 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeletonContext: Skeleton-side Context Prompt Learning for Zero-Shot Skeleton-based Action Recognition
Mar 31, 2026Zero-shot skeleton-based action recognition aims to recognize unseen actions by transferring knowledge from seen categories through semantic descriptions. Most existing methods typically align skeleton features with textual embeddings within a shared latent space. However, the absence of contextual cues, such as objects involved in the action, introduces an inherent gap between skeleton and semantic representations, making it difficult to distinguish visually similar actions. To address this, we propose SkeletonContext, a prompt-based framework that enriches skeletal motion representations with language-driven contextual semantics. Specifically, we introduce a Cross-Modal Context Prompt Module, which leverages a pretrained language model to reconstruct masked contextual prompts under guidance derived from LLMs. This design effectively transfers linguistic context to the skeleton encoder for instance-level semantic grounding and improved cross-modal alignment. In addition, a Key-Part Decoupling Module is incorporated to decouple motion-relevant joint features, ensuring robust action understanding even in the absence of explicit object interactions. Extensive experiments on multiple benchmarks demonstrate that SkeletonContext achieves state-of-the-art performance under both conventional and generalized zero-shot settings, validating its effectiveness in reasoning about context and distinguishing fine-grained, visually similar actions.
FSD-CAP: Fractional Subgraph Diffusion with Class-Aware Propagation for Graph Feature Imputation
Jan 26, 2026Imputing missing node features in graphs is challenging, particularly under high missing rates. Existing methods based on latent representations or global diffusion often fail to produce reliable estimates, and may propagate errors across the graph. We propose FSD-CAP, a two-stage framework designed to improve imputation quality under extreme sparsity. In the first stage, a graph-distance-guided subgraph expansion localizes the diffusion process. A fractional diffusion operator adjusts propagation sharpness based on local structure. In the second stage, imputed features are refined using class-aware propagation, which incorporates pseudo-labels and neighborhood entropy to promote consistency. We evaluated FSD-CAP on multiple datasets. With $99.5\%$ of features missing across five benchmark datasets, FSD-CAP achieves average accuracies of $80.06\%$ (structural) and $81.01\%$ (uniform) in node classification, close to the $81.31\%$ achieved by a standard GCN with full features. For link prediction under the same setting, it reaches AUC scores of $91.65\%$ (structural) and $92.41\%$ (uniform), compared to $95.06\%$ for the fully observed case. Furthermore, FSD-CAP demonstrates superior performance on both large-scale and heterophily datasets when compared to other models.
Multi-Granularity Mutual Refinement Network for Zero-Shot Learning
Nov 11, 2025Zero-shot learning (ZSL) aims to recognize unseen classes with zero samples by transferring semantic knowledge from seen classes. Current approaches typically correlate global visual features with semantic information (i.e., attributes) or align local visual region features with corresponding attributes to enhance visual-semantic interactions. Although effective, these methods often overlook the intrinsic interactions between local region features, which can further improve the acquisition of transferable and explicit visual features. In this paper, we propose a network named Multi-Granularity Mutual Refinement Network (Mg-MRN), which refine discriminative and transferable visual features by learning decoupled multi-granularity features and cross-granularity feature interactions. Specifically, we design a multi-granularity feature extraction module to learn region-level discriminative features through decoupled region feature mining. Then, a cross-granularity feature fusion module strengthens the inherent interactions between region features of varying granularities. This module enhances the discriminability of representations at each granularity level by integrating region representations from adjacent hierarchies, further improving ZSL recognition performance. Extensive experiments on three popular ZSL benchmark datasets demonstrate the superiority and competitiveness of our proposed Mg-MRN method. Our code is available at https://github.com/NingWang2049/Mg-MRN.
DailyDVS-200: A Comprehensive Benchmark Dataset for Event-Based Action Recognition
Jul 06, 2024



Neuromorphic sensors, specifically event cameras, revolutionize visual data acquisition by capturing pixel intensity changes with exceptional dynamic range, minimal latency, and energy efficiency, setting them apart from conventional frame-based cameras. The distinctive capabilities of event cameras have ignited significant interest in the domain of event-based action recognition, recognizing their vast potential for advancement. However, the development in this field is currently slowed by the lack of comprehensive, large-scale datasets, which are critical for developing robust recognition frameworks. To bridge this gap, we introduces DailyDVS-200, a meticulously curated benchmark dataset tailored for the event-based action recognition community. DailyDVS-200 is extensive, covering 200 action categories across real-world scenarios, recorded by 47 participants, and comprises more than 22,000 event sequences. This dataset is designed to reflect a broad spectrum of action types, scene complexities, and data acquisition diversity. Each sequence in the dataset is annotated with 14 attributes, ensuring a detailed characterization of the recorded actions. Moreover, DailyDVS-200 is structured to facilitate a wide range of research paths, offering a solid foundation for both validating existing approaches and inspiring novel methodologies. By setting a new benchmark in the field, we challenge the current limitations of neuromorphic data processing and invite a surge of new approaches in event-based action recognition techniques, which paves the way for future explorations in neuromorphic computing and beyond. The dataset and source code are available at https://github.com/QiWang233/DailyDVS-200.
Language Model Guided Interpretable Video Action Reasoning
Apr 02, 2024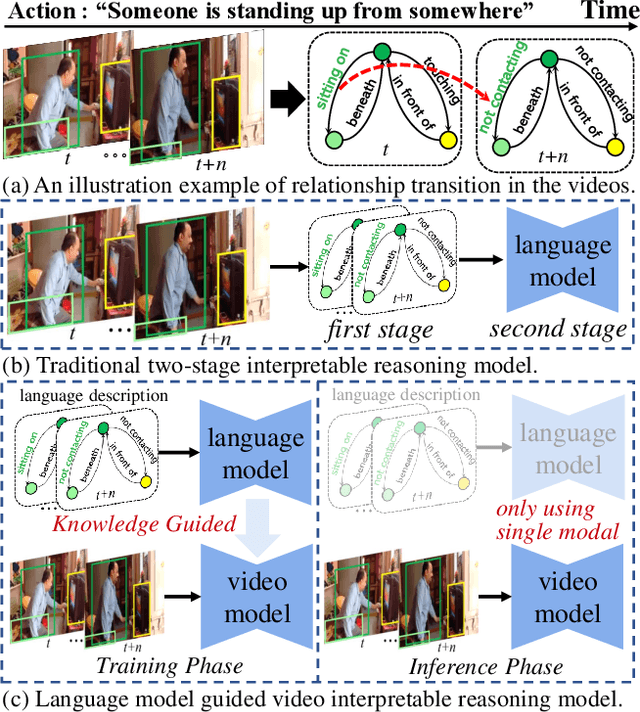
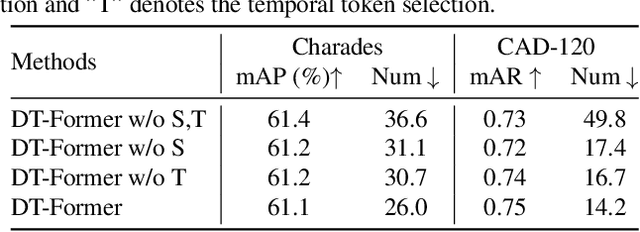
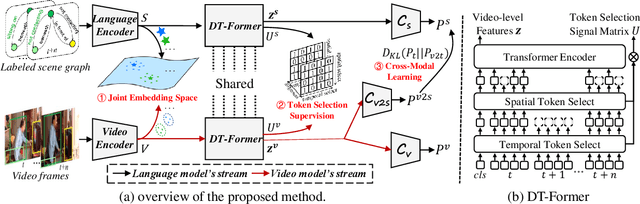
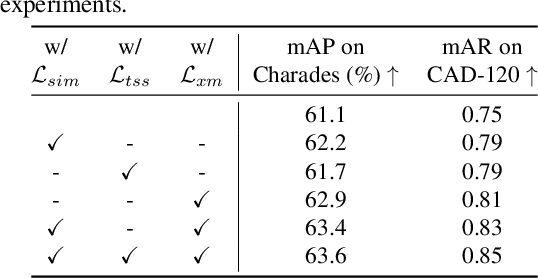
While neural networks have excelled in video action recognition tasks, their black-box nature often obscures the understanding of their decision-making processes. Recent approaches used inherently interpretable models to analyze video actions in a manner akin to human reasoning. These models, however, usually fall short in performance compared to their black-box counterparts. In this work, we present a new framework named Language-guided Interpretable Action Recognition framework (LaIAR). LaIAR leverages knowledge from language models to enhance both the recognition capabilities and the interpretability of video models. In essence, we redefine the problem of understanding video model decisions as a task of aligning video and language models. Using the logical reasoning captured by the language model, we steer the training of the video model. This integrated approach not only improves the video model's adaptability to different domains but also boosts its overall performance. Extensive experiments on two complex video action datasets, Charades & CAD-120, validates the improved performance and interpretability of our LaIAR framework. The code of LaIAR is available at https://github.com/NingWang2049/LaIAR.
The two-way knowledge interaction interface between humans and neural networks
Jan 10, 2024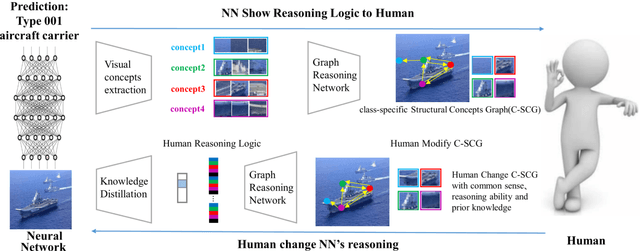
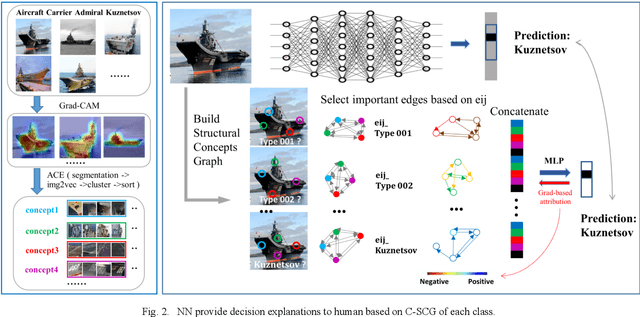
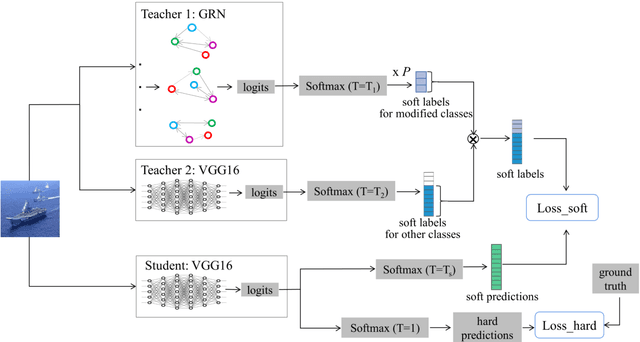
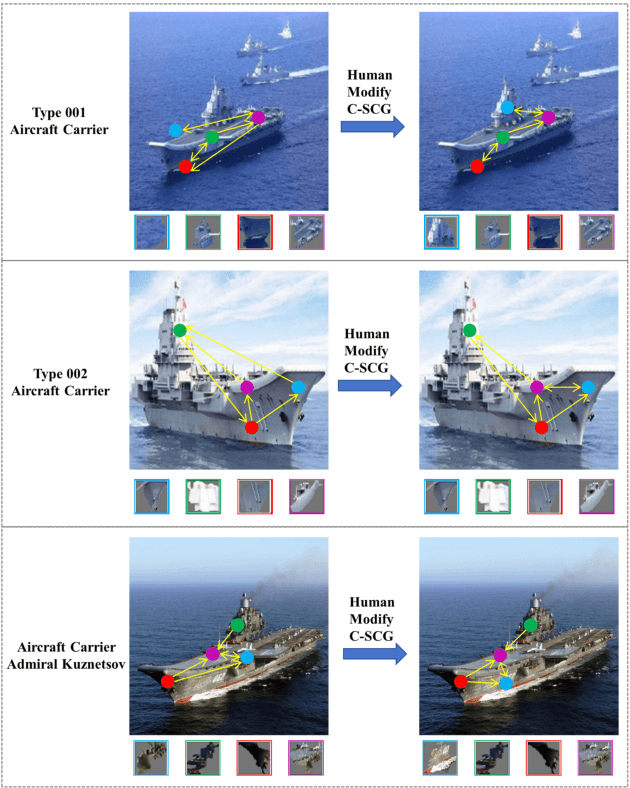
Despite neural networks (NN) have been widely applied in various fields and generally outperforms humans, they still lack interpretability to a certain extent, and humans are unable to intuitively understand the decision logic of NN. This also hinders the knowledge interaction between humans and NN, preventing humans from getting involved to give direct guidance when NN's decisions go wrong. While recent research in explainable AI has achieved interpretability of NN from various perspectives, it has not yet provided effective methods for knowledge exchange between humans and NN. To address this problem, we constructed a two-way interaction interface that uses structured representations of visual concepts and their relationships as the "language" for knowledge exchange between humans and NN. Specifically, NN provide intuitive reasoning explanations to humans based on the class-specific structural concepts graph (C-SCG). On the other hand, humans can modify the biases present in the C-SCG through their prior knowledge and reasoning ability, and thus provide direct knowledge guidance to NN through this interface. Through experimental validation, based on this interaction interface, NN can provide humans with easily understandable explanations of the reasoning process. Furthermore, human involvement and prior knowledge can directly and effectively contribute to enhancing the performance of NN.
Content-Conditioned Generation of Stylized Free hand Sketches
Jan 09, 2024



In recent years, the recognition of free-hand sketches has remained a popular task. However, in some special fields such as the military field, free-hand sketches are difficult to sample on a large scale. Common data augmentation and image generation techniques are difficult to produce images with various free-hand sketching styles. Therefore, the recognition and segmentation tasks in related fields are limited. In this paper, we propose a novel adversarial generative network that can accurately generate realistic free-hand sketches with various styles. We explore the performance of the model, including using styles randomly sampled from a prior normal distribution to generate images with various free-hand sketching styles, disentangling the painters' styles from known free-hand sketches to generate images with specific styles, and generating images of unknown classes that are not in the training set. We further demonstrate with qualitative and quantitative evaluations our advantages in visual quality, content accuracy, and style imitation on SketchIME.
Flowmind2Digital: The First Comprehensive Flowmind Recognition and Conversion Approach
Jan 08, 2024Flowcharts and mind maps, collectively known as flowmind, are vital in daily activities, with hand-drawn versions facilitating real-time collaboration. However, there's a growing need to digitize them for efficient processing. Automated conversion methods are essential to overcome manual conversion challenges. Existing sketch recognition methods face limitations in practical situations, being field-specific and lacking digital conversion steps. Our paper introduces the Flowmind2digital method and hdFlowmind dataset to address these challenges. Flowmind2digital, utilizing neural networks and keypoint detection, achieves a record 87.3% accuracy on our dataset, surpassing previous methods by 11.9%. The hdFlowmind dataset, comprising 1,776 annotated flowminds across 22 scenarios, outperforms existing datasets. Additionally, our experiments emphasize the importance of simple graphics, enhancing accuracy by 9.3%.
A multimodal gesture recognition dataset for desktop human-computer interaction
Jan 08, 2024



Gesture recognition is an indispensable component of natural and efficient human-computer interaction technology, particularly in desktop-level applications, where it can significantly enhance people's productivity. However, the current gesture recognition community lacks a suitable desktop-level (top-view perspective) dataset for lightweight gesture capture devices. In this study, we have established a dataset named GR4DHCI. What distinguishes this dataset is its inherent naturalness, intuitive characteristics, and diversity. Its primary purpose is to serve as a valuable resource for the development of desktop-level portable applications. GR4DHCI comprises over 7,000 gesture samples and a total of 382,447 frames for both Stereo IR and skeletal modalities. We also address the variances in hand positioning during desktop interactions by incorporating 27 different hand positions into the dataset. Building upon the GR4DHCI dataset, we conducted a series of experimental studies, the results of which demonstrate that the fine-grained classification blocks proposed in this paper can enhance the model's recognition accuracy. Our dataset and experimental findings presented in this paper are anticipated to propel advancements in desktop-level gesture recognition research.
Enhance Sketch Recognition's Explainability via Semantic Component-Level Parsing
Dec 13, 2023



Free-hand sketches are appealing for humans as a universal tool to depict the visual world. Humans can recognize varied sketches of a category easily by identifying the concurrence and layout of the intrinsic semantic components of the category, since humans draw free-hand sketches based a common consensus that which types of semantic components constitute each sketch category. For example, an airplane should at least have a fuselage and wings. Based on this analysis, a semantic component-level memory module is constructed and embedded in the proposed structured sketch recognition network in this paper. The memory keys representing semantic components of each sketch category can be self-learned and enhance the recognition network's explainability. Our proposed networks can deal with different situations of sketch recognition, i.e., with or without semantic components labels of strokes. Experiments on the SPG and SketchIME datasets demonstrate the memory module's flexibility and the recognition network's explainability. The code and data are available at https://github.com/GuangmingZhu/SketchESC.