 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity is Combinatorial Depth: Quantifying MoE Expressivity via Tropical Geometry
Feb 03, 2026While Mixture-of-Experts (MoE) architectures define the state-of-the-art, their theoretical success is often attributed to heuristic efficiency rather than geometric expressivity. In this work, we present the first analysis of MoE through the lens of tropical geometry, establishing that the Top-$k$ routing mechanism is algebraically isomorphic to the $k$-th elementary symmetric tropical polynomial. This isomorphism partitions the input space into the Normal Fan of a Hypersimplex, revealing that \textbf{sparsity is combinatorial depth} which scales geometric capacity by the binomial coefficient $\binom{N}{k}$. Moving beyond ambient bounds, we introduce the concept of \textit{Effective Capacity} under the Manifold Hypothesis. We prove that while dense networks suffer from capacity collapse on low-dimensional data, MoE architectures exhibit \textit{Combinatorial Resilience}, maintaining high expressivity via the transversality of routing cones. In this study, our framework unifies the discrete geometry of the Hypersimplex with the continuous geometry of neural functions, offering a rigorous theoretical justification for the topological supremacy of conditional computation.
Effective Frontiers: A Unification of Neural Scaling Laws
Feb 01, 2026Neural scaling laws govern the prediction power-law improvement of test loss with respect to model capacity ($N$), datasize ($D$), and compute ($C$). However, existing theoretical explanations often rely on specific architectures or complex kernel methods, lacking intuitive universality. In this paper, we propose a unified framework that abstracts general learning tasks as the progressive coverage of patterns from a long-tail (Zipfian) distribution. We introduce the Effective Frontier ($k_\star$), a threshold in the pattern rank space that separates learned knowledge from the unlearned tail. We prove that reducible loss is asymptotically determined by the probability mass of the tail a resource-dependent frontier truncation. Based on our framework, we derive the precise scaling laws for $N$, $D$, and $C$, attributing them to capacity, coverage, and optimization bottlenecks, respectively. Furthermore, we unify these mechanisms via a Max-Bottleneck principle, demonstrating that the Kaplan and Chinchilla scaling laws are not contradictory, but equilibrium solutions to the same constrained optimization problem under different active bottlenecks.
Beyond the Black Box: Theory and Mechanism of Large Language Models
Jan 06, 2026The rapid emergence of Large Language Models (LLMs) has precipitated a profound paradigm shift in Artificial Intelligence, delivering monumental engineering successes that increasingly impact modern society. However, a critical paradox persists within the current field: despite the empirical efficacy, our theoretical understanding of LLMs remains disproportionately nascent, forcing these systems to be treated largely as ``black boxes''. To address this theoretical fragmentation, this survey proposes a unified lifecycle-based taxonomy that organizes the research landscape into six distinct stages: Data Preparation, Model Preparation, Training, Alignment, Inference, and Evaluation. Within this framework, we provide a systematic review of the foundational theories and internal mechanisms driving LLM performance. Specifically, we analyze core theoretical issues such as the mathematical justification for data mixtures, the representational limits of various architectures, and the optimization dynamics of alignment algorithms. Moving beyond current best practices, we identify critical frontier challenges, including the theoretical limits of synthetic data self-improvement, the mathematical bounds of safety guarantees, and the mechanistic origins of emergent intelligence. By connecting empirical observations with rigorous scientific inquiry, this work provides a structured roadmap for transitioning LLM development from engineering heuristics toward a principled scientific discipline.
MindSimulator: Exploring Brain Concept Localization via Synthetic FMRI
Mar 04, 2025


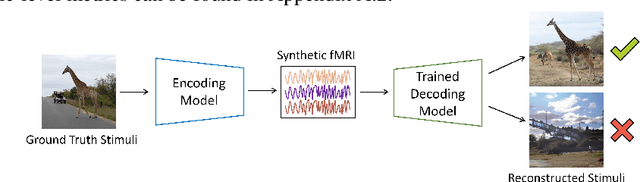
Concept-selective regions within the human cerebral cortex exhibit significant activation in response to specific visual stimuli associated with particular concepts. Precisely localizing these regions stands as a crucial long-term goal in neuroscience to grasp essential brain functions and mechanisms. Conventional experiment-driven approaches hinge on manually constructed visual stimulus collections and corresponding brain activity recordings, constraining the support and coverage of concept localization. Additionally, these stimuli often consist of concept objects in unnatural contexts and are potentially biased by subjective preferences, thus prompting concerns about the validity and generalizability of the identified regions. To address these limitations, we propose a data-driven exploration approach. By synthesizing extensive brain activity recordings, we statistically localize various concept-selective regions. Our proposed MindSimulator leverages advanced generative technologies to learn the probability distribution of brain activity conditioned on concept-oriented visual stimuli. This enables the creation of simulated brain recordings that reflect real neural response patterns. Using the synthetic recordings, we successfully localize several well-studied concept-selective regions and validate them against empirical findings, achieving promising prediction accuracy. The feasibility opens avenues for exploring novel concept-selective regions and provides prior hypotheses for future neuroscience research.
Disentangling Feature Structure: A Mathematically Provable Two-Stage Training Dynamics in Transformers
Feb 28, 2025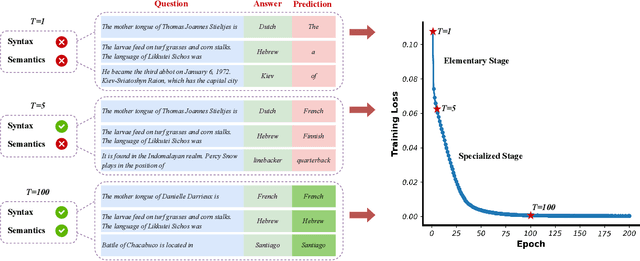

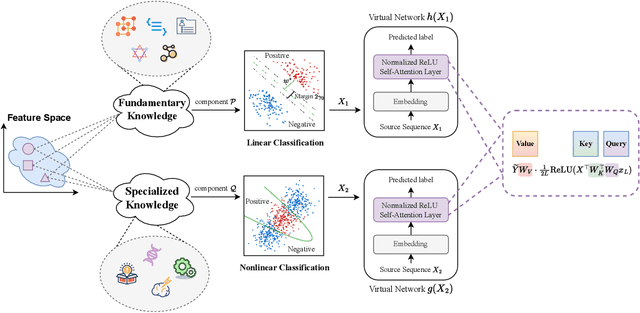
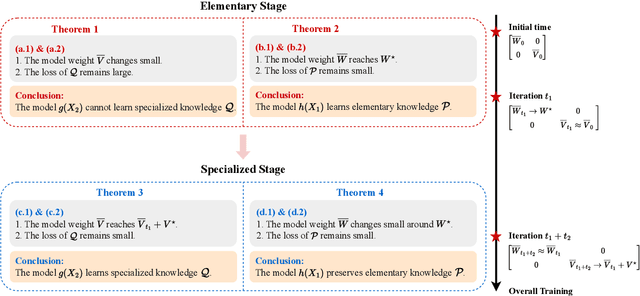
Transformers may exhibit two-stage training dynamics during the real-world training process. For instance, when training GPT-2 on the Counterfact dataset, the answers progress from syntactically incorrect to syntactically correct to semantically correct. However, existing theoretical analyses hardly account for this two-stage phenomenon. In this paper, we theoretically demonstrate how such two-stage training dynamics occur in transformers. Specifically, we analyze the dynamics of transformers using feature learning techniques under in-context learning regimes, based on a disentangled two-type feature structure. Such disentanglement of feature structure is general in practice, e.g., natural languages contain syntax and semantics, and proteins contain primary and secondary structures. To our best known, this is the first rigorous result regarding a two-stage optimization process in transformers. Additionally, a corollary indicates that such a two-stage process is closely related to the spectral properties of the attention weights, which accords well with empirical findings.
Towards Auto-Regressive Next-Token Prediction: In-Context Learning Emerges from Generalization
Feb 24, 2025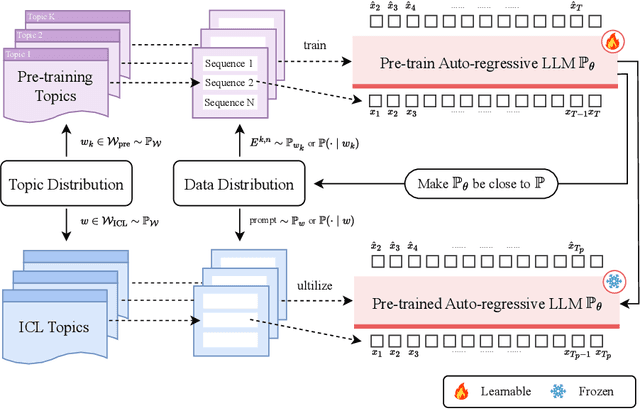



Large language models (LLMs) have demonstrated remarkable in-context learning (ICL) abilities. However, existing theoretical analysis of ICL primarily exhibits two limitations: (a) Limited i.i.d. Setting. Most studies focus on supervised function learning tasks where prompts are constructed with i.i.d. input-label pairs. This i.i.d. assumption diverges significantly from real language learning scenarios where prompt tokens are interdependent. (b) Lack of Emergence Explanation. Most literature answers what ICL does from an implicit optimization perspective but falls short in elucidating how ICL emerges and the impact of pre-training phase on ICL. In our paper, to extend (a), we adopt a more practical paradigm, auto-regressive next-token prediction (AR-NTP), which closely aligns with the actual training of language models. Specifically, within AR-NTP, we emphasize prompt token-dependency, which involves predicting each subsequent token based on the preceding sequence. To address (b), we formalize a systematic pre-training and ICL framework, highlighting the layer-wise structure of sequences and topics, alongside a two-level expectation. In conclusion, we present data-dependent, topic-dependent and optimization-dependent PAC-Bayesian generalization bounds for pre-trained LLMs, investigating that ICL emerges from the generalization of sequences and topics. Our theory is supported by experiments on numerical linear dynamic systems, synthetic GINC and real-world language datasets.
NeuroClips: Towards High-fidelity and Smooth fMRI-to-Video Reconstruction
Oct 28, 2024Reconstruction of static visual stimuli from non-invasion brain activity fMRI achieves great success, owning to advanced deep learning models such as CLIP and Stable Diffusion. However, the research on fMRI-to-video reconstruction remains limited since decoding the spatiotemporal perception of continuous visual experiences is formidably challenging. We contend that the key to addressing these challenges lies in accurately decoding both high-level semantics and low-level perception flows, as perceived by the brain in response to video stimuli. To the end, we propose NeuroClips, an innovative framework to decode high-fidelity and smooth video from fMRI. NeuroClips utilizes a semantics reconstructor to reconstruct video keyframes, guiding semantic accuracy and consistency, and employs a perception reconstructor to capture low-level perceptual details, ensuring video smoothness. During inference, it adopts a pre-trained T2V diffusion model injected with both keyframes and low-level perception flows for video reconstruction. Evaluated on a publicly available fMRI-video dataset, NeuroClips achieves smooth high-fidelity video reconstruction of up to 6s at 8FPS, gaining significant improvements over state-of-the-art models in various metrics, e.g., a 128% improvement in SSIM and an 81% improvement in spatiotemporal metrics. Our project is available at https://github.com/gongzix/NeuroClips.
MLIP: Efficient Multi-Perspective Language-Image Pretraining with Exhaustive Data Utilization
Jun 04, 2024



Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success, leading to rapid advancements in multimodal studies. However, CLIP faces a notable challenge in terms of inefficient data utilization. It relies on a single contrastive supervision for each image-text pair during representation learning, disregarding a substantial amount of valuable information that could offer richer supervision. Additionally, the retention of non-informative tokens leads to increased computational demands and time costs, particularly in CLIP's ViT image encoder. To address these issues, we propose Multi-Perspective Language-Image Pretraining (MLIP). In MLIP, we leverage the frequency transform's sensitivity to both high and low-frequency variations, which complements the spatial domain's sensitivity limited to low-frequency variations only. By incorporating frequency transforms and token-level alignment, we expand CILP's single supervision into multi-domain and multi-level supervision, enabling a more thorough exploration of informative image features. Additionally, we introduce a token merging method guided by comprehensive semantics from the frequency and spatial domains. This allows us to merge tokens to multi-granularity tokens with a controllable compression rate to accelerate CLIP. Extensive experiments validate the effectiveness of our design.
Wills Aligner: A Robust Multi-Subject Brain Representation Learner
Apr 20, 2024



Decoding visual information from human brain activity has seen remarkable advancements in recent research. However, due to the significant variability in cortical parcellation and cognition patterns across subjects, current approaches personalized deep models for each subject, constraining the practicality of this technology in real-world contexts. To tackle the challenges, we introduce Wills Aligner, a robust multi-subject brain representation learner. Our Wills Aligner initially aligns different subjects' brains at the anatomical level. Subsequently, it incorporates a mixture of brain experts to learn individual cognition patterns. Additionally, it decouples the multi-subject learning task into a two-stage training, propelling the deep model and its plugin network to learn inter-subject commonality knowledge and various cognition patterns, respectively. Wills Aligner enables us to overcome anatomical differences and to efficiently leverage a single model for multi-subject brain representation learning. We meticulously evaluate the performance of our approach across coarse-grained and fine-grained visual decoding tasks. The experimental results demonstrate that our Wills Aligner achieves state-of-the-art performance.
MindTuner: Cross-Subject Visual Decoding with Visual Fingerprint and Semantic Correction
Apr 19, 2024



Decoding natural visual scenes from brain activity has flourished, with extensive research in single-subject tasks and, however, less in cross-subject tasks. Reconstructing high-quality images in cross-subject tasks is a challenging problem due to profound individual differences between subjects and the scarcity of data annotation. In this work, we proposed MindTuner for cross-subject visual decoding, which achieves high-quality and rich-semantic reconstructions using only 1 hour of fMRI training data benefiting from the phenomena of visual fingerprint in the human visual system and a novel fMRI-to-text alignment paradigm. Firstly, we pre-train a multi-subject model among 7 subjects and fine-tune it with scarce data on new subjects, where LoRAs with Skip-LoRAs are utilized to learn the visual fingerprint. Then, we take the image modality as the intermediate pivot modality to achieve fMRI-to-text alignment, which achieves impressive fMRI-to-text retrieval performance and corrects fMRI-to-image reconstruction with fine-tuned semantics. The results of both qualitative and quantitative analyses demonstrate that MindTuner surpasses state-of-the-art cross-subject visual decoding models on the Natural Scenes Dataset (NSD), whether using training data of 1 hour or 40 hours.