 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Frequency Matters: Uncertainty Guided Image Compression with Wavelet Diffusion
Jul 17, 2024Diffusion probabilistic models have recently achieved remarkable success in generating high-quality images. However, balancing high perceptual quality and low distortion remains challenging in image compression applications. To address this issue, we propose an efficient Uncertainty-Guided image compression approach with wavelet Diffusion (UGDiff). Our approach focuses on high frequency compression via the wavelet transform, since high frequency components are crucial for reconstructing image details. We introduce a wavelet conditional diffusion model for high frequency prediction, followed by a residual codec that compresses and transmits prediction residuals to the decoder. This diffusion prediction-then-residual compression paradigm effectively addresses the low fidelity issue common in direct reconstructions by existing diffusion models. Considering the uncertainty from the random sampling of the diffusion model, we further design an uncertainty-weighted rate-distortion (R-D) loss tailored for residual compression, providing a more rational trade-off between rate and distortion. Comprehensive experiments on two benchmark datasets validate the effectiveness of UGDiff, surpassing state-of-the-art image compression methods in R-D performance, perceptual quality, subjective quality, and inference time. Our code is available at: https://github.com/hejiaxiang1/Wavelet-Diffusion/tree/main
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023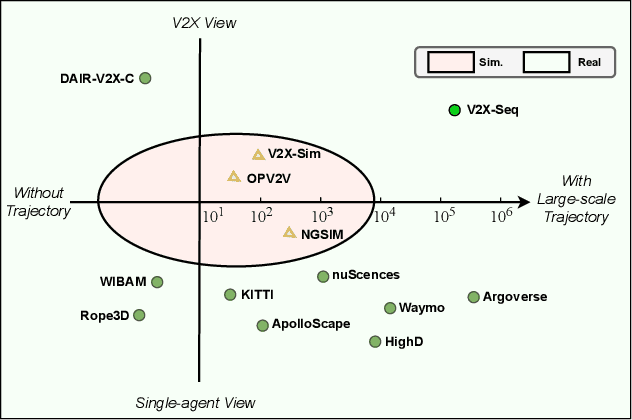
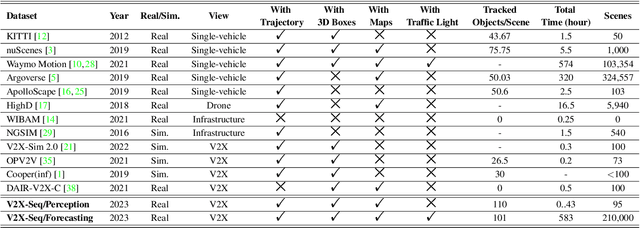
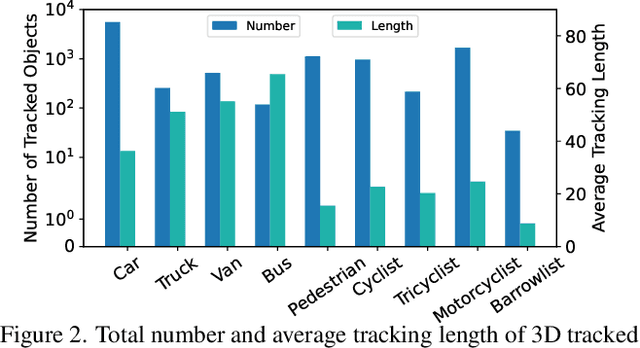
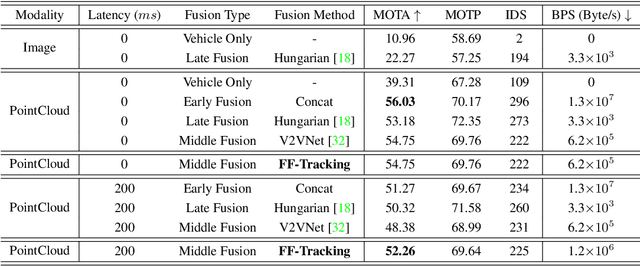
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
Self-supervised Facial Action Unit Detection with Region and Relation Learning
Mar 10, 2023



Facial action unit (AU) detection is a challenging task due to the scarcity of manual annotations. Recent works on AU detection with self-supervised learning have emerged to address this problem, aiming to learn meaningful AU representations from numerous unlabeled data. However, most existing AU detection works with self-supervised learning utilize global facial features only, while AU-related properties such as locality and relevance are not fully explored. In this paper, we propose a novel self-supervised framework for AU detection with the region and relation learning. In particular, AU related attention map is utilized to guide the model to focus more on AU-specific regions to enhance the integrity of AU local features. Meanwhile, an improved Optimal Transport (OT) algorithm is introduced to exploit the correlation characteristics among AUs. In addition, Swin Transformer is exploited to model the long-distance dependencies within each AU region during feature learning. The evaluation results on BP4D and DISFA demonstrate that our proposed method is comparable or even superior to the state-of-the-art self-supervised learning methods and supervised AU detection methods.
Action Unit Detection with Joint Adaptive Attention and Graph Relation
Jul 09, 2021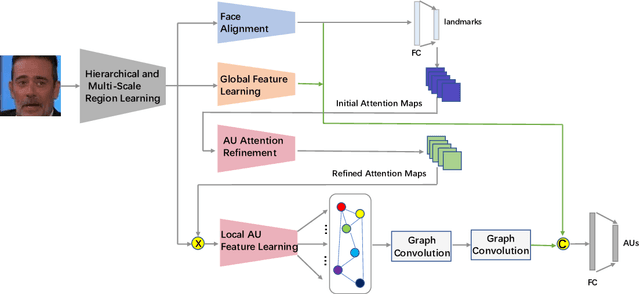
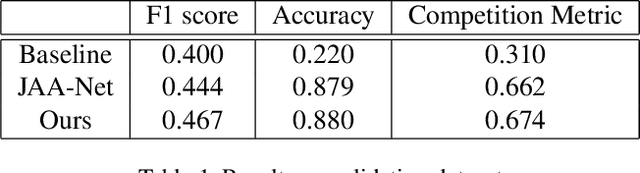
This paper describes an approach to the facial action unit (AU) detection. In this work, we present our submission to the Field Affective Behavior Analysis (ABAW) 2021 competition. The proposed method uses the pre-trained JAA model as the feature extractor, and extracts global features, face alignment features and AU local features on the basis of multi-scale features. We take the AU local features as the input of the graph convolution to further consider the correlation between AU, and finally use the fused features to classify AU. The detected accuracy was evaluated by 0.5*accuracy + 0.5*F1. Our model achieves 0.674 on the challenging Aff-Wild2 database.
A Systematic Collection of Medical Image Datasets for Deep Learning
Jun 24, 2021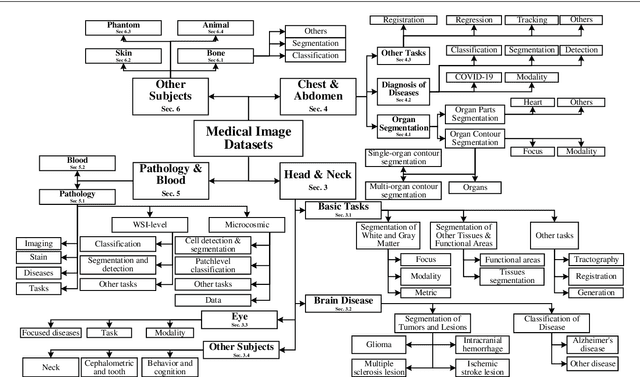
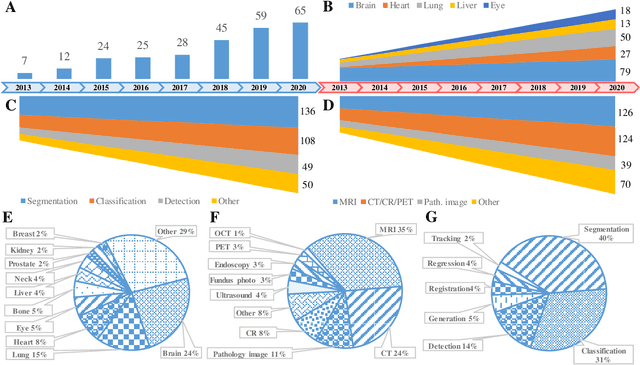
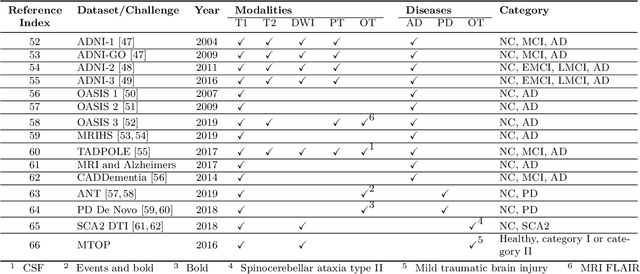
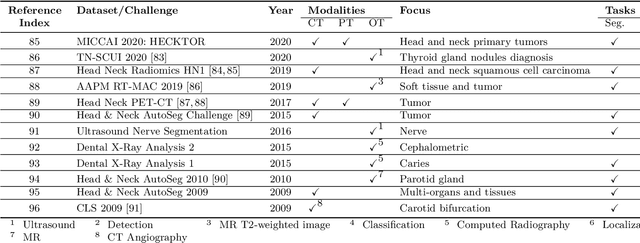
The astounding success made by artificial intelligence (AI) in healthcare and other fields proves that AI can achieve human-like performance. However, success always comes with challenges. Deep learning algorithms are data-dependent and require large datasets for training. The lack of data in the medical imaging field creates a bottleneck for the application of deep learning to medical image analysis. Medical image acquisition, annotation, and analysis are costly, and their usage is constrained by ethical restrictions. They also require many resources, such as human expertise and funding. That makes it difficult for non-medical researchers to have access to useful and large medical data. Thus, as comprehensive as possible, this paper provides a collection of medical image datasets with their associated challenges for deep learning research. We have collected information of around three hundred datasets and challenges mainly reported between 2013 and 2020 and categorized them into four categories: head & neck, chest & abdomen, pathology & blood, and ``others''. Our paper has three purposes: 1) to provide a most up to date and complete list that can be used as a universal reference to easily find the datasets for clinical image analysis, 2) to guide researchers on the methodology to test and evaluate their methods' performance and robustness on relevant datasets, 3) to provide a ``route'' to relevant algorithms for the relevant medical topics, and challenge leaderboards.