 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Harness: Harnesses That Improve Themselves
Jun 08, 2026The performance of LLM-based agents is jointly shaped by their base models and the harnesses that mediate their interaction with the environment. Because different models exhibit distinct behaviors, effective harness design is inherently model-specific. Yet agent harnesses are still largely engineered by human experts, a paradigm that scales poorly as modern LLMs become increasingly diverse and rapidly evolving. In this paper, we introduce Self-Harness, a new paradigm in which an LLM-based agent improves its own operating harness, without relying on human engineers or stronger external agents. We operationalize Self-Harness as an iterative loop with three stages: Weakness Mining, which identifies model-specific failure patterns from execution traces; Harness Proposal, which generates diverse yet minimal harness modifications tied to these failures; and Proposal Validation, which accepts candidate edits only after regression testing. We instantiate Self-Harness on Terminal-Bench-2.0 using a minimal initial harness and three base models from diverse families: MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5. Across all three models, Self-Harness consistently improves performance, with held-out pass rates increasing from 40.5% to 61.9%, 23.8% to 38.1%, and 42.9% to 57.1%, respectively. Qualitative analyses further show that Self-Harness does not simply add generic instructions, but effectively turns model-specific weaknesses into concrete, executable harness changes. These results suggest a path toward LLM-based agents that are not merely shaped by their harnesses, but can also participate in reshaping them.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025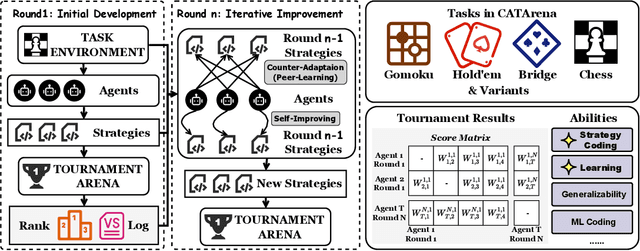

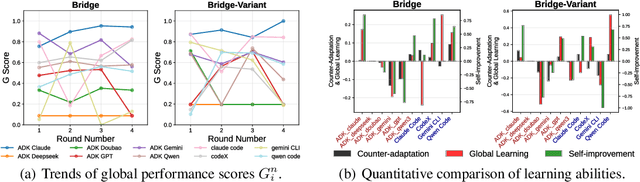
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
Audio Turing Test: Benchmarking the Human-likeness of Large Language Model-based Text-to-Speech Systems in Chinese
May 16, 2025Recent advances in large language models (LLMs) have significantly improved text-to-speech (TTS) systems, enhancing control over speech style, naturalness, and emotional expression, which brings TTS Systems closer to human-level performance. Although the Mean Opinion Score (MOS) remains the standard for TTS System evaluation, it suffers from subjectivity, environmental inconsistencies, and limited interpretability. Existing evaluation datasets also lack a multi-dimensional design, often neglecting factors such as speaking styles, context diversity, and trap utterances, which is particularly evident in Chinese TTS evaluation. To address these challenges, we introduce the Audio Turing Test (ATT), a multi-dimensional Chinese corpus dataset ATT-Corpus paired with a simple, Turing-Test-inspired evaluation protocol. Instead of relying on complex MOS scales or direct model comparisons, ATT asks evaluators to judge whether a voice sounds human. This simplification reduces rating bias and improves evaluation robustness. To further support rapid model development, we also finetune Qwen2-Audio-Instruct with human judgment data as Auto-ATT for automatic evaluation. Experimental results show that ATT effectively differentiates models across specific capability dimensions using its multi-dimensional design. Auto-ATT also demonstrates strong alignment with human evaluations, confirming its value as a fast and reliable assessment tool. The white-box ATT-Corpus and Auto-ATT can be found in ATT Hugging Face Collection (https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4).
PMAT: Optimizing Action Generation Order in Multi-Agent Reinforcement Learning
Feb 23, 2025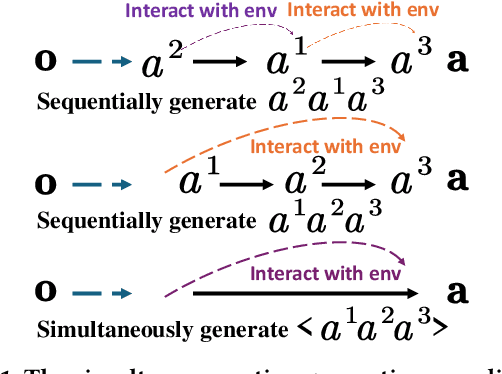
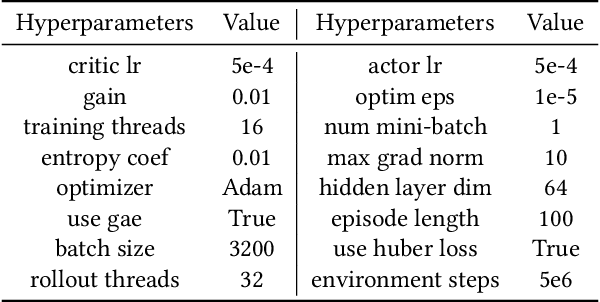
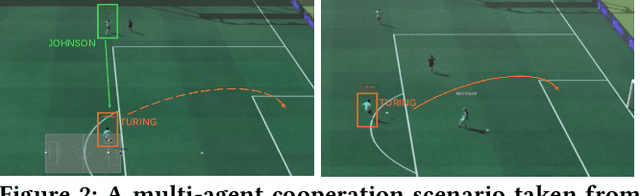
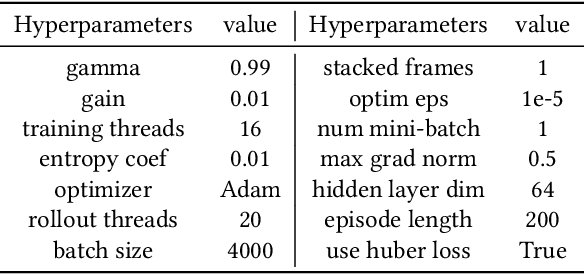
Multi-agent reinforcement learning (MARL) faces challenges in coordinating agents due to complex interdependencies within multi-agent systems. Most MARL algorithms use the simultaneous decision-making paradigm but ignore the action-level dependencies among agents, which reduces coordination efficiency. In contrast, the sequential decision-making paradigm provides finer-grained supervision for agent decision order, presenting the potential for handling dependencies via better decision order management. However, determining the optimal decision order remains a challenge. In this paper, we introduce Action Generation with Plackett-Luce Sampling (AGPS), a novel mechanism for agent decision order optimization. We model the order determination task as a Plackett-Luce sampling process to address issues such as ranking instability and vanishing gradient during the network training process. AGPS realizes credit-based decision order determination by establishing a bridge between the significance of agents' local observations and their decision credits, thus facilitating order optimization and dependency management. Integrating AGPS with the Multi-Agent Transformer, we propose the Prioritized Multi-Agent Transformer (PMAT), a sequential decision-making MARL algorithm with decision order optimization. Experiments on benchmarks including StarCraft II Multi-Agent Challenge, Google Research Football, and Multi-Agent MuJoCo show that PMAT outperforms state-of-the-art algorithms, greatly enhancing coordination efficiency.
Leveraging Dual Process Theory in Language Agent Framework for Real-time Simultaneous Human-AI Collaboration
Feb 17, 2025Agents built on large language models (LLMs) have excelled in turn-by-turn human-AI collaboration but struggle with simultaneous tasks requiring real-time interaction. Latency issues and the challenge of inferring variable human strategies hinder their ability to make autonomous decisions without explicit instructions. Through experiments with current independent System 1 and System 2 methods, we validate the necessity of using Dual Process Theory (DPT) in real-time tasks. We propose DPT-Agent, a novel language agent framework that integrates System 1 and System 2 for efficient real-time simultaneous human-AI collaboration. DPT-Agent's System 1 uses a Finite-state Machine (FSM) and code-as-policy for fast, intuitive, and controllable decision-making. DPT-Agent's System 2 integrates Theory of Mind (ToM) and asynchronous reflection to infer human intentions and perform reasoning-based autonomous decisions. We demonstrate the effectiveness of DPT-Agent through further experiments with rule-based agents and human collaborators, showing significant improvements over mainstream LLM-based frameworks. To the best of our knowledge, DPT-Agent is the first language agent framework that achieves successful real-time simultaneous human-AI collaboration autonomously. Code of DPT-Agent can be found in https://github.com/sjtu-marl/DPT-Agent.
Language Games as the Pathway to Artificial Superhuman Intelligence
Jan 31, 2025

The evolution of large language models (LLMs) toward artificial superhuman intelligence (ASI) hinges on data reproduction, a cyclical process in which models generate, curate and retrain on novel data to refine capabilities. Current methods, however, risk getting stuck in a data reproduction trap: optimizing outputs within fixed human-generated distributions in a closed loop leads to stagnation, as models merely recombine existing knowledge rather than explore new frontiers. In this paper, we propose language games as a pathway to expanded data reproduction, breaking this cycle through three mechanisms: (1) \textit{role fluidity}, which enhances data diversity and coverage by enabling multi-agent systems to dynamically shift roles across tasks; (2) \textit{reward variety}, embedding multiple feedback criteria that can drive complex intelligent behaviors; and (3) \textit{rule plasticity}, iteratively evolving interaction constraints to foster learnability, thereby injecting continual novelty. By scaling language games into global sociotechnical ecosystems, human-AI co-evolution generates unbounded data streams that drive open-ended exploration. This framework redefines data reproduction not as a closed loop but as an engine for superhuman intelligence.
Mutual Theory of Mind in Human-AI Collaboration: An Empirical Study with LLM-driven AI Agents in a Real-time Shared Workspace Task
Sep 13, 2024Theory of Mind (ToM) significantly impacts human collaboration and communication as a crucial capability to understand others. When AI agents with ToM capability collaborate with humans, Mutual Theory of Mind (MToM) arises in such human-AI teams (HATs). The MToM process, which involves interactive communication and ToM-based strategy adjustment, affects the team's performance and collaboration process. To explore the MToM process, we conducted a mixed-design experiment using a large language model-driven AI agent with ToM and communication modules in a real-time shared-workspace task. We find that the agent's ToM capability does not significantly impact team performance but enhances human understanding of the agent and the feeling of being understood. Most participants in our study believe verbal communication increases human burden, and the results show that bidirectional communication leads to lower HAT performance. We discuss the results' implications for designing AI agents that collaborate with humans in real-time shared workspace tasks.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024
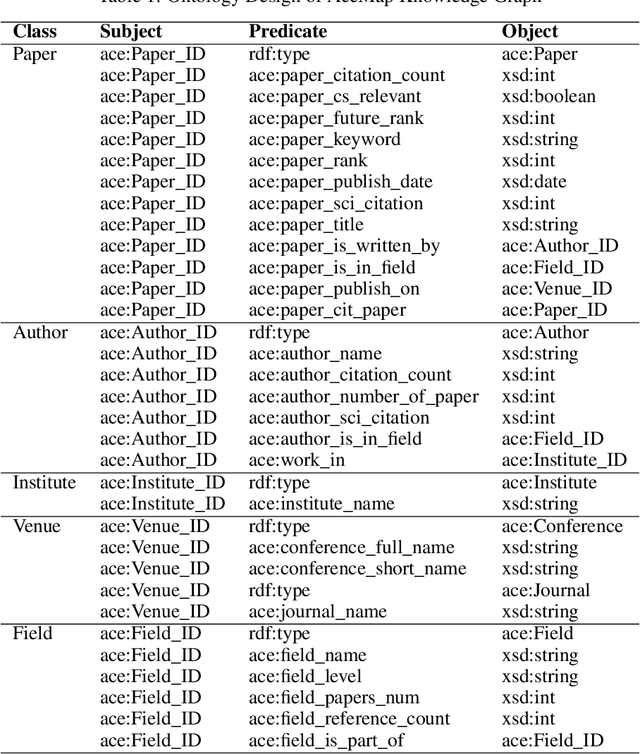
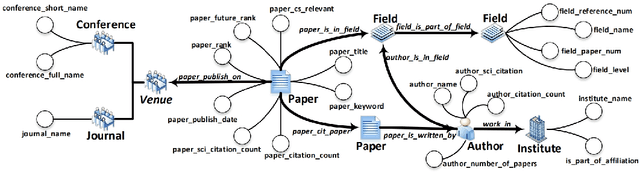
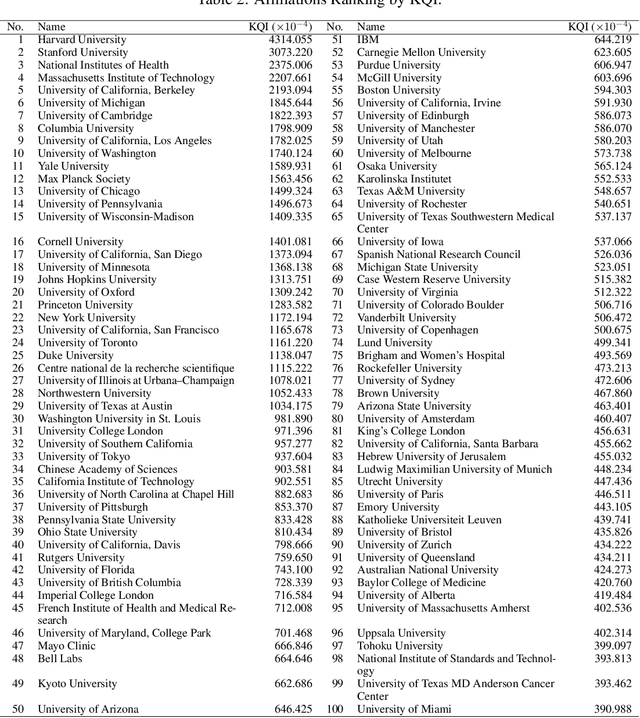
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
Aligning Individual and Collective Objectives in Multi-Agent Cooperation
Feb 19, 2024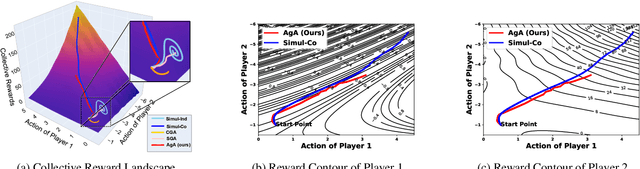
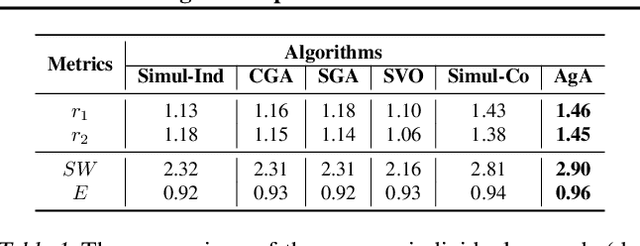
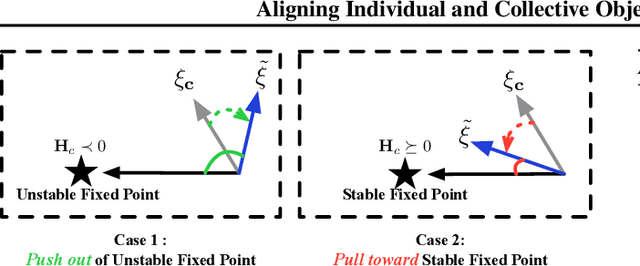
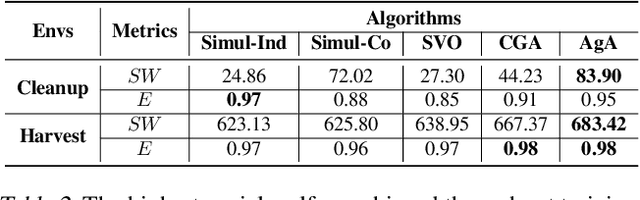
In the field of multi-agent learning, the challenge of mixed-motive cooperation is pronounced, given the inherent contradictions between individual and collective goals. Current research in this domain primarily focuses on incorporating domain knowledge into rewards or introducing additional mechanisms to foster cooperation. However, many of these methods suffer from the drawbacks of manual design costs and the lack of a theoretical grounding convergence procedure to the solution. To address this gap, we approach the mixed-motive game by modeling it as a differentiable game to study learning dynamics. We introduce a novel optimization method named Altruistic Gradient Adjustment (AgA) that employs gradient adjustments to novelly align individual and collective objectives. Furthermore, we provide theoretical proof that the selection of an appropriate alignment weight in AgA can accelerate convergence towards the desired solutions while effectively avoiding the undesired ones. The visualization of learning dynamics effectively demonstrates that AgA successfully achieves alignment between individual and collective objectives. Additionally, through evaluations conducted on established mixed-motive benchmarks such as the public good game, Cleanup, Harvest, and our modified mixed-motive SMAC environment, we validate AgA's capability to facilitate altruistic and fair collaboration.
Controlling Large Language Model-based Agents for Large-Scale Decision-Making: An Actor-Critic Approach
Nov 23, 2023



The significant advancements in large language models (LLMs) have presented novel opportunities for tackling planning and decision-making within multi-agent systems. However, as the number of agents increases, the issues of hallucination in LLMs and coordination in multi-agent systems (MAS) have become increasingly pronounced. Additionally, the efficient utilization of tokens becomes a critical consideration when employing LLMs to facilitate the interactions of large numbers of agents. In this paper, we present a novel framework aimed at enhancing coordination and decision-making capabilities of LLMs within large-scale multi-agent environments. Our approach draws inspiration from the actor-critic framework employed in multi-agent reinforcement learning, and we develop a modular and token-efficient solution that effectively addresses challenges presented by LLMs and MAS. Through evaluations conducted in experiments involving system resource allocation and robot grid transportation, we demonstrate the considerable advantages afforded by our proposed approach.