 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindSimulator: Exploring Brain Concept Localization via Synthetic FMRI
Mar 04, 2025


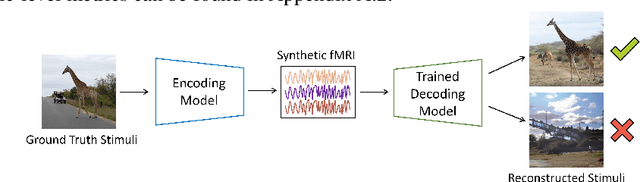
Concept-selective regions within the human cerebral cortex exhibit significant activation in response to specific visual stimuli associated with particular concepts. Precisely localizing these regions stands as a crucial long-term goal in neuroscience to grasp essential brain functions and mechanisms. Conventional experiment-driven approaches hinge on manually constructed visual stimulus collections and corresponding brain activity recordings, constraining the support and coverage of concept localization. Additionally, these stimuli often consist of concept objects in unnatural contexts and are potentially biased by subjective preferences, thus prompting concerns about the validity and generalizability of the identified regions. To address these limitations, we propose a data-driven exploration approach. By synthesizing extensive brain activity recordings, we statistically localize various concept-selective regions. Our proposed MindSimulator leverages advanced generative technologies to learn the probability distribution of brain activity conditioned on concept-oriented visual stimuli. This enables the creation of simulated brain recordings that reflect real neural response patterns. Using the synthetic recordings, we successfully localize several well-studied concept-selective regions and validate them against empirical findings, achieving promising prediction accuracy. The feasibility opens avenues for exploring novel concept-selective regions and provides prior hypotheses for future neuroscience research.
NeuroClips: Towards High-fidelity and Smooth fMRI-to-Video Reconstruction
Oct 28, 2024Reconstruction of static visual stimuli from non-invasion brain activity fMRI achieves great success, owning to advanced deep learning models such as CLIP and Stable Diffusion. However, the research on fMRI-to-video reconstruction remains limited since decoding the spatiotemporal perception of continuous visual experiences is formidably challenging. We contend that the key to addressing these challenges lies in accurately decoding both high-level semantics and low-level perception flows, as perceived by the brain in response to video stimuli. To the end, we propose NeuroClips, an innovative framework to decode high-fidelity and smooth video from fMRI. NeuroClips utilizes a semantics reconstructor to reconstruct video keyframes, guiding semantic accuracy and consistency, and employs a perception reconstructor to capture low-level perceptual details, ensuring video smoothness. During inference, it adopts a pre-trained T2V diffusion model injected with both keyframes and low-level perception flows for video reconstruction. Evaluated on a publicly available fMRI-video dataset, NeuroClips achieves smooth high-fidelity video reconstruction of up to 6s at 8FPS, gaining significant improvements over state-of-the-art models in various metrics, e.g., a 128% improvement in SSIM and an 81% improvement in spatiotemporal metrics. Our project is available at https://github.com/gongzix/NeuroClips.
FedMinds: Privacy-Preserving Personalized Brain Visual Decoding
Sep 03, 2024Exploring the mysteries of the human brain is a long-term research topic in neuroscience. With the help of deep learning, decoding visual information from human brain activity fMRI has achieved promising performance. However, these decoding models require centralized storage of fMRI data to conduct training, leading to potential privacy security issues. In this paper, we focus on privacy preservation in multi-individual brain visual decoding. To this end, we introduce a novel framework called FedMinds, which utilizes federated learning to protect individuals' privacy during model training. In addition, we deploy individual adapters for each subject, thus allowing personalized visual decoding. We conduct experiments on the authoritative NSD datasets to evaluate the performance of the proposed framework. The results demonstrate that our framework achieves high-precision visual decoding along with privacy protection.
Wills Aligner: A Robust Multi-Subject Brain Representation Learner
Apr 20, 2024



Decoding visual information from human brain activity has seen remarkable advancements in recent research. However, due to the significant variability in cortical parcellation and cognition patterns across subjects, current approaches personalized deep models for each subject, constraining the practicality of this technology in real-world contexts. To tackle the challenges, we introduce Wills Aligner, a robust multi-subject brain representation learner. Our Wills Aligner initially aligns different subjects' brains at the anatomical level. Subsequently, it incorporates a mixture of brain experts to learn individual cognition patterns. Additionally, it decouples the multi-subject learning task into a two-stage training, propelling the deep model and its plugin network to learn inter-subject commonality knowledge and various cognition patterns, respectively. Wills Aligner enables us to overcome anatomical differences and to efficiently leverage a single model for multi-subject brain representation learning. We meticulously evaluate the performance of our approach across coarse-grained and fine-grained visual decoding tasks. The experimental results demonstrate that our Wills Aligner achieves state-of-the-art performance.
MindTuner: Cross-Subject Visual Decoding with Visual Fingerprint and Semantic Correction
Apr 19, 2024



Decoding natural visual scenes from brain activity has flourished, with extensive research in single-subject tasks and, however, less in cross-subject tasks. Reconstructing high-quality images in cross-subject tasks is a challenging problem due to profound individual differences between subjects and the scarcity of data annotation. In this work, we proposed MindTuner for cross-subject visual decoding, which achieves high-quality and rich-semantic reconstructions using only 1 hour of fMRI training data benefiting from the phenomena of visual fingerprint in the human visual system and a novel fMRI-to-text alignment paradigm. Firstly, we pre-train a multi-subject model among 7 subjects and fine-tune it with scarce data on new subjects, where LoRAs with Skip-LoRAs are utilized to learn the visual fingerprint. Then, we take the image modality as the intermediate pivot modality to achieve fMRI-to-text alignment, which achieves impressive fMRI-to-text retrieval performance and corrects fMRI-to-image reconstruction with fine-tuned semantics. The results of both qualitative and quantitative analyses demonstrate that MindTuner surpasses state-of-the-art cross-subject visual decoding models on the Natural Scenes Dataset (NSD), whether using training data of 1 hour or 40 hours.
Multimodal Federated Learning with Missing Modality via Prototype Mask and Contrast
Dec 21, 2023
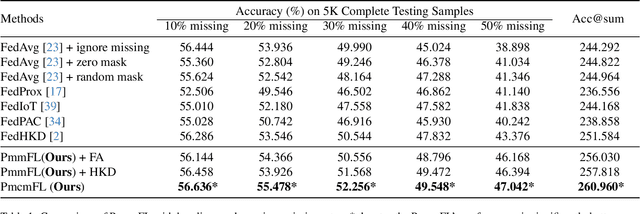
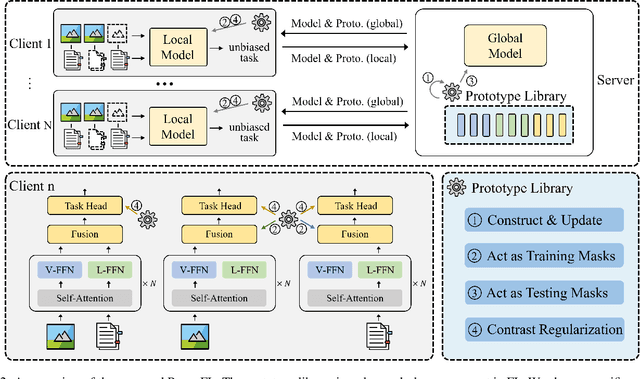
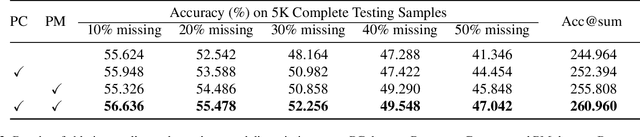
In real-world scenarios, multimodal federated learning often faces the practical challenge of intricate modality missing, which poses constraints on building federated frameworks and significantly degrades model inference accuracy. Existing solutions for addressing missing modalities generally involve developing modality-specific encoders on clients and training modality fusion modules on servers. However, these methods are primarily constrained to specific scenarios with either unimodal clients or complete multimodal clients, struggling to generalize effectively in the intricate modality missing scenarios. In this paper, we introduce a prototype library into the FedAvg-based Federated Learning framework, thereby empowering the framework with the capability to alleviate the global model performance degradation resulting from modality missing during both training and testing. The proposed method utilizes prototypes as masks representing missing modalities to formulate a task-calibrated training loss and a model-agnostic uni-modality inference strategy. In addition, a proximal term based on prototypes is constructed to enhance local training. Experimental results demonstrate the state-of-the-art performance of our approach. Compared to the baselines, our method improved inference accuracy by 3.7\% with 50\% modality missing during training and by 23.8\% during uni-modality inference. Code is available at https://github.com/BaoGuangYin/PmcmFL.
Lite-Mind: Towards Efficient and Versatile Brain Representation Network
Dec 06, 2023Research in decoding visual information from the brain, particularly through the non-invasive fMRI method, is rapidly progressing. The challenge arises from the limited data availability and the low signal-to-noise ratio of fMRI signals, leading to a low-precision task of fMRI-to-image retrieval. State-of-the-art MindEye remarkably improves fMRI-to-image retrieval performance by leveraging a deep MLP with a high parameter count orders of magnitude, i.e., a 996M MLP Backbone per subject, to align fMRI embeddings to the final hidden layer of CLIP's vision transformer. However, significant individual variations exist among subjects, even within identical experimental setups, mandating the training of subject-specific models. The substantial parameters pose significant challenges in deploying fMRI decoding on practical devices, especially with the necessitating of specific models for each subject. To this end, we propose Lite-Mind, a lightweight, efficient, and versatile brain representation network based on discrete Fourier transform, that efficiently aligns fMRI voxels to fine-grained information of CLIP. Our experiments demonstrate that Lite-Mind achieves an impressive 94.3% fMRI-to-image retrieval accuracy on the NSD dataset for Subject 1, with 98.7% fewer parameters than MindEye. Lite-Mind is also proven to be able to be migrated to smaller brain datasets and establishes a new state-of-the-art for zero-shot classification on the GOD dataset. The code is available at https://github.com/gongzix/Lite-Mind.