 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwordsman: Entropy-Driven Adaptive Block Partition for Efficient Diffusion Language Models
Feb 04, 2026Block-wise decoding effectively improves the inference speed and quality in diffusion language models (DLMs) by combining inter-block sequential denoising and intra-block parallel unmasking. However, existing block-wise decoding methods typically partition blocks in a rigid and fixed manner, which inevitably fragments complete semantic or syntactic constituents, leading to suboptimal performance. Inspired by the entropy reduction hypothesis (ERH), we recognize that constituent boundaries offer greater opportunities for uncertainty reduction, which motivates us to employ entropy analysis for identifying constituent boundaries. Therefore, we propose Swordsman, an entropy-driven adaptive block-wise decoding framework for DLMs. Swordsman adaptively partitions blocks by identifying entropy shifts between adjacent tokens to better align with semantic or syntactic constituent boundaries. In addition, Swordsman dynamically adjusts unmasking thresholds conditioned on the real-time unmasking status within a block, further improving both efficiency and stability. As a training-free framework, supported by KV Cache, Swordsman demonstrates state-of-the-art performance across extensive evaluations.
Adaptive Visual Autoregressive Acceleration via Dual-Linkage Entropy Analysis
Feb 01, 2026Visual AutoRegressive modeling (VAR) suffers from substantial computational cost due to the massive token count involved. Failing to account for the continuous evolution of modeling dynamics, existing VAR token reduction methods face three key limitations: heuristic stage partition, non-adaptive schedules, and limited acceleration scope, thereby leaving significant acceleration potential untapped. Since entropy variation intrinsically reflects the transition of predictive uncertainty, it offers a principled measure to capture modeling dynamics evolution. Therefore, we propose NOVA, a training-free token reduction acceleration framework for VAR models via entropy analysis. NOVA adaptively determines the acceleration activation scale during inference by online identifying the inflection point of scale entropy growth. Through scale-linkage and layer-linkage ratio adjustment, NOVA dynamically computes distinct token reduction ratios for each scale and layer, pruning low-entropy tokens while reusing the cache derived from the residuals at the prior scale to accelerate inference and maintain generation quality. Extensive experiments and analyses validate NOVA as a simple yet effective training-free acceleration framework.
Perception Activator: An intuitive and portable framework for brain cognitive exploration
Jul 03, 2025Recent advances in brain-vision decoding have driven significant progress, reconstructing with high fidelity perceived visual stimuli from neural activity, e.g., functional magnetic resonance imaging (fMRI), in the human visual cortex. Most existing methods decode the brain signal using a two-level strategy, i.e., pixel-level and semantic-level. However, these methods rely heavily on low-level pixel alignment yet lack sufficient and fine-grained semantic alignment, resulting in obvious reconstruction distortions of multiple semantic objects. To better understand the brain's visual perception patterns and how current decoding models process semantic objects, we have developed an experimental framework that uses fMRI representations as intervention conditions. By injecting these representations into multi-scale image features via cross-attention, we compare both downstream performance and intermediate feature changes on object detection and instance segmentation tasks with and without fMRI information. Our results demonstrate that incorporating fMRI signals enhances the accuracy of downstream detection and segmentation, confirming that fMRI contains rich multi-object semantic cues and coarse spatial localization information-elements that current models have yet to fully exploit or integrate.
Enhancing Text-to-Image Diffusion Transformer via Split-Text Conditioning
May 25, 2025Current text-to-image diffusion generation typically employs complete-text conditioning. Due to the intricate syntax, diffusion transformers (DiTs) inherently suffer from a comprehension defect of complete-text captions. One-fly complete-text input either overlooks critical semantic details or causes semantic confusion by simultaneously modeling diverse semantic primitive types. To mitigate this defect of DiTs, we propose a novel split-text conditioning framework named DiT-ST. This framework converts a complete-text caption into a split-text caption, a collection of simplified sentences, to explicitly express various semantic primitives and their interconnections. The split-text caption is then injected into different denoising stages of DiT-ST in a hierarchical and incremental manner. Specifically, DiT-ST leverages Large Language Models to parse captions, extracting diverse primitives and hierarchically sorting out and constructing these primitives into a split-text input. Moreover, we partition the diffusion denoising process according to its differential sensitivities to diverse semantic primitive types and determine the appropriate timesteps to incrementally inject tokens of diverse semantic primitive types into input tokens via cross-attention. In this way, DiT-ST enhances the representation learning of specific semantic primitive types across different stages. Extensive experiments validate the effectiveness of our proposed DiT-ST in mitigating the complete-text comprehension defect.
MindSimulator: Exploring Brain Concept Localization via Synthetic FMRI
Mar 04, 2025


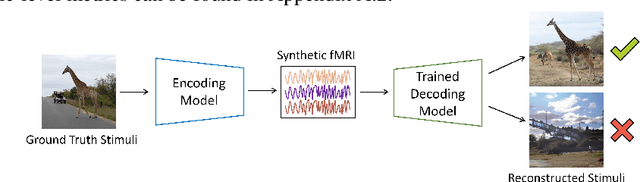
Concept-selective regions within the human cerebral cortex exhibit significant activation in response to specific visual stimuli associated with particular concepts. Precisely localizing these regions stands as a crucial long-term goal in neuroscience to grasp essential brain functions and mechanisms. Conventional experiment-driven approaches hinge on manually constructed visual stimulus collections and corresponding brain activity recordings, constraining the support and coverage of concept localization. Additionally, these stimuli often consist of concept objects in unnatural contexts and are potentially biased by subjective preferences, thus prompting concerns about the validity and generalizability of the identified regions. To address these limitations, we propose a data-driven exploration approach. By synthesizing extensive brain activity recordings, we statistically localize various concept-selective regions. Our proposed MindSimulator leverages advanced generative technologies to learn the probability distribution of brain activity conditioned on concept-oriented visual stimuli. This enables the creation of simulated brain recordings that reflect real neural response patterns. Using the synthetic recordings, we successfully localize several well-studied concept-selective regions and validate them against empirical findings, achieving promising prediction accuracy. The feasibility opens avenues for exploring novel concept-selective regions and provides prior hypotheses for future neuroscience research.
COSEE: Consistency-Oriented Signal-Based Early Exiting via Calibrated Sample Weighting Mechanism
Dec 17, 2024



Early exiting is an effective paradigm for improving the inference efficiency of pre-trained language models (PLMs) by dynamically adjusting the number of executed layers for each sample. However, in most existing works, easy and hard samples are treated equally by each classifier during training, which neglects the test-time early exiting behavior, leading to inconsistency between training and testing. Although some methods have tackled this issue under a fixed speed-up ratio, the challenge of flexibly adjusting the speed-up ratio while maintaining consistency between training and testing is still under-explored. To bridge the gap, we propose a novel Consistency-Oriented Signal-based Early Exiting (COSEE) framework, which leverages a calibrated sample weighting mechanism to enable each classifier to emphasize the samples that are more likely to exit at that classifier under various acceleration scenarios. Extensive experiments on the GLUE benchmark demonstrate the effectiveness of our COSEE across multiple exiting signals and backbones, yielding a better trade-off between performance and efficiency.
NeuroClips: Towards High-fidelity and Smooth fMRI-to-Video Reconstruction
Oct 28, 2024Reconstruction of static visual stimuli from non-invasion brain activity fMRI achieves great success, owning to advanced deep learning models such as CLIP and Stable Diffusion. However, the research on fMRI-to-video reconstruction remains limited since decoding the spatiotemporal perception of continuous visual experiences is formidably challenging. We contend that the key to addressing these challenges lies in accurately decoding both high-level semantics and low-level perception flows, as perceived by the brain in response to video stimuli. To the end, we propose NeuroClips, an innovative framework to decode high-fidelity and smooth video from fMRI. NeuroClips utilizes a semantics reconstructor to reconstruct video keyframes, guiding semantic accuracy and consistency, and employs a perception reconstructor to capture low-level perceptual details, ensuring video smoothness. During inference, it adopts a pre-trained T2V diffusion model injected with both keyframes and low-level perception flows for video reconstruction. Evaluated on a publicly available fMRI-video dataset, NeuroClips achieves smooth high-fidelity video reconstruction of up to 6s at 8FPS, gaining significant improvements over state-of-the-art models in various metrics, e.g., a 128% improvement in SSIM and an 81% improvement in spatiotemporal metrics. Our project is available at https://github.com/gongzix/NeuroClips.
FedMinds: Privacy-Preserving Personalized Brain Visual Decoding
Sep 03, 2024Exploring the mysteries of the human brain is a long-term research topic in neuroscience. With the help of deep learning, decoding visual information from human brain activity fMRI has achieved promising performance. However, these decoding models require centralized storage of fMRI data to conduct training, leading to potential privacy security issues. In this paper, we focus on privacy preservation in multi-individual brain visual decoding. To this end, we introduce a novel framework called FedMinds, which utilizes federated learning to protect individuals' privacy during model training. In addition, we deploy individual adapters for each subject, thus allowing personalized visual decoding. We conduct experiments on the authoritative NSD datasets to evaluate the performance of the proposed framework. The results demonstrate that our framework achieves high-precision visual decoding along with privacy protection.
Granular-Balls based Fuzzy Twin Support Vector Machine for Classification
Aug 01, 2024



The twin support vector machine (TWSVM) classifier has attracted increasing attention because of its low computational complexity. However, its performance tends to degrade when samples are affected by noise. The granular-ball fuzzy support vector machine (GBFSVM) classifier partly alleviates the adverse effects of noise, but it relies solely on the distance between the granular-ball's center and the class center to design the granular-ball membership function. In this paper, we first introduce the granular-ball twin support vector machine (GBTWSVM) classifier, which integrates granular-ball computing (GBC) with the twin support vector machine (TWSVM) classifier. By replacing traditional point inputs with granular-balls, we demonstrate how to derive a pair of non-parallel hyperplanes for the GBTWSVM classifier by solving a quadratic programming problem. Subsequently, we design the membership and non-membership functions of granular-balls using Pythagorean fuzzy sets to differentiate the contributions of granular-balls in various regions. Additionally, we develop the granular-ball fuzzy twin support vector machine (GBFTSVM) classifier by incorporating GBC with the fuzzy twin support vector machine (FTSVM) classifier. We demonstrate how to derive a pair of non-parallel hyperplanes for the GBFTSVM classifier by solving a quadratic programming problem. We also design algorithms for the GBTSVM classifier and the GBFTSVM classifier. Finally, the superior classification performance of the GBTWSVM classifier and the GBFTSVM classifier on 20 benchmark datasets underscores their scalability, efficiency, and robustness in tackling classification tasks.
MLIP: Efficient Multi-Perspective Language-Image Pretraining with Exhaustive Data Utilization
Jun 04, 2024



Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success, leading to rapid advancements in multimodal studies. However, CLIP faces a notable challenge in terms of inefficient data utilization. It relies on a single contrastive supervision for each image-text pair during representation learning, disregarding a substantial amount of valuable information that could offer richer supervision. Additionally, the retention of non-informative tokens leads to increased computational demands and time costs, particularly in CLIP's ViT image encoder. To address these issues, we propose Multi-Perspective Language-Image Pretraining (MLIP). In MLIP, we leverage the frequency transform's sensitivity to both high and low-frequency variations, which complements the spatial domain's sensitivity limited to low-frequency variations only. By incorporating frequency transforms and token-level alignment, we expand CILP's single supervision into multi-domain and multi-level supervision, enabling a more thorough exploration of informative image features. Additionally, we introduce a token merging method guided by comprehensive semantics from the frequency and spatial domains. This allows us to merge tokens to multi-granularity tokens with a controllable compression rate to accelerate CLIP. Extensive experiments validate the effectiveness of our design.