 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware 3D Emotional Talking Face Synthesis with Emotion Prior Distillation
Jan 27, 2026Emotional Talking Face synthesis is pivotal in multimedia and signal processing, yet existing 3D methods suffer from two critical challenges: poor audio-vision emotion alignment, manifested as difficult audio emotion extraction and inadequate control over emotional micro-expressions; and a one-size-fits-all multi-view fusion strategy that overlooks uncertainty and feature quality differences, undermining rendering quality. We propose UA-3DTalk, Uncertainty-Aware 3D Emotional Talking Face Synthesis with emotion prior distillation, which has three core modules: the Prior Extraction module disentangles audio into content-synchronized features for alignment and person-specific complementary features for individualization; the Emotion Distillation module introduces a multi-modal attention-weighted fusion mechanism and 4D Gaussian encoding with multi-resolution code-books, enabling fine-grained audio emotion extraction and precise control of emotional micro-expressions; the Uncertainty-based Deformation deploys uncertainty blocks to estimate view-specific aleatoric (input noise) and epistemic (model parameters) uncertainty, realizing adaptive multi-view fusion and incorporating a multi-head decoder for Gaussian primitive optimization to mitigate the limitations of uniform-weight fusion. Extensive experiments on regular and emotional datasets show UA-3DTalk outperforms state-of-the-art methods like DEGSTalk and EDTalk by 5.2% in E-FID for emotion alignment, 3.1% in SyncC for lip synchronization, and 0.015 in LPIPS for rendering quality. Project page: https://mrask999.github.io/UA-3DTalk
NeRF-3DTalker: Neural Radiance Field with 3D Prior Aided Audio Disentanglement for Talking Head Synthesis
Feb 20, 2025Talking head synthesis is to synthesize a lip-synchronized talking head video using audio. Recently, the capability of NeRF to enhance the realism and texture details of synthesized talking heads has attracted the attention of researchers. However, most current NeRF methods based on audio are exclusively concerned with the rendering of frontal faces. These methods are unable to generate clear talking heads in novel views. Another prevalent challenge in current 3D talking head synthesis is the difficulty in aligning acoustic and visual spaces, which often results in suboptimal lip-syncing of the generated talking heads. To address these issues, we propose Neural Radiance Field with 3D Prior Aided Audio Disentanglement for Talking Head Synthesis (NeRF-3DTalker). Specifically, the proposed method employs 3D prior information to synthesize clear talking heads with free views. Additionally, we propose a 3D Prior Aided Audio Disentanglement module, which is designed to disentangle the audio into two distinct categories: features related to 3D awarded speech movements and features related to speaking style. Moreover, to reposition the generated frames that are distant from the speaker's motion space in the real space, we have devised a local-global Standardized Space. This method normalizes the irregular positions in the generated frames from both global and local semantic perspectives. Through comprehensive qualitative and quantitative experiments, it has been demonstrated that our NeRF-3DTalker outperforms state-of-the-art in synthesizing realistic talking head videos, exhibiting superior image quality and lip synchronization. Project page: https://nerf-3dtalker.github.io/NeRF-3Dtalker.
Teacher-Student Network for Real-World Face Super-Resolution with Progressive Embedding of Edge Information
May 08, 2024



Traditional face super-resolution (FSR) methods trained on synthetic datasets usually have poor generalization ability for real-world face images. Recent work has utilized complex degradation models or training networks to simulate the real degradation process, but this limits the performance of these methods due to the domain differences that still exist between the generated low-resolution images and the real low-resolution images. Moreover, because of the existence of a domain gap, the semantic feature information of the target domain may be affected when synthetic data and real data are utilized to train super-resolution models simultaneously. In this study, a real-world face super-resolution teacher-student model is proposed, which considers the domain gap between real and synthetic data and progressively includes diverse edge information by using the recurrent network's intermediate outputs. Extensive experiments demonstrate that our proposed approach surpasses state-of-the-art methods in obtaining high-quality face images for real-world FSR.
NeRF-AD: Neural Radiance Field with Attention-based Disentanglement for Talking Face Synthesis
Jan 23, 2024Talking face synthesis driven by audio is one of the current research hotspots in the fields of multidimensional signal processing and multimedia. Neural Radiance Field (NeRF) has recently been brought to this research field in order to enhance the realism and 3D effect of the generated faces. However, most existing NeRF-based methods either burden NeRF with complex learning tasks while lacking methods for supervised multimodal feature fusion, or cannot precisely map audio to the facial region related to speech movements. These reasons ultimately result in existing methods generating inaccurate lip shapes. This paper moves a portion of NeRF learning tasks ahead and proposes a talking face synthesis method via NeRF with attention-based disentanglement (NeRF-AD). In particular, an Attention-based Disentanglement module is introduced to disentangle the face into Audio-face and Identity-face using speech-related facial action unit (AU) information. To precisely regulate how audio affects the talking face, we only fuse the Audio-face with audio feature. In addition, AU information is also utilized to supervise the fusion of these two modalities. Extensive qualitative and quantitative experiments demonstrate that our NeRF-AD outperforms state-of-the-art methods in generating realistic talking face videos, including image quality and lip synchronization. To view video results, please refer to https://xiaoxingliu02.github.io/NeRF-AD.
Self-supervised Facial Action Unit Detection with Region and Relation Learning
Mar 10, 2023



Facial action unit (AU) detection is a challenging task due to the scarcity of manual annotations. Recent works on AU detection with self-supervised learning have emerged to address this problem, aiming to learn meaningful AU representations from numerous unlabeled data. However, most existing AU detection works with self-supervised learning utilize global facial features only, while AU-related properties such as locality and relevance are not fully explored. In this paper, we propose a novel self-supervised framework for AU detection with the region and relation learning. In particular, AU related attention map is utilized to guide the model to focus more on AU-specific regions to enhance the integrity of AU local features. Meanwhile, an improved Optimal Transport (OT) algorithm is introduced to exploit the correlation characteristics among AUs. In addition, Swin Transformer is exploited to model the long-distance dependencies within each AU region during feature learning. The evaluation results on BP4D and DISFA demonstrate that our proposed method is comparable or even superior to the state-of-the-art self-supervised learning methods and supervised AU detection methods.
Face Super-Resolution with Progressive Embedding of Multi-scale Face Priors
Oct 12, 2022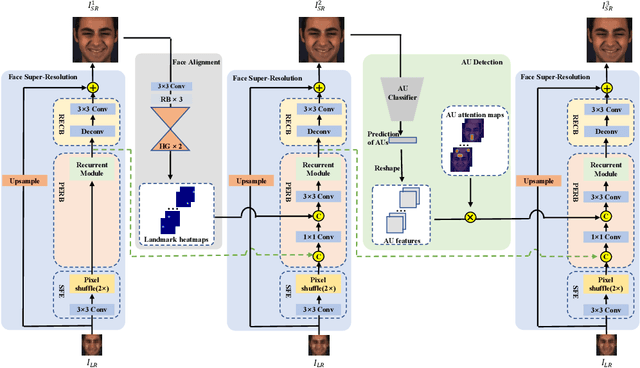
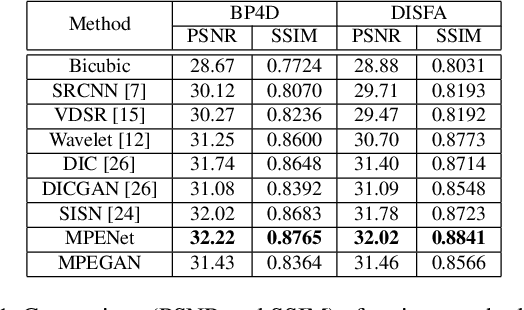

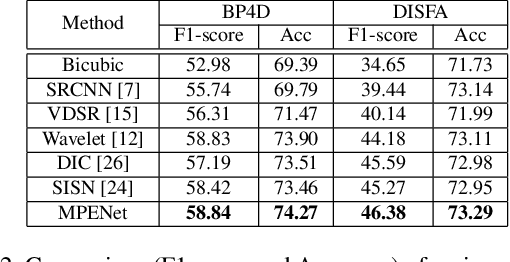
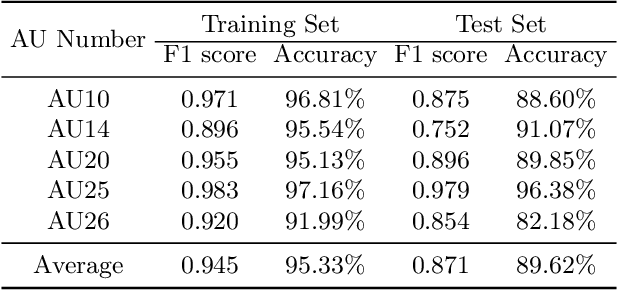
The face super-resolution (FSR) task is to reconstruct high-resolution face images from low-resolution inputs. Recent works have achieved success on this task by utilizing facial priors such as facial landmarks. Most existing methods pay more attention to global shape and structure information, but less to local texture information, which makes them cannot recover local details well. In this paper, we propose a novel recurrent convolutional network based framework for face super-resolution, which progressively introduces both global shape and local texture information. We take full advantage of the intermediate outputs of the recurrent network, and landmarks information and facial action units (AUs) information are extracted in the output of the first and second steps respectively, rather than low-resolution input. Moreover, we introduced AU classification results as a novel quantitative metric for facial details restoration. Extensive experiments show that our proposed method significantly outperforms state-of-the-art FSR methods in terms of image quality and facial details restoration.
Cross-subject Action Unit Detection with Meta Learning and Transformer-based Relation Modeling
May 18, 2022

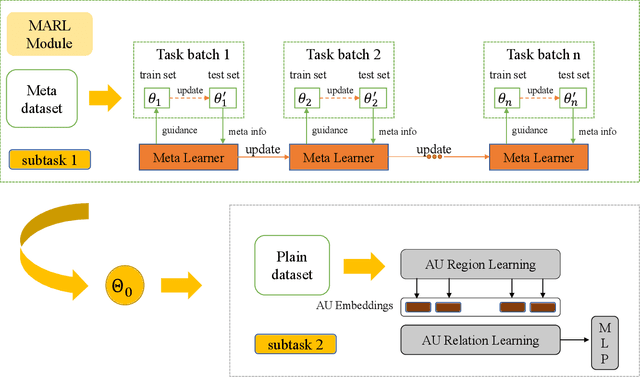
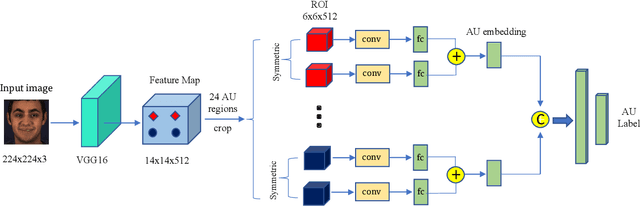
Facial Action Unit (AU) detection is a crucial task for emotion analysis from facial movements. The apparent differences of different subjects sometimes mislead changes brought by AUs, resulting in inaccurate results. However, most of the existing AU detection methods based on deep learning didn't consider the identity information of different subjects. The paper proposes a meta-learning-based cross-subject AU detection model to eliminate the identity-caused differences. Besides, a transformer-based relation learning module is introduced to learn the latent relations of multiple AUs. To be specific, our proposed work is composed of two sub-tasks. The first sub-task is meta-learning-based AU local region representation learning, called MARL, which learns discriminative representation of local AU regions that incorporates the shared information of multiple subjects and eliminates identity-caused differences. The second sub-task uses the local region representation of AU of the first sub-task as input, then adds relationship learning based on the transformer encoder architecture to capture AU relationships. The entire training process is cascaded. Ablation study and visualization show that our MARL can eliminate identity-caused differences, thus obtaining a robust and generalized AU discriminative embedding representation. Our results prove that on the two public datasets BP4D and DISFA, our method is superior to the state-of-the-art technology, and the F1 score is improved by 1.3% and 1.4%, respectively.
Talking Head Generation Driven by Speech-Related Facial Action Units and Audio- Based on Multimodal Representation Fusion
Apr 27, 2022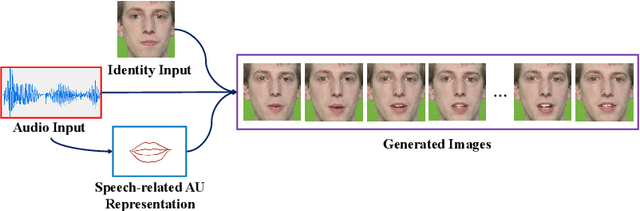
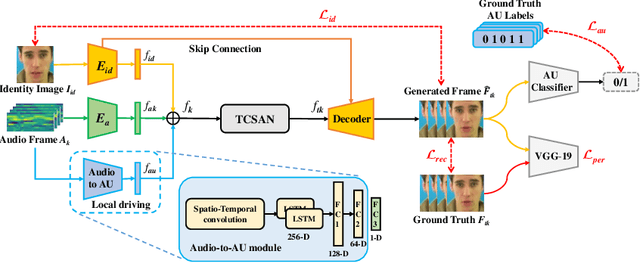

Talking head generation is to synthesize a lip-synchronized talking head video by inputting an arbitrary face image and corresponding audio clips. Existing methods ignore not only the interaction and relationship of cross-modal information, but also the local driving information of the mouth muscles. In this study, we propose a novel generative framework that contains a dilated non-causal temporal convolutional self-attention network as a multimodal fusion module to promote the relationship learning of cross-modal features. In addition, our proposed method uses both audio- and speech-related facial action units (AUs) as driving information. Speech-related AU information can guide mouth movements more accurately. Because speech is highly correlated with speech-related AUs, we propose an audio-to-AU module to predict speech-related AU information. We utilize pre-trained AU classifier to ensure that the generated images contain correct AU information. We verify the effectiveness of the proposed model on the GRID and TCD-TIMIT datasets. An ablation study is also conducted to verify the contribution of each component. The results of quantitative and qualitative experiments demonstrate that our method outperforms existing methods in terms of both image quality and lip-sync accuracy.
Talking Head Generation with Audio and Speech Related Facial Action Units
Oct 19, 2021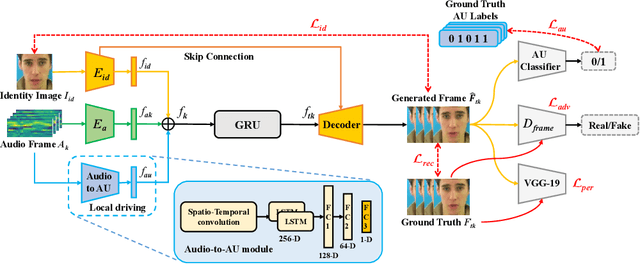
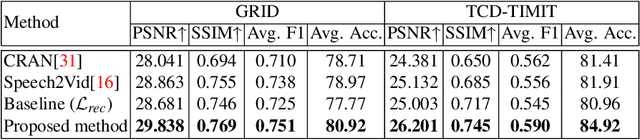


The task of talking head generation is to synthesize a lip synchronized talking head video by inputting an arbitrary face image and audio clips. Most existing methods ignore the local driving information of the mouth muscles. In this paper, we propose a novel recurrent generative network that uses both audio and speech-related facial action units (AUs) as the driving information. AU information related to the mouth can guide the movement of the mouth more accurately. Since speech is highly correlated with speech-related AUs, we propose an Audio-to-AU module in our system to predict the speech-related AU information from speech. In addition, we use AU classifier to ensure that the generated images contain correct AU information. Frame discriminator is also constructed for adversarial training to improve the realism of the generated face. We verify the effectiveness of our model on the GRID dataset and TCD-TIMIT dataset. We also conduct an ablation study to verify the contribution of each component in our model. Quantitative and qualitative experiments demonstrate that our method outperforms existing methods in both image quality and lip-sync accuracy.
Action Unit Detection with Joint Adaptive Attention and Graph Relation
Jul 09, 2021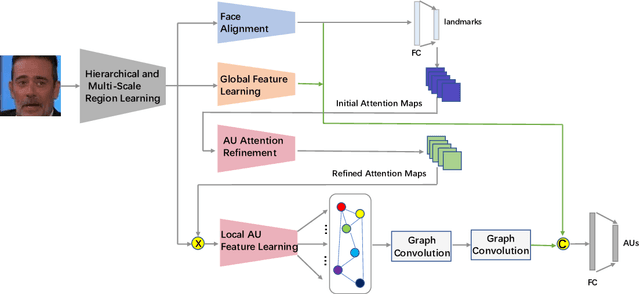
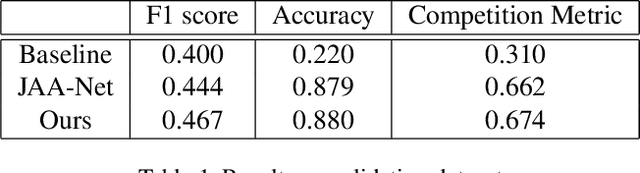
This paper describes an approach to the facial action unit (AU) detection. In this work, we present our submission to the Field Affective Behavior Analysis (ABAW) 2021 competition. The proposed method uses the pre-trained JAA model as the feature extractor, and extracts global features, face alignment features and AU local features on the basis of multi-scale features. We take the AU local features as the input of the graph convolution to further consider the correlation between AU, and finally use the fused features to classify AU. The detected accuracy was evaluated by 0.5*accuracy + 0.5*F1. Our model achieves 0.674 on the challenging Aff-Wild2 database.