 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwordsman: Entropy-Driven Adaptive Block Partition for Efficient Diffusion Language Models
Feb 04, 2026Block-wise decoding effectively improves the inference speed and quality in diffusion language models (DLMs) by combining inter-block sequential denoising and intra-block parallel unmasking. However, existing block-wise decoding methods typically partition blocks in a rigid and fixed manner, which inevitably fragments complete semantic or syntactic constituents, leading to suboptimal performance. Inspired by the entropy reduction hypothesis (ERH), we recognize that constituent boundaries offer greater opportunities for uncertainty reduction, which motivates us to employ entropy analysis for identifying constituent boundaries. Therefore, we propose Swordsman, an entropy-driven adaptive block-wise decoding framework for DLMs. Swordsman adaptively partitions blocks by identifying entropy shifts between adjacent tokens to better align with semantic or syntactic constituent boundaries. In addition, Swordsman dynamically adjusts unmasking thresholds conditioned on the real-time unmasking status within a block, further improving both efficiency and stability. As a training-free framework, supported by KV Cache, Swordsman demonstrates state-of-the-art performance across extensive evaluations.
FourierSampler: Unlocking Non-Autoregressive Potential in Diffusion Language Models via Frequency-Guided Generation
Jan 30, 2026Despite the non-autoregressive potential of diffusion language models (dLLMs), existing decoding strategies demonstrate positional bias, failing to fully unlock the potential of arbitrary generation. In this work, we delve into the inherent spectral characteristics of dLLMs and present the first frequency-domain analysis showing that low-frequency components in hidden states primarily encode global structural information and long-range dependencies, while high-frequency components are responsible for characterizing local details. Based on this observation, we propose FourierSampler, which leverages a frequency-domain sliding window mechanism to dynamically guide the model to achieve a "structure-to-detail" generation. FourierSampler outperforms other inference enhancement strategies on LLADA and SDAR, achieving relative improvements of 20.4% on LLaDA1.5-8B and 16.0% on LLaDA-8B-Instruct. It notably surpasses similarly sized autoregressive models like Llama3.1-8B-Instruct.
TriShGAN: Enhancing Sparsity and Robustness in Multivariate Time Series Counterfactuals Explanation
Nov 09, 2025In decision-making processes, stakeholders often rely on counterfactual explanations, which provide suggestions about what should be changed in the queried instance to alter the outcome of an AI system. However, generating these explanations for multivariate time series presents challenges due to their complex, multi-dimensional nature. Traditional Nearest Unlike Neighbor-based methods typically substitute subsequences in a queried time series with influential subsequences from an NUN, which is not always realistic in real-world scenarios due to the rigid direct substitution. Counterfactual with Residual Generative Adversarial Networks-based methods aim to address this by learning from the distribution of observed data to generate synthetic counterfactual explanations. However, these methods primarily focus on minimizing the cost from the queried time series to the counterfactual explanations and often neglect the importance of distancing the counterfactual explanation from the decision boundary. This oversight can result in explanations that no longer qualify as counterfactual if minor changes occur within the model. To generate a more robust counterfactual explanation, we introduce TriShGAN, under the CounteRGAN framework enhanced by the incorporation of triplet loss. This unsupervised learning approach uses distance metric learning to encourage the counterfactual explanations not only to remain close to the queried time series but also to capture the feature distribution of the instance with the desired outcome, thereby achieving a better balance between minimal cost and robustness. Additionally, we integrate a Shapelet Extractor that strategically selects the most discriminative parts of the high-dimensional queried time series to enhance the sparsity of counterfactual explanation and efficiency of the training process.
PMAT: Optimizing Action Generation Order in Multi-Agent Reinforcement Learning
Feb 23, 2025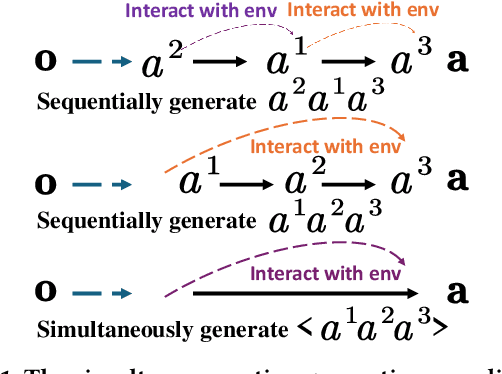
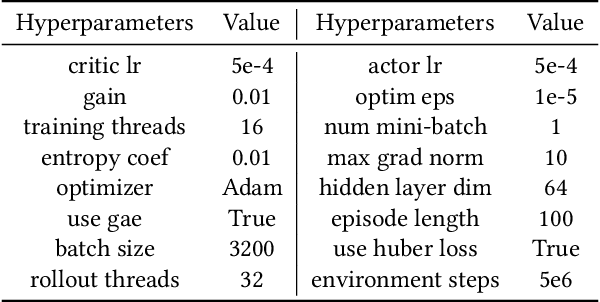
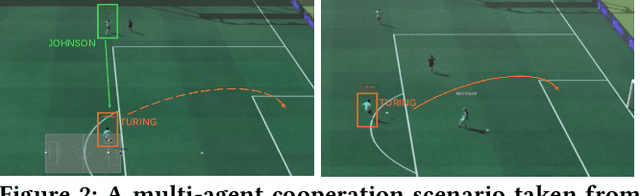
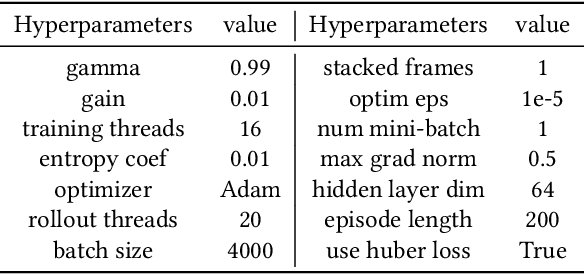
Multi-agent reinforcement learning (MARL) faces challenges in coordinating agents due to complex interdependencies within multi-agent systems. Most MARL algorithms use the simultaneous decision-making paradigm but ignore the action-level dependencies among agents, which reduces coordination efficiency. In contrast, the sequential decision-making paradigm provides finer-grained supervision for agent decision order, presenting the potential for handling dependencies via better decision order management. However, determining the optimal decision order remains a challenge. In this paper, we introduce Action Generation with Plackett-Luce Sampling (AGPS), a novel mechanism for agent decision order optimization. We model the order determination task as a Plackett-Luce sampling process to address issues such as ranking instability and vanishing gradient during the network training process. AGPS realizes credit-based decision order determination by establishing a bridge between the significance of agents' local observations and their decision credits, thus facilitating order optimization and dependency management. Integrating AGPS with the Multi-Agent Transformer, we propose the Prioritized Multi-Agent Transformer (PMAT), a sequential decision-making MARL algorithm with decision order optimization. Experiments on benchmarks including StarCraft II Multi-Agent Challenge, Google Research Football, and Multi-Agent MuJoCo show that PMAT outperforms state-of-the-art algorithms, greatly enhancing coordination efficiency.
Beyond Prior Limits: Addressing Distribution Misalignment in Particle Filtering
Jan 30, 2025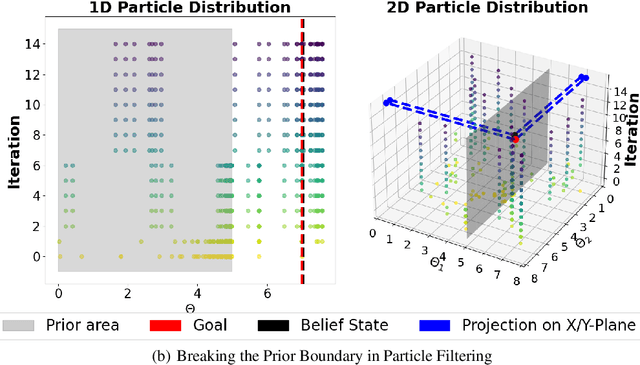
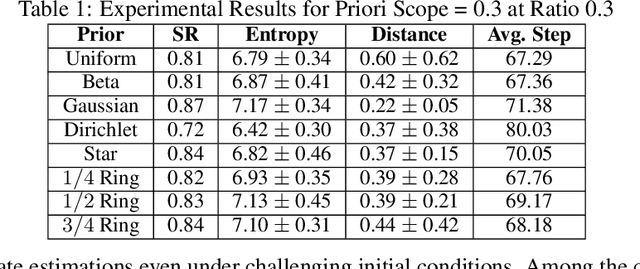
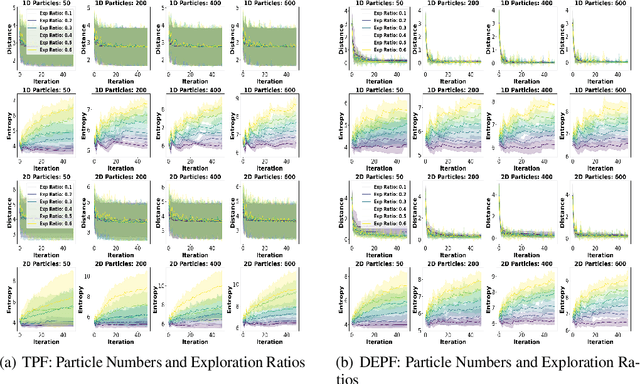
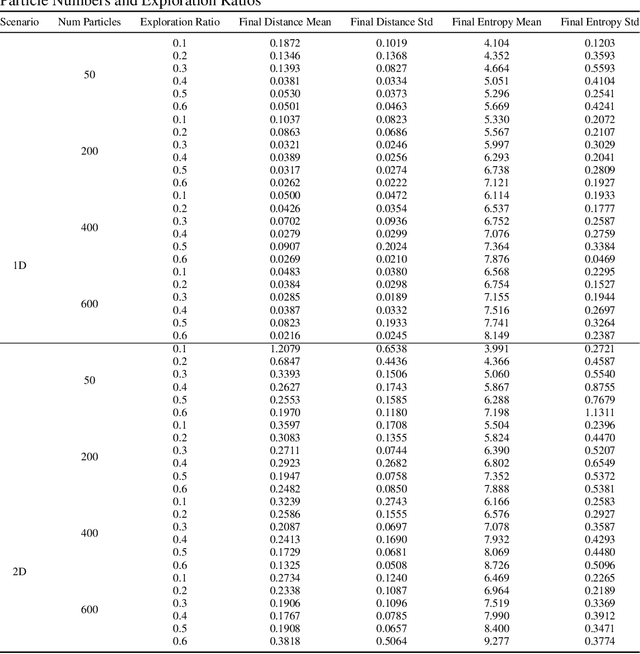
Particle filtering is a Bayesian inference method and a fundamental tool in state estimation for dynamic systems, but its effectiveness is often limited by the constraints of the initial prior distribution, a phenomenon we define as the Prior Boundary Phenomenon. This challenge arises when target states lie outside the prior's support, rendering traditional particle filtering methods inadequate for accurate estimation. Although techniques like unbounded priors and larger particle sets have been proposed, they remain computationally prohibitive and lack adaptability in dynamic scenarios. To systematically overcome these limitations, we propose the Diffusion-Enhanced Particle Filtering Framework, which introduces three key innovations: adaptive diffusion through exploratory particles, entropy-driven regularisation to prevent weight collapse, and kernel-based perturbations for dynamic support expansion. These mechanisms collectively enable particle filtering to explore beyond prior boundaries, ensuring robust state estimation for out-of-boundary targets. Theoretical analysis and extensive experiments validate framework's effectiveness, indicating significant improvements in success rates and estimation accuracy across high-dimensional and non-convex scenarios.
Autonomous Goal Detection and Cessation in Reinforcement Learning: A Case Study on Source Term Estimation
Sep 14, 2024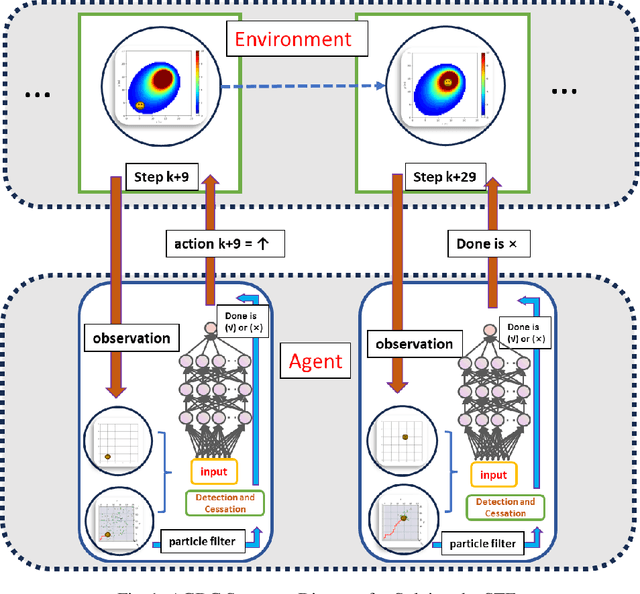
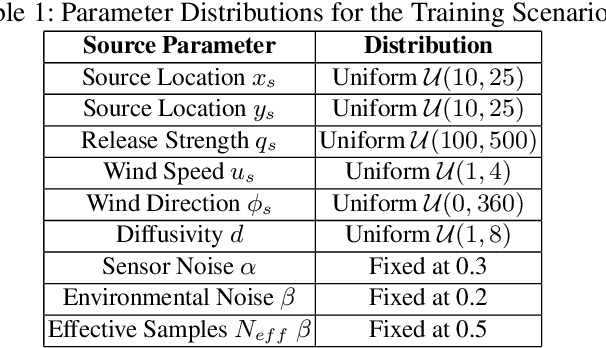
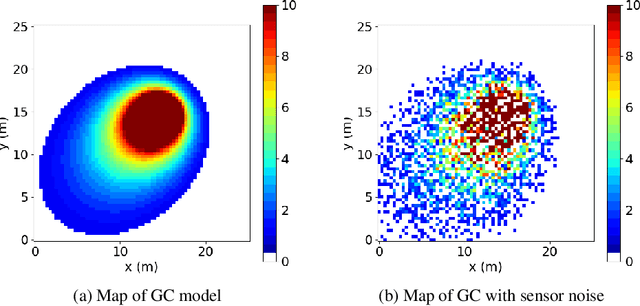
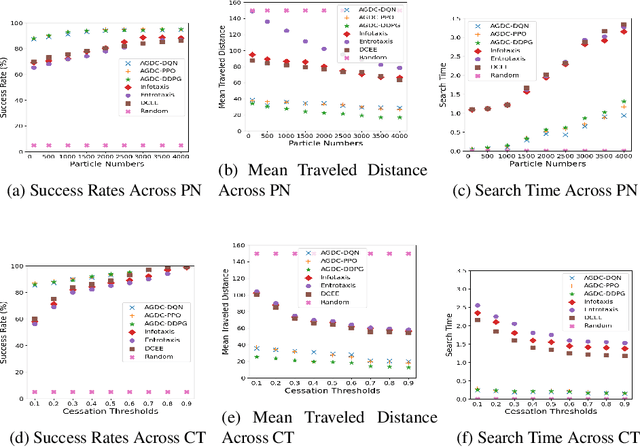
Reinforcement Learning has revolutionized decision-making processes in dynamic environments, yet it often struggles with autonomously detecting and achieving goals without clear feedback signals. For example, in a Source Term Estimation problem, the lack of precise environmental information makes it challenging to provide clear feedback signals and to define and evaluate how the source's location is determined. To address this challenge, the Autonomous Goal Detection and Cessation (AGDC) module was developed, enhancing various RL algorithms by incorporating a self-feedback mechanism for autonomous goal detection and cessation upon task completion. Our method effectively identifies and ceases undefined goals by approximating the agent's belief, significantly enhancing the capabilities of RL algorithms in environments with limited feedback. To validate effectiveness of our approach, we integrated AGDC with deep Q-Network, proximal policy optimization, and deep deterministic policy gradient algorithms, and evaluated its performance on the Source Term Estimation problem. The experimental results showed that AGDC-enhanced RL algorithms significantly outperformed traditional statistical methods such as infotaxis, entrotaxis, and dual control for exploitation and exploration, as well as a non-statistical random action selection method. These improvements were evident in terms of success rate, mean traveled distance, and search time, highlighting AGDC's effectiveness and efficiency in complex, real-world scenarios.
Explaining Reinforcement Learning: A Counterfactual Shapley Values Approach
Aug 06, 2024

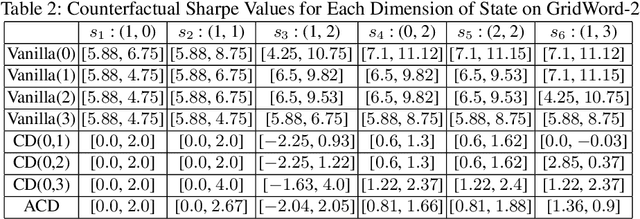

This paper introduces a novel approach Counterfactual Shapley Values (CSV), which enhances explainability in reinforcement learning (RL) by integrating counterfactual analysis with Shapley Values. The approach aims to quantify and compare the contributions of different state dimensions to various action choices. To more accurately analyze these impacts, we introduce new characteristic value functions, the ``Counterfactual Difference Characteristic Value" and the ``Average Counterfactual Difference Characteristic Value." These functions help calculate the Shapley values to evaluate the differences in contributions between optimal and non-optimal actions. Experiments across several RL domains, such as GridWorld, FrozenLake, and Taxi, demonstrate the effectiveness of the CSV method. The results show that this method not only improves transparency in complex RL systems but also quantifies the differences across various decisions.
MLIP: Efficient Multi-Perspective Language-Image Pretraining with Exhaustive Data Utilization
Jun 04, 2024



Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success, leading to rapid advancements in multimodal studies. However, CLIP faces a notable challenge in terms of inefficient data utilization. It relies on a single contrastive supervision for each image-text pair during representation learning, disregarding a substantial amount of valuable information that could offer richer supervision. Additionally, the retention of non-informative tokens leads to increased computational demands and time costs, particularly in CLIP's ViT image encoder. To address these issues, we propose Multi-Perspective Language-Image Pretraining (MLIP). In MLIP, we leverage the frequency transform's sensitivity to both high and low-frequency variations, which complements the spatial domain's sensitivity limited to low-frequency variations only. By incorporating frequency transforms and token-level alignment, we expand CILP's single supervision into multi-domain and multi-level supervision, enabling a more thorough exploration of informative image features. Additionally, we introduce a token merging method guided by comprehensive semantics from the frequency and spatial domains. This allows us to merge tokens to multi-granularity tokens with a controllable compression rate to accelerate CLIP. Extensive experiments validate the effectiveness of our design.