 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViC-Bench: Benchmarking Visual-Interleaved Chain-of-Thought Capability in MLLMs with Free-Style Intermediate State Representations
May 20, 2025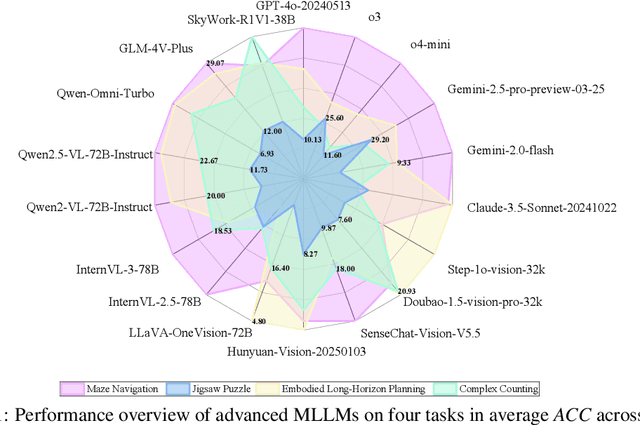

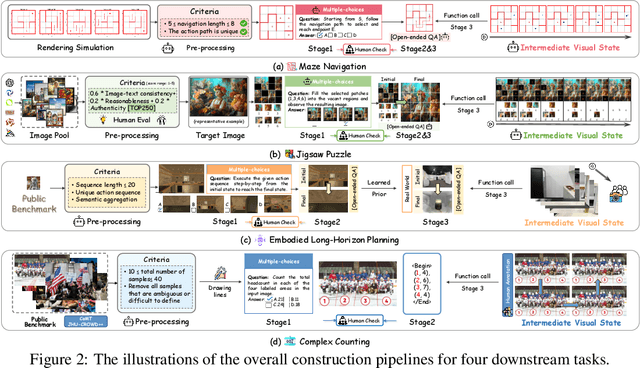
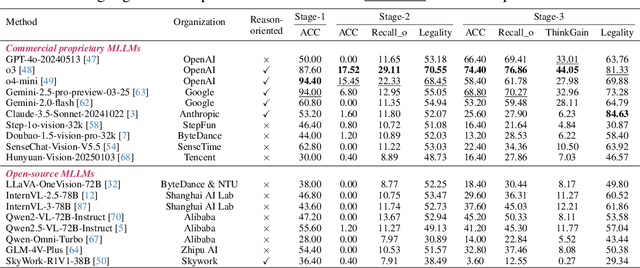
Visual-Interleaved Chain-of-Thought (VI-CoT) enables MLLMs to continually update their understanding and decisions based on step-wise intermediate visual states (IVS), much like a human would, which demonstrates impressive success in various tasks, thereby leading to emerged advancements in related benchmarks. Despite promising progress, current benchmarks provide models with relatively fixed IVS, rather than free-style IVS, whch might forcibly distort the original thinking trajectories, failing to evaluate their intrinsic reasoning capabilities. More importantly, existing benchmarks neglect to systematically explore the impact factors that IVS would impart to untamed reasoning performance. To tackle above gaps, we introduce a specialized benchmark termed ViC-Bench, consisting of four representive tasks: maze navigation, jigsaw puzzle, embodied long-horizon planning, and complex counting, where each task has dedicated free-style IVS generation pipeline supporting function calls. To systematically examine VI-CoT capability, we propose a thorough evaluation suite incorporating a progressive three-stage strategy with targeted new metrics. Besides, we establish Incremental Prompting Information Injection (IPII) strategy to ablatively explore the prompting factors for VI-CoT. We extensively conduct evaluations for 18 advanced MLLMs, revealing key insights into their VI-CoT capability. Our proposed benchmark is publicly open at Huggingface.
Talking Head Generation Driven by Speech-Related Facial Action Units and Audio- Based on Multimodal Representation Fusion
Apr 27, 2022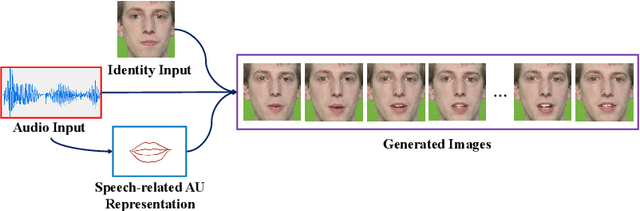
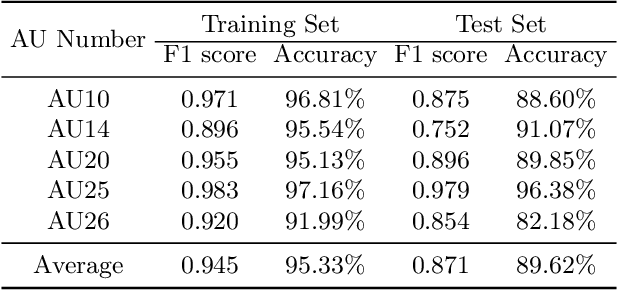
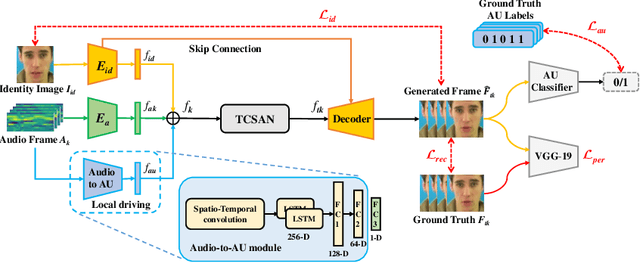

Talking head generation is to synthesize a lip-synchronized talking head video by inputting an arbitrary face image and corresponding audio clips. Existing methods ignore not only the interaction and relationship of cross-modal information, but also the local driving information of the mouth muscles. In this study, we propose a novel generative framework that contains a dilated non-causal temporal convolutional self-attention network as a multimodal fusion module to promote the relationship learning of cross-modal features. In addition, our proposed method uses both audio- and speech-related facial action units (AUs) as driving information. Speech-related AU information can guide mouth movements more accurately. Because speech is highly correlated with speech-related AUs, we propose an audio-to-AU module to predict speech-related AU information. We utilize pre-trained AU classifier to ensure that the generated images contain correct AU information. We verify the effectiveness of the proposed model on the GRID and TCD-TIMIT datasets. An ablation study is also conducted to verify the contribution of each component. The results of quantitative and qualitative experiments demonstrate that our method outperforms existing methods in terms of both image quality and lip-sync accuracy.
Talking Head Generation with Audio and Speech Related Facial Action Units
Oct 19, 2021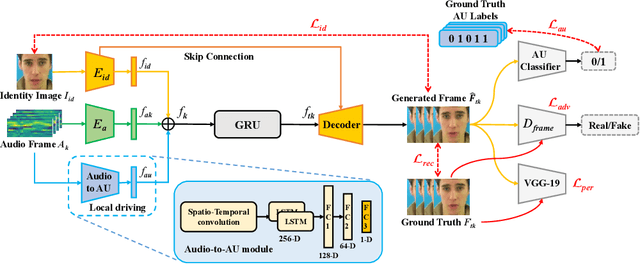
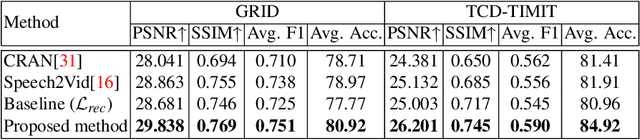


The task of talking head generation is to synthesize a lip synchronized talking head video by inputting an arbitrary face image and audio clips. Most existing methods ignore the local driving information of the mouth muscles. In this paper, we propose a novel recurrent generative network that uses both audio and speech-related facial action units (AUs) as the driving information. AU information related to the mouth can guide the movement of the mouth more accurately. Since speech is highly correlated with speech-related AUs, we propose an Audio-to-AU module in our system to predict the speech-related AU information from speech. In addition, we use AU classifier to ensure that the generated images contain correct AU information. Frame discriminator is also constructed for adversarial training to improve the realism of the generated face. We verify the effectiveness of our model on the GRID dataset and TCD-TIMIT dataset. We also conduct an ablation study to verify the contribution of each component in our model. Quantitative and qualitative experiments demonstrate that our method outperforms existing methods in both image quality and lip-sync accuracy.