmental stressors. Traditional hive inspections are labor-intensive and disruptive, while cloud-based monitoring solutions remain impractical for remote or resource-limited apiaries. Recent advances in Internet of Things (IoT) and Tiny Machine Learning (TinyML) enable low-power, real-time monitoring directly on edge devices, offering scalable and non-invasive alternatives. This survey synthesizes current innovations at the intersection of TinyML and apiculture, organized around four key functional areas: monitoring hive conditions, recognizing bee behaviors, detecting pests and diseases, and forecasting swarming events. We further examine supporting resources, including publicly available datasets, lightweight model architectures optimized for embedded deployment, and benchmarking strategies tailored to field constraints. Critical limitations such as data scarcity, generalization challenges, and deployment barriers in off-grid environments are highlighted, alongside emerging opportunities in ultra-efficient inference pipelines, adaptive edge learning, and dataset standardization. By consolidating research and engineering practices, this work provides a foundation for scalable, AI-driven, and ecologically informed monitoring systems to support sustainable pollinator management.
COME: Dual Structure-Semantic Learning with Collaborative MoE for Universal Lesion Detection Across Heterogeneous Ultrasound Datasets
Aug 13, 2025Conventional single-dataset training often fails with new data distributions, especially in ultrasound (US) image analysis due to limited data, acoustic shadows, and speckle noise. Therefore, constructing a universal framework for multi-heterogeneous US datasets is imperative. However, a key challenge arises: how to effectively mitigate inter-dataset interference while preserving dataset-specific discriminative features for robust downstream task? Previous approaches utilize either a single source-specific decoder or a domain adaptation strategy, but these methods experienced a decline in performance when applied to other domains. Considering this, we propose a Universal Collaborative Mixture of Heterogeneous Source-Specific Experts (COME). Specifically, COME establishes dual structure-semantic shared experts that create a universal representation space and then collaborate with source-specific experts to extract discriminative features through providing complementary features. This design enables robust generalization by leveraging cross-datasets experience distributions and providing universal US priors for small-batch or unseen data scenarios. Extensive experiments under three evaluation modes (single-dataset, intra-organ, and inter-organ integration datasets) demonstrate COME's superiority, achieving significant mean AP improvements over state-of-the-art methods. Our project is available at: https://universalcome.github.io/UniversalCOME/.