 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRNet: Integrating Constrained Graph-Based Reasoning with Pre-training for Diagnostic Medical Imaging
Nov 13, 2025Automated interpretation of medical images demands robust modeling of complex visual-semantic relationships while addressing annotation scarcity, label imbalance, and clinical plausibility constraints. We introduce MIRNet (Medical Image Reasoner Network), a novel framework that integrates self-supervised pre-training with constrained graph-based reasoning. Tongue image diagnosis is a particularly challenging domain that requires fine-grained visual and semantic understanding. Our approach leverages self-supervised masked autoencoder (MAE) to learn transferable visual representations from unlabeled data; employs graph attention networks (GAT) to model label correlations through expert-defined structured graphs; enforces clinical priors via constraint-aware optimization using KL divergence and regularization losses; and mitigates imbalance using asymmetric loss (ASL) and boosting ensembles. To address annotation scarcity, we also introduce TongueAtlas-4K, a comprehensive expert-curated benchmark comprising 4,000 images annotated with 22 diagnostic labels--representing the largest public dataset in tongue analysis. Validation shows our method achieves state-of-the-art performance. While optimized for tongue diagnosis, the framework readily generalizes to broader diagnostic medical imaging tasks.
A Survey on Enhancing Causal Reasoning Ability of Large Language Models
Mar 12, 2025Large language models (LLMs) have recently shown remarkable performance in language tasks and beyond. However, due to their limited inherent causal reasoning ability, LLMs still face challenges in handling tasks that require robust causal reasoning ability, such as health-care and economic analysis. As a result, a growing body of research has focused on enhancing the causal reasoning ability of LLMs. Despite the booming research, there lacks a survey to well review the challenges, progress and future directions in this area. To bridge this significant gap, we systematically review literature on how to strengthen LLMs' causal reasoning ability in this paper. We start from the introduction of background and motivations of this topic, followed by the summarisation of key challenges in this area. Thereafter, we propose a novel taxonomy to systematically categorise existing methods, together with detailed comparisons within and between classes of methods. Furthermore, we summarise existing benchmarks and evaluation metrics for assessing LLMs' causal reasoning ability. Finally, we outline future research directions for this emerging field, offering insights and inspiration to researchers and practitioners in the area.
Pathological Visual Question Answering
Oct 06, 2020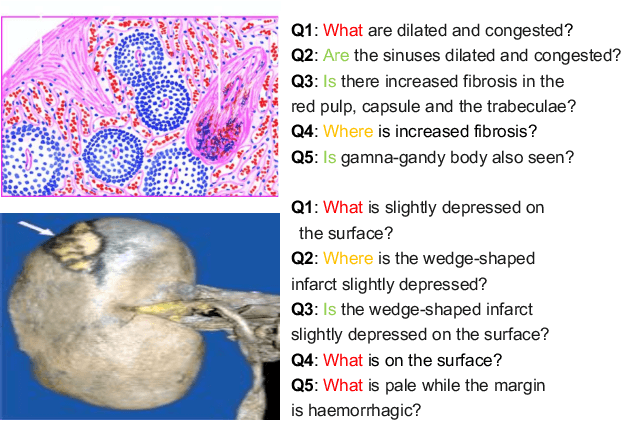
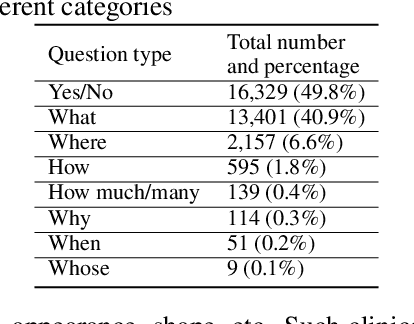
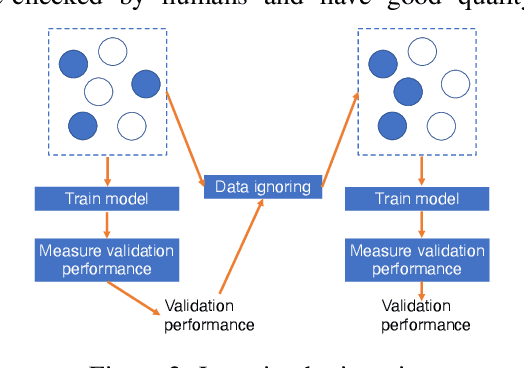
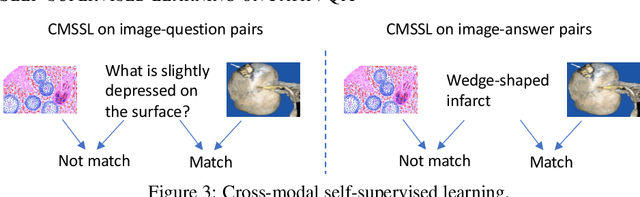
Is it possible to develop an "AI Pathologist" to pass the board-certified examination of the American Board of Pathology (ABP)? To build such a system, three challenges need to be addressed. First, we need to create a visual question answering (VQA) dataset where the AI agent is presented with a pathology image together with a question and is asked to give the correct answer. Due to privacy concerns, pathology images are usually not publicly available. Besides, only well-trained pathologists can understand pathology images, but they barely have time to help create datasets for AI research. The second challenge is: since it is difficult to hire highly experienced pathologists to create pathology visual questions and answers, the resulting pathology VQA dataset may contain errors. Training pathology VQA models using these noisy or even erroneous data will lead to problematic models that cannot generalize well on unseen images. The third challenge is: the medical concepts and knowledge covered in pathology question-answer (QA) pairs are very diverse while the number of QA pairs available for modeling training is limited. How to learn effective representations of diverse medical concepts based on limited data is technically demanding. In this paper, we aim to address these three challenges. To our best knowledge, our work represents the first one addressing the pathology VQA problem. To deal with the issue that a publicly available pathology VQA dataset is lacking, we create PathVQA dataset. To address the second challenge, we propose a learning-by-ignoring approach. To address the third challenge, we propose to use cross-modal self-supervised learning. We perform experiments on our created PathVQA dataset and the results demonstrate the effectiveness of our proposed learning-by-ignoring method and cross-modal self-supervised learning methods.