 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSceneGraph: Geometric Scene Graph Diffusion Model for Text-guided 3D Indoor Scene Synthesis
Nov 18, 2025Methods that synthesize indoor 3D scenes from text prompts have wide-ranging applications in film production, interior design, video games, virtual reality, and synthetic data generation for training embodied agents. Existing approaches typically either train generative models from scratch or leverage vision-language models (VLMs). While VLMs achieve strong performance, particularly for complex or open-ended prompts, smaller task-specific models remain necessary for deployment on resource-constrained devices such as extended reality (XR) glasses or mobile phones. However, many generative approaches that train from scratch overlook the inherent graph structure of indoor scenes, which can limit scene coherence and realism. Conversely, methods that incorporate scene graphs either demand a user-provided semantic graph, which is generally inconvenient and restrictive, or rely on ground-truth relationship annotations, limiting their capacity to capture more varied object interactions. To address these challenges, we introduce GeoSceneGraph, a method that synthesizes 3D scenes from text prompts by leveraging the graph structure and geometric symmetries of 3D scenes, without relying on predefined relationship classes. Despite not using ground-truth relationships, GeoSceneGraph achieves performance comparable to methods that do. Our model is built on equivariant graph neural networks (EGNNs), but existing EGNN approaches are typically limited to low-dimensional conditioning and are not designed to handle complex modalities such as text. We propose a simple and effective strategy for conditioning EGNNs on text features, and we validate our design through ablation studies.
T3DM: Test-Time Training-Guided Distribution Shift Modelling for Temporal Knowledge Graph Reasoning
Jul 02, 2025Temporal Knowledge Graph (TKG) is an efficient method for describing the dynamic development of facts along a timeline. Most research on TKG reasoning (TKGR) focuses on modelling the repetition of global facts and designing patterns of local historical facts. However, they face two significant challenges: inadequate modeling of the event distribution shift between training and test samples, and reliance on random entity substitution for generating negative samples, which often results in low-quality sampling. To this end, we propose a novel distributional feature modeling approach for training TKGR models, Test-Time Training-guided Distribution shift Modelling (T3DM), to adjust the model based on distribution shift and ensure the global consistency of model reasoning. In addition, we design a negative-sampling strategy to generate higher-quality negative quadruples based on adversarial training. Extensive experiments show that T3DM provides better and more robust results than the state-of-the-art baselines in most cases.
Zero-Shot Event Causality Identification via Multi-source Evidence Fuzzy Aggregation with Large Language Models
Jun 06, 2025



Event Causality Identification (ECI) aims to detect causal relationships between events in textual contexts. Existing ECI models predominantly rely on supervised methodologies, suffering from dependence on large-scale annotated data. Although Large Language Models (LLMs) enable zero-shot ECI, they are prone to causal hallucination-erroneously establishing spurious causal links. To address these challenges, we propose MEFA, a novel zero-shot framework based on Multi-source Evidence Fuzzy Aggregation. First, we decompose causality reasoning into three main tasks (temporality determination, necessity analysis, and sufficiency verification) complemented by three auxiliary tasks. Second, leveraging meticulously designed prompts, we guide LLMs to generate uncertain responses and deterministic outputs. Finally, we quantify LLM's responses of sub-tasks and employ fuzzy aggregation to integrate these evidence for causality scoring and causality determination. Extensive experiments on three benchmarks demonstrate that MEFA outperforms second-best unsupervised baselines by 6.2% in F1-score and 9.3% in precision, while significantly reducing hallucination-induced errors. In-depth analysis verify the effectiveness of task decomposition and the superiority of fuzzy aggregation.
PRISM: Probabilistic Representation for Integrated Shape Modeling and Generation
Apr 06, 2025Despite the advancements in 3D full-shape generation, accurately modeling complex geometries and semantics of shape parts remains a significant challenge, particularly for shapes with varying numbers of parts. Current methods struggle to effectively integrate the contextual and structural information of 3D shapes into their generative processes. We address these limitations with PRISM, a novel compositional approach for 3D shape generation that integrates categorical diffusion models with Statistical Shape Models (SSM) and Gaussian Mixture Models (GMM). Our method employs compositional SSMs to capture part-level geometric variations and uses GMM to represent part semantics in a continuous space. This integration enables both high fidelity and diversity in generated shapes while preserving structural coherence. Through extensive experiments on shape generation and manipulation tasks, we demonstrate that our approach significantly outperforms previous methods in both quality and controllability of part-level operations. Our code will be made publicly available.
HI-SLAM2: Geometry-Aware Gaussian SLAM for Fast Monocular Scene Reconstruction
Nov 27, 2024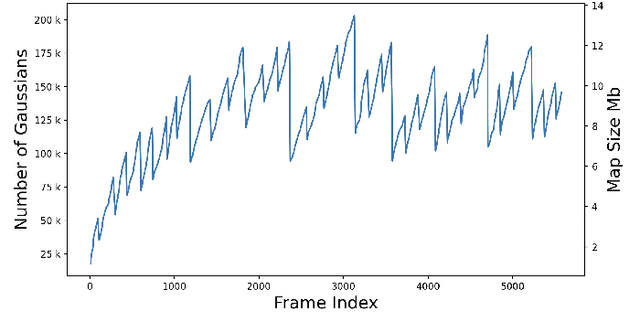
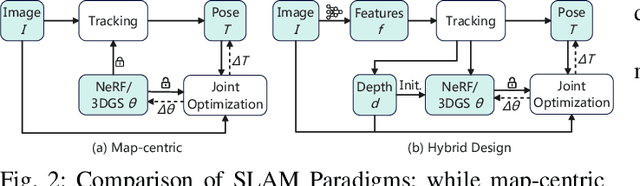
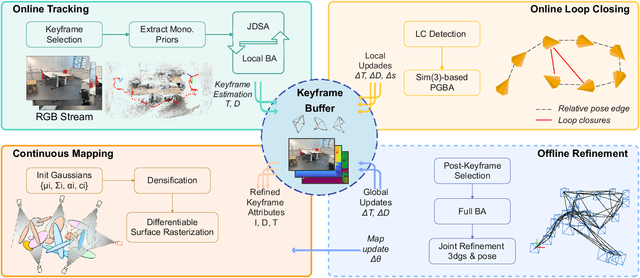
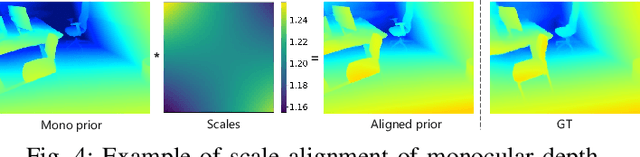
We present HI-SLAM2, a geometry-aware Gaussian SLAM system that achieves fast and accurate monocular scene reconstruction using only RGB input. Existing Neural SLAM or 3DGS-based SLAM methods often trade off between rendering quality and geometry accuracy, our research demonstrates that both can be achieved simultaneously with RGB input alone. The key idea of our approach is to enhance the ability for geometry estimation by combining easy-to-obtain monocular priors with learning-based dense SLAM, and then using 3D Gaussian splatting as our core map representation to efficiently model the scene. Upon loop closure, our method ensures on-the-fly global consistency through efficient pose graph bundle adjustment and instant map updates by explicitly deforming the 3D Gaussian units based on anchored keyframe updates. Furthermore, we introduce a grid-based scale alignment strategy to maintain improved scale consistency in prior depths for finer depth details. Through extensive experiments on Replica, ScanNet, and ScanNet++, we demonstrate significant improvements over existing Neural SLAM methods and even surpass RGB-D-based methods in both reconstruction and rendering quality. The project page and source code will be made available at https://hi-slam2.github.io/.
A Survey of Event Causality Identification: Principles, Taxonomy, Challenges, and Assessment
Nov 15, 2024
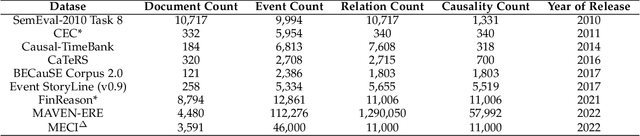
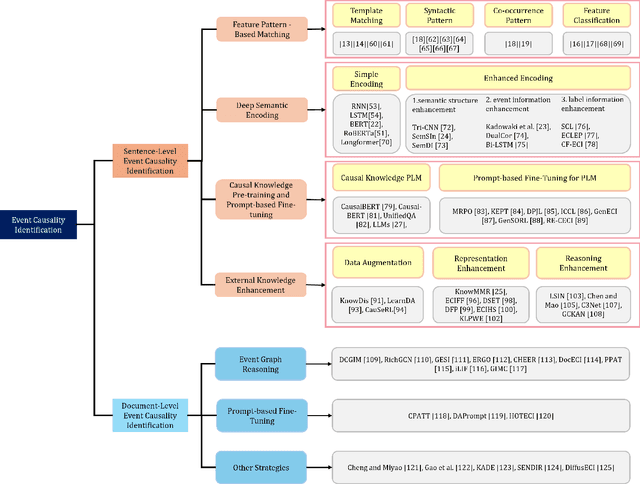

Event Causality Identification (ECI) has become a crucial task in Natural Language Processing (NLP), aimed at automatically extracting causalities from textual data. In this survey, we systematically address the foundational principles, technical frameworks, and challenges of ECI, offering a comprehensive taxonomy to categorize and clarify current research methodologies, as well as a quantitative assessment of existing models. We first establish a conceptual framework for ECI, outlining key definitions, problem formulations, and evaluation standards. Our taxonomy classifies ECI methods according to the two primary tasks of sentence-level (SECI) and document-level (DECI) event causality identification. For SECI, we examine feature pattern-based matching, deep semantic encoding, causal knowledge pre-training and prompt-based fine-tuning, and external knowledge enhancement methods. For DECI, we highlight approaches focused on event graph reasoning and prompt-based techniques to address the complexity of cross-sentence causal inference. Additionally, we analyze the strengths, limitations, and open challenges of each approach. We further conduct an extensive quantitative evaluation of various ECI methods on two benchmark datasets. Finally, we explore future research directions, highlighting promising pathways to overcome current limitations and broaden ECI applications.
Reconstructing MODIS Normalized Difference Snow Index Product on Greenland Ice Sheet Using Spatiotemporal Extreme Gradient Boosting Model
Nov 03, 2024



The spatiotemporally continuous data of normalized difference snow index (NDSI) are key to understanding the mechanisms of snow occurrence and development as well as the patterns of snow distribution changes. However, the presence of clouds, particularly prevalent in polar regions such as the Greenland Ice Sheet (GrIS), introduces a significant number of missing pixels in the MODIS NDSI daily data. To address this issue, this study proposes the utilization of a spatiotemporal extreme gradient boosting (STXGBoost) model generate a comprehensive NDSI dataset. In the proposed model, various input variables are carefully selected, encompassing terrain features, geometry-related parameters, and surface property variables. Moreover, the model incorporates spatiotemporal variation information, enhancing its capacity for reconstructing the NDSI dataset. Verification results demonstrate the efficacy of the STXGBoost model, with a coefficient of determination of 0.962, root mean square error of 0.030, mean absolute error of 0.011, and negligible bias (0.0001). Furthermore, simulation comparisons involving missing data and cross-validation with Landsat NDSI data illustrate the model's capability to accurately reconstruct the spatial distribution of NDSI data. Notably, the proposed model surpasses the performance of traditional machine learning models, showcasing superior NDSI predictive capabilities. This study highlights the potential of leveraging auxiliary data to reconstruct NDSI in GrIS, with implications for broader applications in other regions. The findings offer valuable insights for the reconstruction of NDSI remote sensing data, contributing to the further understanding of spatiotemporal dynamics in snow-covered regions.
Sketch Input Method Editor: A Comprehensive Dataset and Methodology for Systematic Input Recognition
Nov 30, 2023



With the recent surge in the use of touchscreen devices, free-hand sketching has emerged as a promising modality for human-computer interaction. While previous research has focused on tasks such as recognition, retrieval, and generation of familiar everyday objects, this study aims to create a Sketch Input Method Editor (SketchIME) specifically designed for a professional C4I system. Within this system, sketches are utilized as low-fidelity prototypes for recommending standardized symbols in the creation of comprehensive situation maps. This paper also presents a systematic dataset comprising 374 specialized sketch types, and proposes a simultaneous recognition and segmentation architecture with multilevel supervision between recognition and segmentation to improve performance and enhance interpretability. By incorporating few-shot domain adaptation and class-incremental learning, the network's ability to adapt to new users and extend to new task-specific classes is significantly enhanced. Results from experiments conducted on both the proposed dataset and the SPG dataset illustrate the superior performance of the proposed architecture. Our dataset and code are publicly available at https://github.com/Anony517/SketchIME.
HI-SLAM: Monocular Real-time Dense Mapping with Hybrid Implicit Fields
Oct 07, 2023



In this letter, we present a neural field-based real-time monocular mapping framework for accurate and dense Simultaneous Localization and Mapping (SLAM). Recent neural mapping frameworks show promising results, but rely on RGB-D or pose inputs, or cannot run in real-time. To address these limitations, our approach integrates dense-SLAM with neural implicit fields. Specifically, our dense SLAM approach runs parallel tracking and global optimization, while a neural field-based map is constructed incrementally based on the latest SLAM estimates. For the efficient construction of neural fields, we employ multi-resolution grid encoding and signed distance function (SDF) representation. This allows us to keep the map always up-to-date and adapt instantly to global updates via loop closing. For global consistency, we propose an efficient Sim(3)-based pose graph bundle adjustment (PGBA) approach to run online loop closing and mitigate the pose and scale drift. To enhance depth accuracy further, we incorporate learned monocular depth priors. We propose a novel joint depth and scale adjustment (JDSA) module to solve the scale ambiguity inherent in depth priors. Extensive evaluations across synthetic and real-world datasets validate that our approach outperforms existing methods in accuracy and map completeness while preserving real-time performance.
Vision-based Large-scale 3D Semantic Mapping for Autonomous Driving Applications
Mar 02, 2022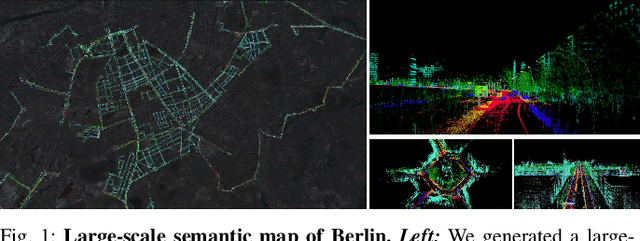
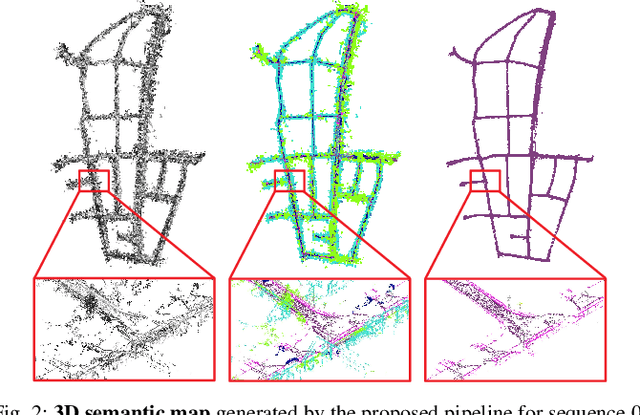
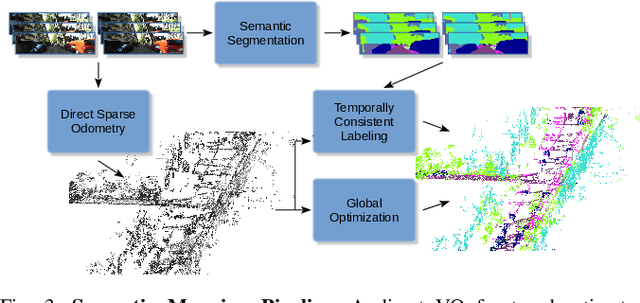
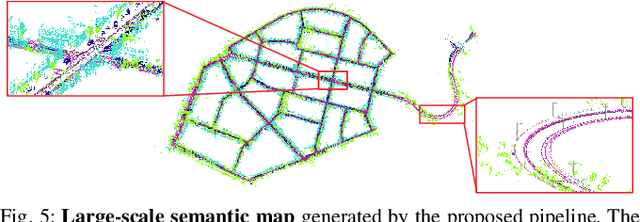
In this paper, we present a complete pipeline for 3D semantic mapping solely based on a stereo camera system. The pipeline comprises a direct sparse visual odometry front-end as well as a back-end for global optimization including GNSS integration, and semantic 3D point cloud labeling. We propose a simple but effective temporal voting scheme which improves the quality and consistency of the 3D point labels. Qualitative and quantitative evaluations of our pipeline are performed on the KITTI-360 dataset. The results show the effectiveness of our proposed voting scheme and the capability of our pipeline for efficient large-scale 3D semantic mapping. The large-scale mapping capabilities of our pipeline is furthermore demonstrated by presenting a very large-scale semantic map covering 8000 km of roads generated from data collected by a fleet of vehicles.