 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Federated Learning for Livestock Growth Prediction
Apr 01, 2026Livestock growth prediction is essential for optimising farm management and improving the efficiency and sustainability of livestock production, yet it remains underexplored due to limited large-scale datasets and privacy concerns surrounding farm-level data. Existing biophysical models rely on fixed formulations, while most machine learning approaches are trained on small, isolated datasets, limiting their robustness and generalisability. To address these challenges, we propose LivestockFL, the first federated learning framework specifically designed for livestock growth prediction. LivestockFL enables collaborative model training across distributed farms without sharing raw data, thereby preserving data privacy while alleviating data sparsity, particularly for farms with limited historical records. The framework employs a neural architecture based on a Gated Recurrent Unit combined with a multilayer perceptron to model temporal growth patterns from historical weight records and auxiliary features. We further introduce LivestockPFL, a novel personalised federated learning framework that extends the above federated learning framework with a personalized prediction head trained on each farm's local data, producing farm-specific predictors. Experiments on a real-world dataset demonstrate the effectiveness and practicality of the proposed approaches.
Towards Fair Large Language Model-based Recommender Systems without Costly Retraining
Jan 24, 2026Large Language Models (LLMs) have revolutionized Recommender Systems (RS) through advanced generative user modeling. However, LLM-based RS (LLM-RS) often inadvertently perpetuates bias present in the training data, leading to severe fairness issues. Addressing these fairness problems in LLM-RS faces two significant challenges. 1) Existing debiasing methods, designed for specific bias types, lack the generality to handle diverse or emerging biases in real-world applications. 2) Debiasing methods relying on retraining are computationally infeasible given the massive parameter scale of LLMs. To overcome these challenges, we propose FUDLR (Fast Unified Debiasing for LLM-RS). The core idea is to reformulate the debiasing problem as an efficient machine unlearning task with two stages. First, FUDLR identifies bias-inducing samples to unlearn through a novel bias-agnostic mask, optimized to balance fairness improvement with accuracy preservation. Its bias-agnostic design allows adaptability to various or co-existing biases simply by incorporating different fairness metrics. Second, FUDLR performs efficient debiasing by estimating and removing the influence of identified samples on model parameters. Extensive experiments demonstrate that FUDLR effectively and efficiently improves fairness while preserving recommendation accuracy, offering a practical path toward socially responsible LLM-RS. The code and data are available at https://github.com/JinLi-i/FUDLR.
DTRec: Learning Dynamic Reasoning Trajectories for Sequential Recommendation
Dec 16, 2025

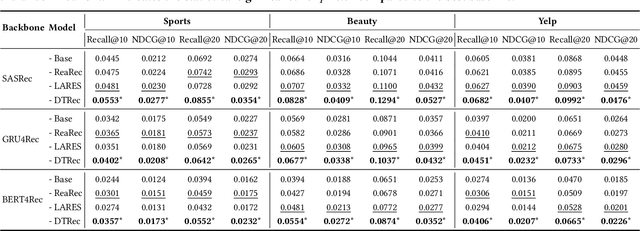

Inspired by advances in LLMs, reasoning-enhanced sequential recommendation performs multi-step deliberation before making final predictions, unlocking greater potential for capturing user preferences. However, current methods are constrained by static reasoning trajectories that are ill-suited for the diverse complexity of user behaviors. They suffer from two key limitations: (1) a static reasoning direction, which uses flat supervision signals misaligned with human-like hierarchical reasoning, and (2) a fixed reasoning depth, which inefficiently applies the same computational effort to all users, regardless of pattern complexity. These rigidity lead to suboptimal performance and significant computational waste. To overcome these challenges, we propose DTRec, a novel and effective framework that explores the Dynamic reasoning Trajectory for Sequential Recommendation along both direction and depth. To guide the direction, we develop Hierarchical Process Supervision (HPS), which provides coarse-to-fine supervisory signals to emulate the natural, progressive refinement of human cognitive processes. To optimize the depth, we introduce the Adaptive Reasoning Halting (ARH) mechanism that dynamically adjusts the number of reasoning steps by jointly monitoring three indicators. Extensive experiments on three real-world datasets demonstrate the superiority of our approach, achieving up to a 24.5% performance improvement over strong baselines while simultaneously reducing computational cost by up to 41.6%.
A Survey on Progress in LLM Alignment from the Perspective of Reward Design
May 05, 2025The alignment of large language models (LLMs) with human values and intentions represents a core challenge in current AI research, where reward mechanism design has become a critical factor in shaping model behavior. This study conducts a comprehensive investigation of reward mechanisms in LLM alignment through a systematic theoretical framework, categorizing their development into three key phases: (1) feedback (diagnosis), (2) reward design (prescription), and (3) optimization (treatment). Through a four-dimensional analysis encompassing construction basis, format, expression, and granularity, this research establishes a systematic classification framework that reveals evolutionary trends in reward modeling. The field of LLM alignment faces several persistent challenges, while recent advances in reward design are driving significant paradigm shifts. Notable developments include the transition from reinforcement learning-based frameworks to novel optimization paradigms, as well as enhanced capabilities to address complex alignment scenarios involving multimodal integration and concurrent task coordination. Finally, this survey outlines promising future research directions for LLM alignment through innovative reward design strategies.
A Survey on Enhancing Causal Reasoning Ability of Large Language Models
Mar 12, 2025Large language models (LLMs) have recently shown remarkable performance in language tasks and beyond. However, due to their limited inherent causal reasoning ability, LLMs still face challenges in handling tasks that require robust causal reasoning ability, such as health-care and economic analysis. As a result, a growing body of research has focused on enhancing the causal reasoning ability of LLMs. Despite the booming research, there lacks a survey to well review the challenges, progress and future directions in this area. To bridge this significant gap, we systematically review literature on how to strengthen LLMs' causal reasoning ability in this paper. We start from the introduction of background and motivations of this topic, followed by the summarisation of key challenges in this area. Thereafter, we propose a novel taxonomy to systematically categorise existing methods, together with detailed comparisons within and between classes of methods. Furthermore, we summarise existing benchmarks and evaluation metrics for assessing LLMs' causal reasoning ability. Finally, we outline future research directions for this emerging field, offering insights and inspiration to researchers and practitioners in the area.
A Macro- and Micro-Hierarchical Transfer Learning Framework for Cross-Domain Fake News Detection
Feb 20, 2025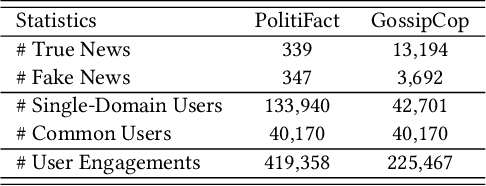
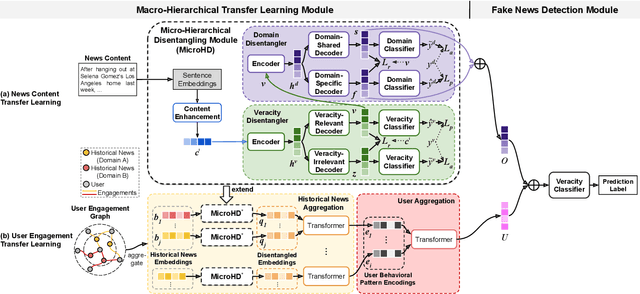
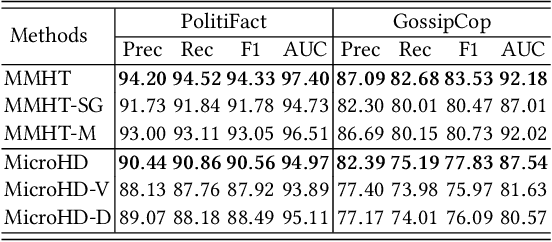
Cross-domain fake news detection aims to mitigate domain shift and improve detection performance by transferring knowledge across domains. Existing approaches transfer knowledge based on news content and user engagements from a source domain to a target domain. However, these approaches face two main limitations, hindering effective knowledge transfer and optimal fake news detection performance. Firstly, from a micro perspective, they neglect the negative impact of veracity-irrelevant features in news content when transferring domain-shared features across domains. Secondly, from a macro perspective, existing approaches ignore the relationship between user engagement and news content, which reveals shared behaviors of common users across domains and can facilitate more effective knowledge transfer. To address these limitations, we propose a novel macro- and micro- hierarchical transfer learning framework (MMHT) for cross-domain fake news detection. Firstly, we propose a micro-hierarchical disentangling module to disentangle veracity-relevant and veracity-irrelevant features from news content in the source domain for improving fake news detection performance in the target domain. Secondly, we propose a macro-hierarchical transfer learning module to generate engagement features based on common users' shared behaviors in different domains for improving effectiveness of knowledge transfer. Extensive experiments on real-world datasets demonstrate that our framework significantly outperforms the state-of-the-art baselines.
Generating with Fairness: A Modality-Diffused Counterfactual Framework for Incomplete Multimodal Recommendations
Jan 21, 2025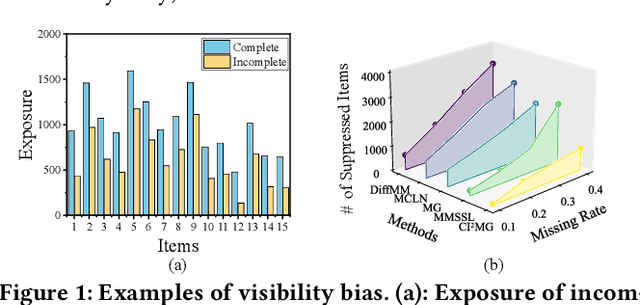
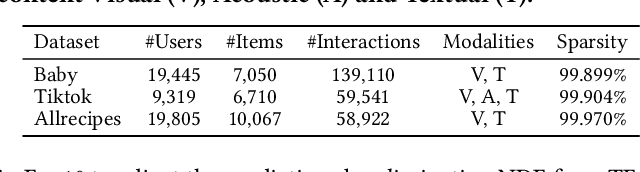
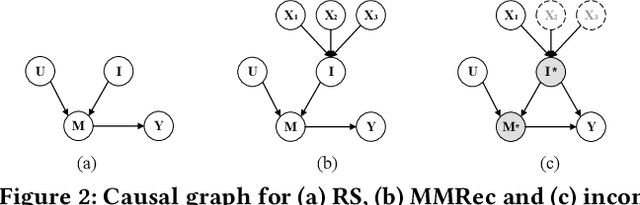
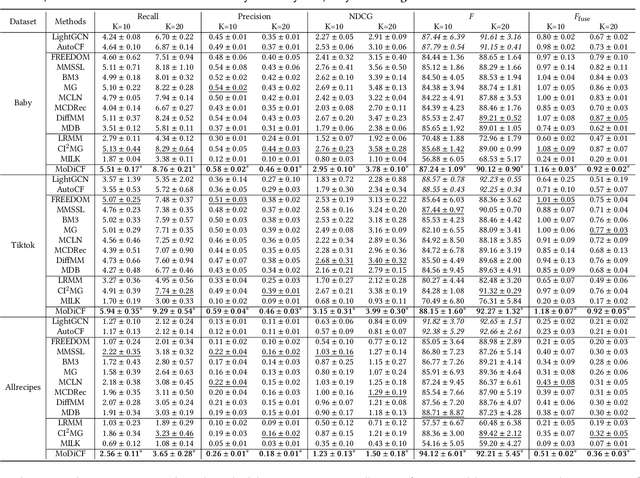
Incomplete scenario is a prevalent, practical, yet challenging setting in Multimodal Recommendations (MMRec), where some item modalities are missing due to various factors. Recently, a few efforts have sought to improve the recommendation accuracy by exploring generic structures from incomplete data. However, two significant gaps persist: 1) the difficulty in accurately generating missing data due to the limited ability to capture modality distributions; and 2) the critical but overlooked visibility bias, where items with missing modalities are more likely to be disregarded due to the prioritization of items' multimodal data over user preference alignment. This bias raises serious concerns about the fair treatment of items. To bridge these two gaps, we propose a novel Modality-Diffused Counterfactual (MoDiCF) framework for incomplete multimodal recommendations. MoDiCF features two key modules: a novel modality-diffused data completion module and a new counterfactual multimodal recommendation module. The former, equipped with a particularly designed multimodal generative framework, accurately generates and iteratively refines missing data from learned modality-specific distribution spaces. The latter, grounded in the causal perspective, effectively mitigates the negative causal effects of visibility bias and thus assures fairness in recommendations. Both modules work collaboratively to address the two aforementioned significant gaps for generating more accurate and fair results. Extensive experiments on three real-world datasets demonstrate the superior performance of MoDiCF in terms of both recommendation accuracy and fairness
Dual Contrastive Transformer for Hierarchical Preference Modeling in Sequential Recommendation
Oct 30, 2024



Sequential recommender systems (SRSs) aim to predict the subsequent items which may interest users via comprehensively modeling users' complex preference embedded in the sequence of user-item interactions. However, most of existing SRSs often model users' single low-level preference based on item ID information while ignoring the high-level preference revealed by item attribute information, such as item category. Furthermore, they often utilize limited sequence context information to predict the next item while overlooking richer inter-item semantic relations. To this end, in this paper, we proposed a novel hierarchical preference modeling framework to substantially model the complex low- and high-level preference dynamics for accurate sequential recommendation. Specifically, in the framework, a novel dual-transformer module and a novel dual contrastive learning scheme have been designed to discriminatively learn users' low- and high-level preference and to effectively enhance both low- and high-level preference learning respectively. In addition, a novel semantics-enhanced context embedding module has been devised to generate more informative context embedding for further improving the recommendation performance. Extensive experiments on six real-world datasets have demonstrated both the superiority of our proposed method over the state-of-the-art ones and the rationality of our design.
Modeling Temporal Positive and Negative Excitation for Sequential Recommendation
Oct 29, 2024



Sequential recommendation aims to predict the next item which interests users via modeling their interest in items over time. Most of the existing works on sequential recommendation model users' dynamic interest in specific items while overlooking users' static interest revealed by some static attribute information of items, e.g., category, or brand. Moreover, existing works often only consider the positive excitation of a user's historical interactions on his/her next choice on candidate items while ignoring the commonly existing negative excitation, resulting in insufficient modeling dynamic interest. The overlook of static interest and negative excitation will lead to incomplete interest modeling and thus impede the recommendation performance. To this end, in this paper, we propose modeling both static interest and negative excitation for dynamic interest to further improve the recommendation performance. Accordingly, we design a novel Static-Dynamic Interest Learning (SDIL) framework featured with a novel Temporal Positive and Negative Excitation Modeling (TPNE) module for accurate sequential recommendation. TPNE is specially designed for comprehensively modeling dynamic interest based on temporal positive and negative excitation learning. Extensive experiments on three real-world datasets show that SDIL can effectively capture both static and dynamic interest and outperforms state-of-the-art baselines.
NeuroClips: Towards High-fidelity and Smooth fMRI-to-Video Reconstruction
Oct 28, 2024Reconstruction of static visual stimuli from non-invasion brain activity fMRI achieves great success, owning to advanced deep learning models such as CLIP and Stable Diffusion. However, the research on fMRI-to-video reconstruction remains limited since decoding the spatiotemporal perception of continuous visual experiences is formidably challenging. We contend that the key to addressing these challenges lies in accurately decoding both high-level semantics and low-level perception flows, as perceived by the brain in response to video stimuli. To the end, we propose NeuroClips, an innovative framework to decode high-fidelity and smooth video from fMRI. NeuroClips utilizes a semantics reconstructor to reconstruct video keyframes, guiding semantic accuracy and consistency, and employs a perception reconstructor to capture low-level perceptual details, ensuring video smoothness. During inference, it adopts a pre-trained T2V diffusion model injected with both keyframes and low-level perception flows for video reconstruction. Evaluated on a publicly available fMRI-video dataset, NeuroClips achieves smooth high-fidelity video reconstruction of up to 6s at 8FPS, gaining significant improvements over state-of-the-art models in various metrics, e.g., a 128% improvement in SSIM and an 81% improvement in spatiotemporal metrics. Our project is available at https://github.com/gongzix/NeuroClips.