 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral365: Benchmarking General Reasoning in Large Language Models Across Diverse and Challenging Tasks
Apr 13, 2026Contemporary large language models (LLMs) have demonstrated remarkable reasoning capabilities, particularly in specialized domains like mathematics and physics. However, their ability to generalize these reasoning skills to more general and broader contexts--often termed general reasoning--remains under-explored. Unlike domain-specific reasoning, general reasoning relies less on expert knowledge but still presents formidable reasoning challenges, such as complex constraints, nested logical branches, and semantic interference. To address this gap, we introduce General365, a benchmark specifically designed to assess general reasoning in LLMs. By restricting background knowledge to a K-12 level, General365 explicitly decouples reasoning from specialized expertise. The benchmark comprises 365 seed problems and 1,095 variant problems across eight categories, ensuring both high difficulty and diversity. Evaluations across 26 leading LLMs reveal that even the top-performing model achieves only 62.8% accuracy, in stark contrast to the near-perfect performances of LLMs in math and physics benchmarks. These results suggest that the reasoning abilities of current LLMs are heavily domain-dependent, leaving significant room for improvement in broader applications. We envision General365 as a catalyst for advancing LLM reasoning beyond domain-specific tasks toward robust, general-purpose real-world scenarios. Code, Dataset, and Leaderboard: https://general365.github.io
LARY: A Latent Action Representation Yielding Benchmark for Generalizable Vision-to-Action Alignment
Apr 13, 2026While the shortage of explicit action data limits Vision-Language-Action (VLA) models, human action videos offer a scalable yet unlabeled data source. A critical challenge in utilizing large-scale human video datasets lies in transforming visual signals into ontology-independent representations, known as latent actions. However, the capacity of latent action representation to derive robust control from visual observations has yet to be rigorously evaluated. We introduce the Latent Action Representation Yielding (LARY) Benchmark, a unified framework for evaluating latent action representations on both high-level semantic actions (what to do) and low-level robotic control (how to do). The comprehensively curated dataset encompasses over one million videos (1,000 hours) spanning 151 action categories, alongside 620K image pairs and 595K motion trajectories across diverse embodiments and environments. Our experiments reveal two crucial insights: (i) General visual foundation models, trained without any action supervision, consistently outperform specialized embodied latent action models. (ii) Latent-based visual space is fundamentally better aligned to physical action space than pixel-based space. These results suggest that general visual representations inherently encode action-relevant knowledge for physical control, and that semantic-level abstraction serves as a fundamentally more effective pathway from vision to action than pixel-level reconstruction.
TR-ICRL: Test-Time Rethinking for In-Context Reinforcement Learning
Apr 01, 2026In-Context Reinforcement Learning (ICRL) enables Large Language Models (LLMs) to learn online from external rewards directly within the context window. However, a central challenge in ICRL is reward estimation, as models typically lack access to ground-truths during inference. To address this limitation, we propose Test-Time Rethinking for In-Context Reinforcement Learning (TR-ICRL), a novel ICRL framework designed for both reasoning and knowledge-intensive tasks. TR-ICRL operates by first retrieving the most relevant instances from an unlabeled evaluation set for a given query. During each ICRL iteration, LLM generates a set of candidate answers for every retrieved instance. Next, a pseudo-label is derived from this set through majority voting. This label then serves as a proxy to give reward messages and generate formative feedbacks, guiding LLM through iterative refinement. In the end, this synthesized contextual information is integrated with the original query to form a comprehensive prompt, with the answer determining through a final round of majority voting. TR-ICRL is evaluated on mainstream reasoning and knowledge-intensive tasks, where it demonstrates significant performance gains. Remarkably, TR-ICRL improves Qwen2.5-7B by 21.23% on average on MedQA and even 137.59% on AIME2024. Extensive ablation studies and analyses further validate the effectiveness and robustness of our approach. Our code is available at https://github.com/pangpang-xuan/TR_ICRL.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
Mar 22, 2026We introduce LongCat-Flash-Prover, a flagship 560-billion-parameter open-source Mixture-of- Experts (MoE) model that advances Native Formal Reasoning in Lean4 through agentic tool-integrated reasoning (TIR). We decompose the native formal reasoning task into three independent formal capabilities, i.e., auto-formalization, sketching, and proving. To facilitate these capabilities, we propose a Hybrid-Experts Iteration Framework to expand high-quality task trajectories, including generating a formal statement based on a given informal problem, producing a whole-proof directly from the statement, or a lemma-style sketch. During agentic RL, we present a Hierarchical Importance Sampling Policy Optimization (HisPO) algorithm, which aims to stabilize the MoE model training on such long-horizon tasks. It employs a gradient masking strategy that accounts for the policy staleness and the inherent train-inference engine discrepancies at both sequence and token levels. Additionally, we also incorporate theorem consistency and legality detection mechanisms to eliminate reward hacking issues. Extensive evaluations show that our LongCat-Flash-Prover sets a new state-of-the-art for open-weights models in both auto-formalization and theorem proving. Demonstrating remarkable sample efficiency, it achieves a 97.1% pass rate on MiniF2F-Test using only 72 inference budget per problem. On more challenging benchmarks, it solves 70.8% of ProverBench and 41.5% of PutnamBench with no more than 220 attempts per problem, significantly outperforming existing open-weights baselines.
AMemGym: Interactive Memory Benchmarking for Assistants in Long-Horizon Conversations
Mar 02, 2026Long-horizon interactions between users and LLM-based assistants necessitate effective memory management, yet current approaches face challenges in training and evaluation of memory. Existing memory benchmarks rely on static, off-policy data as context, limiting evaluation reliability and scalability. To address these gaps, we introduce AMemGym, an interactive environment enabling on-policy evaluation and optimization for memory-driven personalization. AMemGym employs structured data sampling to predefine user profiles, state-dependent questions, and state evolution trajectories, enabling cost-effective generation of high-quality, evaluation-aligned interactions. LLM-simulated users expose latent states through role-play while maintaining structured state consistency. Comprehensive metrics based on structured data guide both assessment and optimization of assistants. Extensive experiments reveal performance gaps in existing memory systems (e.g., RAG, long-context LLMs, and agentic memory) and corresponding reasons. AMemGym not only enables effective selection among competing approaches but also can potentially drive the self-evolution of memory management strategies. By bridging structured state evolution with free-form interactions, our framework provides a scalable, diagnostically rich environment for advancing memory capabilities in conversational agents.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
UniHetero: Could Generation Enhance Understanding for Vision-Language-Model at Large Data Scale?
Dec 30, 2025Vision-language large models are moving toward the unification of visual understanding and visual generation tasks. However, whether generation can enhance understanding is still under-explored on large data scale. In this work, we analysis the unified structure with a concise model, UniHetero, under large-scale pretraining (>200M samples). Our key observations are: (1) Generation can improve understanding, but Only if you generate Semantics, Not Pixels. A common assumption in unified vision-language models is that adding generation will naturally strengthen understanding. However, this is not always true at scale. At 200M+ pretraining samples, generation helps understanding only when it operates at the semantic level, i.e. when the model learns to autoregress high-level visual representations inside the LLM. Once pixel-level objectives (e.g., diffusion losses) directly interfere with the LLM, understanding performance often degrades. (2) Generation reveals a superior Data Scaling trend and higher Data Utilization. Unified generation-understanding demonstrates a superior scaling trend compared to understanding alone, revealing a more effective way to learn vision-only knowledge directive from vision modality rather than captioning to text. (3) Autoregression on Input Embedding is effective to capture visual details. Compared to the commonly-used vision encoder, make visual autoregression on input embedding shows less cumulative error and is modality independent, which can be extend to all modalities. The learned semantic representations capture visual information such as objects, locations, shapes, and colors; further enable pixel-level image generation.
AMO-Bench: Large Language Models Still Struggle in High School Math Competitions
Oct 30, 2025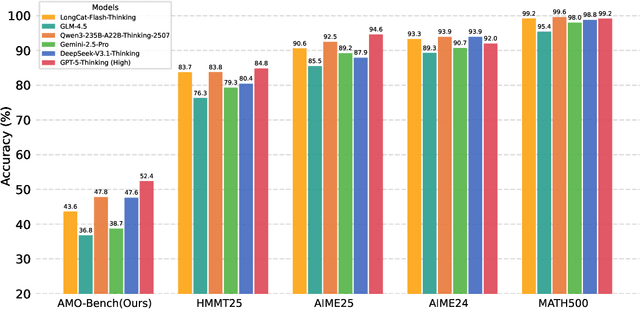
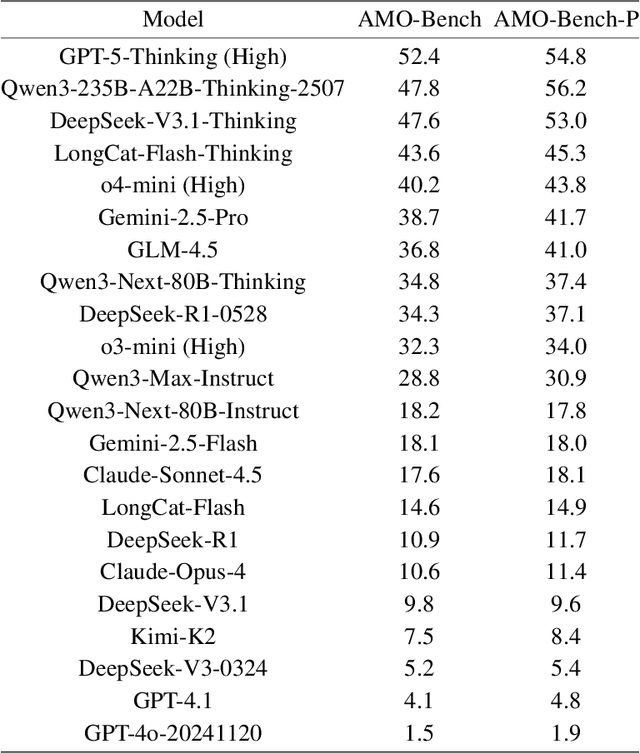
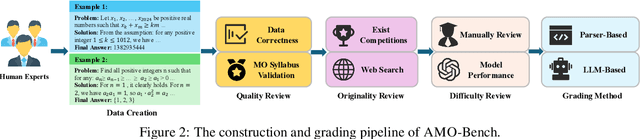
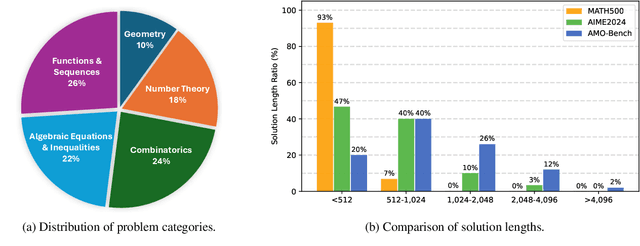
We present AMO-Bench, an Advanced Mathematical reasoning benchmark with Olympiad level or even higher difficulty, comprising 50 human-crafted problems. Existing benchmarks have widely leveraged high school math competitions for evaluating mathematical reasoning capabilities of large language models (LLMs). However, many existing math competitions are becoming less effective for assessing top-tier LLMs due to performance saturation (e.g., AIME24/25). To address this, AMO-Bench introduces more rigorous challenges by ensuring all 50 problems are (1) cross-validated by experts to meet at least the International Mathematical Olympiad (IMO) difficulty standards, and (2) entirely original problems to prevent potential performance leakages from data memorization. Moreover, each problem in AMO-Bench requires only a final answer rather than a proof, enabling automatic and robust grading for evaluation. Experimental results across 26 LLMs on AMO-Bench show that even the best-performing model achieves only 52.4% accuracy on AMO-Bench, with most LLMs scoring below 40%. Beyond these poor performances, our further analysis reveals a promising scaling trend with increasing test-time compute on AMO-Bench. These results highlight the significant room for improving the mathematical reasoning in current LLMs. We release AMO-Bench to facilitate further research into advancing the reasoning abilities of language models. https://amo-bench.github.io/
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025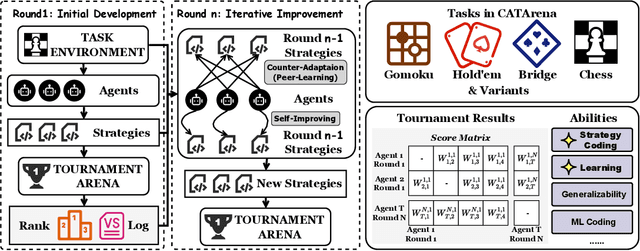

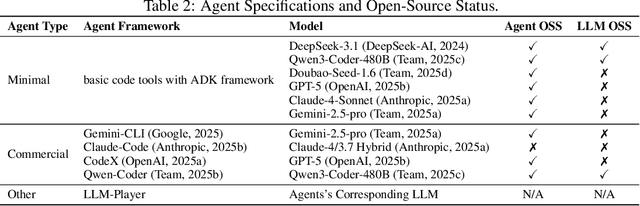
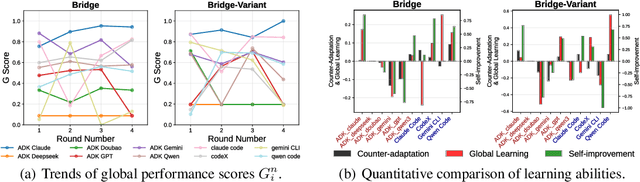
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.