 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn RTK-SLAM Dataset for Absolute Accuracy Evaluation in GNSS-Degraded Environments
Apr 08, 2026RTK-SLAM systems integrate simultaneous localization and mapping (SLAM) with real-time kinematic (RTK) GNSS positioning, promising both relative consistency and globally referenced coordinates for efficient georeferenced surveying. A critical and underappreciated issue is that the standard evaluation metric, Absolute Trajectory Error (ATE), first fits an optimal rigid-body transformation between the estimated trajectory and reference before computing errors. This so-called SE(3) alignment absorbs global drift and systematic errors, making trajectories appear more accurate than they are in practice, and is unsuitable for evaluating the global accuracy of RTK-SLAM. We present a geodetically referenced dataset and evaluation methodology that expose this gap. A key design principle is that the RTK receiver is used solely as a system input, while ground truth is established independently via a geodetic total station. This separation is absent from all existing datasets, where GNSS typically serves as (part of) the ground truth. The dataset is collected with a handheld RTK-SLAM device, comprising two scenes. We evaluate LiDAR-inertial, visual-inertial, and LiDAR-visual-inertial RTK-SLAM systems alongside standalone RTK, reporting direct global accuracy and SE(3)-aligned relative accuracy to make the gap explicit. Results show that SE(3) alignment can underestimate absolute positioning error by up to 76\%. RTK-SLAM achieves centimeter-level absolute accuracy in open-sky conditions and maintains decimeter-level global accuracy indoors, where standalone RTK degrades to tens of meters. The dataset, calibration files, and evaluation scripts are publicly available at https://rtk-slam-dataset.github.io/.
BEV-SLD: Self-Supervised Scene Landmark Detection for Global Localization with LiDAR Bird's-Eye View Images
Mar 17, 2026We present BEV-SLD, a LiDAR global localization method building on the Scene Landmark Detection (SLD) concept. Unlike scene-agnostic pipelines, our self-supervised approach leverages bird's-eye-view (BEV) images to discover scene-specific patterns at a prescribed spatial density and treat them as landmarks. A consistency loss aligns learnable global landmark coordinates with per-frame heatmaps, yielding consistent landmark detections across the scene. Across campus, industrial, and forest environments, BEV-SLD delivers robust localization and achieves strong performance compared to state-of-the-art methods.
3D Gaussian Splatting aided Localization for Large and Complex Indoor-Environments
Feb 19, 2025The field of visual localization has been researched for several decades and has meanwhile found many practical applications. Despite the strong progress in this field, there are still challenging situations in which established methods fail. We present an approach to significantly improve the accuracy and reliability of established visual localization methods by adding rendered images. In detail, we first use a modern visual SLAM approach that provides a 3D Gaussian Splatting (3DGS) based map to create reference data. We demonstrate that enriching reference data with images rendered from 3DGS at randomly sampled poses significantly improves the performance of both geometry-based visual localization and Scene Coordinate Regression (SCR) methods. Through comprehensive evaluation in a large industrial environment, we analyze the performance impact of incorporating these additional rendered views.
HI-SLAM2: Geometry-Aware Gaussian SLAM for Fast Monocular Scene Reconstruction
Nov 27, 2024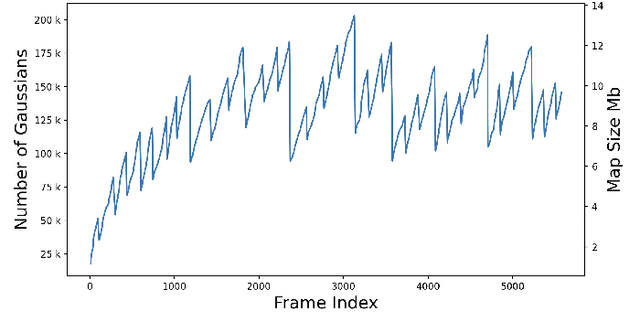
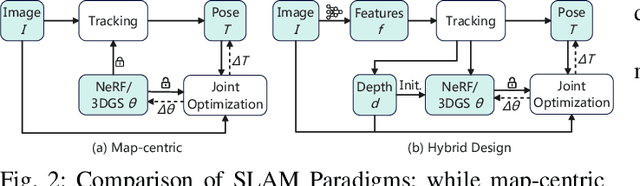
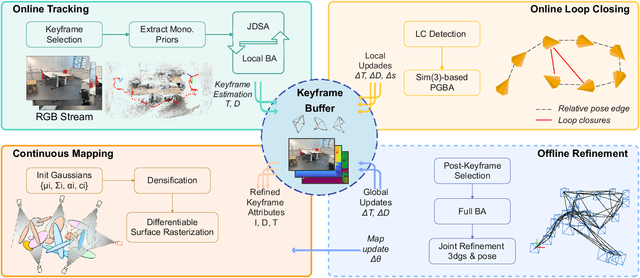
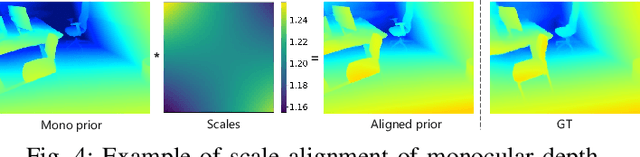
We present HI-SLAM2, a geometry-aware Gaussian SLAM system that achieves fast and accurate monocular scene reconstruction using only RGB input. Existing Neural SLAM or 3DGS-based SLAM methods often trade off between rendering quality and geometry accuracy, our research demonstrates that both can be achieved simultaneously with RGB input alone. The key idea of our approach is to enhance the ability for geometry estimation by combining easy-to-obtain monocular priors with learning-based dense SLAM, and then using 3D Gaussian splatting as our core map representation to efficiently model the scene. Upon loop closure, our method ensures on-the-fly global consistency through efficient pose graph bundle adjustment and instant map updates by explicitly deforming the 3D Gaussian units based on anchored keyframe updates. Furthermore, we introduce a grid-based scale alignment strategy to maintain improved scale consistency in prior depths for finer depth details. Through extensive experiments on Replica, ScanNet, and ScanNet++, we demonstrate significant improvements over existing Neural SLAM methods and even surpass RGB-D-based methods in both reconstruction and rendering quality. The project page and source code will be made available at https://hi-slam2.github.io/.
SLAM for Indoor Mapping of Wide Area Construction Environments
Apr 26, 2024



Simultaneous localization and mapping (SLAM), i.e., the reconstruction of the environment represented by a (3D) map and the concurrent pose estimation, has made astonishing progress. Meanwhile, large scale applications aiming at the data collection in complex environments like factory halls or construction sites are becoming feasible. However, in contrast to small scale scenarios with building interiors separated to single rooms, shop floors or construction areas require measures at larger distances in potentially texture less areas under difficult illumination. Pose estimation is further aggravated since no GNSS measures are available as it is usual for such indoor applications. In our work, we realize data collection in a large factory hall by a robot system equipped with four stereo cameras as well as a 3D laser scanner. We apply our state-of-the-art LiDAR and visual SLAM approaches and discuss the respective pros and cons of the different sensor types for trajectory estimation and dense map generation in such an environment. Additionally, dense and accurate depth maps are generated by 3D Gaussian splatting, which we plan to use in the context of our project aiming on the automatic construction and site monitoring.
Depth Supervised Neural Surface Reconstruction from Airborne Imagery
Apr 25, 2024While originally developed for novel view synthesis, Neural Radiance Fields (NeRFs) have recently emerged as an alternative to multi-view stereo (MVS). Triggered by a manifold of research activities, promising results have been gained especially for texture-less, transparent, and reflecting surfaces, while such scenarios remain challenging for traditional MVS-based approaches. However, most of these investigations focus on close-range scenarios, with studies for airborne scenarios still missing. For this task, NeRFs face potential difficulties at areas of low image redundancy and weak data evidence, as often found in street canyons, facades or building shadows. Furthermore, training such networks is computationally expensive. Thus, the aim of our work is twofold: First, we investigate the applicability of NeRFs for aerial image blocks representing different characteristics like nadir-only, oblique and high-resolution imagery. Second, during these investigations we demonstrate the benefit of integrating depth priors from tie-point measures, which are provided during presupposed Bundle Block Adjustment. Our work is based on the state-of-the-art framework VolSDF, which models 3D scenes by signed distance functions (SDFs), since this is more applicable for surface reconstruction compared to the standard volumetric representation in vanilla NeRFs. For evaluation, the NeRF-based reconstructions are compared to results of a publicly available benchmark dataset for airborne images.
DMSA -- Dense Multi Scan Adjustment for LiDAR Inertial Odometry and Global Optimization
Feb 29, 2024We propose a new method for fine registering multiple point clouds simultaneously. The approach is characterized by being dense, therefore point clouds are not reduced to pre-selected features in advance. Furthermore, the approach is robust against small overlaps and dynamic objects, since no direct correspondences are assumed between point clouds. Instead, all points are merged into a global point cloud, whose scattering is then iteratively reduced. This is achieved by dividing the global point cloud into uniform grid cells whose contents are subsequently modeled by normal distributions. We show that the proposed approach can be used in a sliding window continuous trajectory optimization combined with IMU measurements to obtain a highly accurate and robust LiDAR inertial odometry estimation. Furthermore, we show that the proposed approach is also suitable for large scale keyframe optimization to increase accuracy. We provide the source code and some experimental data on https://github.com/davidskdds/DMSA_LiDAR_SLAM.git.
HI-SLAM: Monocular Real-time Dense Mapping with Hybrid Implicit Fields
Oct 07, 2023



In this letter, we present a neural field-based real-time monocular mapping framework for accurate and dense Simultaneous Localization and Mapping (SLAM). Recent neural mapping frameworks show promising results, but rely on RGB-D or pose inputs, or cannot run in real-time. To address these limitations, our approach integrates dense-SLAM with neural implicit fields. Specifically, our dense SLAM approach runs parallel tracking and global optimization, while a neural field-based map is constructed incrementally based on the latest SLAM estimates. For the efficient construction of neural fields, we employ multi-resolution grid encoding and signed distance function (SDF) representation. This allows us to keep the map always up-to-date and adapt instantly to global updates via loop closing. For global consistency, we propose an efficient Sim(3)-based pose graph bundle adjustment (PGBA) approach to run online loop closing and mitigate the pose and scale drift. To enhance depth accuracy further, we incorporate learned monocular depth priors. We propose a novel joint depth and scale adjustment (JDSA) module to solve the scale ambiguity inherent in depth priors. Extensive evaluations across synthetic and real-world datasets validate that our approach outperforms existing methods in accuracy and map completeness while preserving real-time performance.
BAMF-SLAM: Bundle Adjusted Multi-Fisheye Visual-Inertial SLAM Using Recurrent Field Transforms
Jun 14, 2023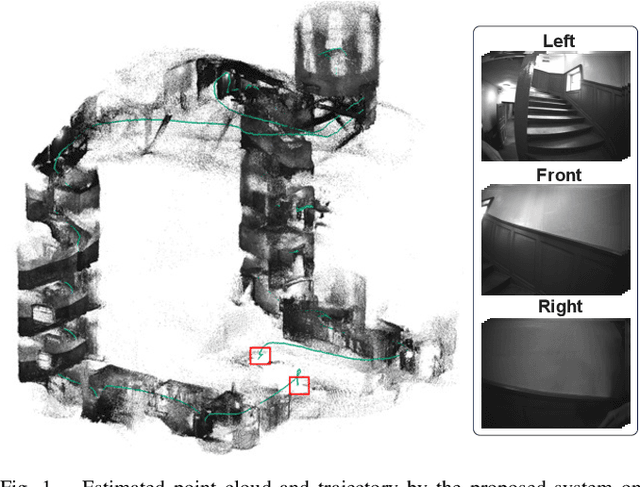
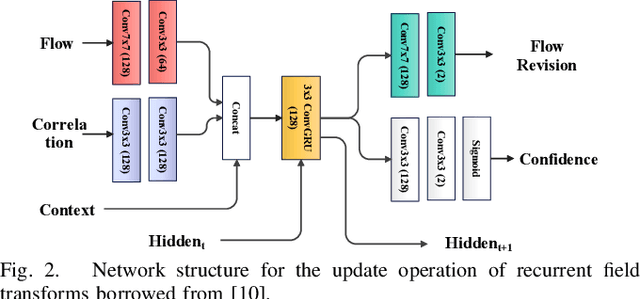
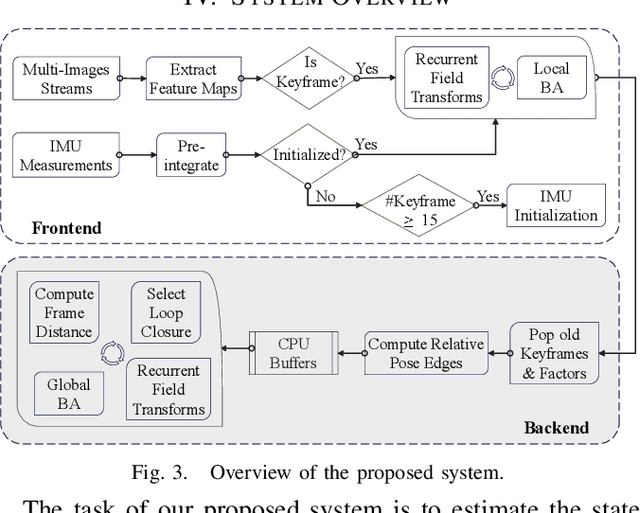

In this paper, we present BAMF-SLAM, a novel multi-fisheye visual-inertial SLAM system that utilizes Bundle Adjustment (BA) and recurrent field transforms (RFT) to achieve accurate and robust state estimation in challenging scenarios. First, our system directly operates on raw fisheye images, enabling us to fully exploit the wide Field-of-View (FoV) of fisheye cameras. Second, to overcome the low-texture challenge, we explore the tightly-coupled integration of multi-camera inputs and complementary inertial measurements via a unified factor graph and jointly optimize the poses and dense depth maps. Third, for global consistency, the wide FoV of the fisheye camera allows the system to find more potential loop closures, and powered by the broad convergence basin of RFT, our system can perform very wide baseline loop closing with little overlap. Furthermore, we introduce a semi-pose-graph BA method to avoid the expensive full global BA. By combining relative pose factors with loop closure factors, the global states can be adjusted efficiently with modest memory footprint while maintaining high accuracy. Evaluations on TUM-VI, Hilti-Oxford and Newer College datasets show the superior performance of the proposed system over prior works. In the Hilti SLAM Challenge 2022, our VIO version achieves second place. In a subsequent submission, our complete system, including the global BA backend, outperforms the winning approach.
Juggling With Representations: On the Information Transfer Between Imagery, Point Clouds, and Meshes for Multi-Modal Semantics
Mar 12, 2021

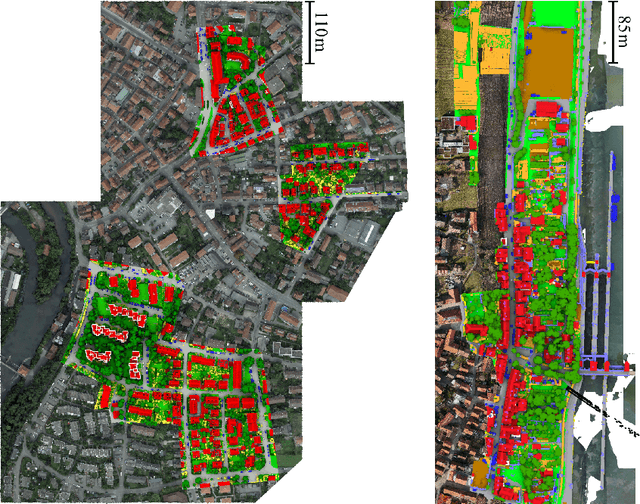
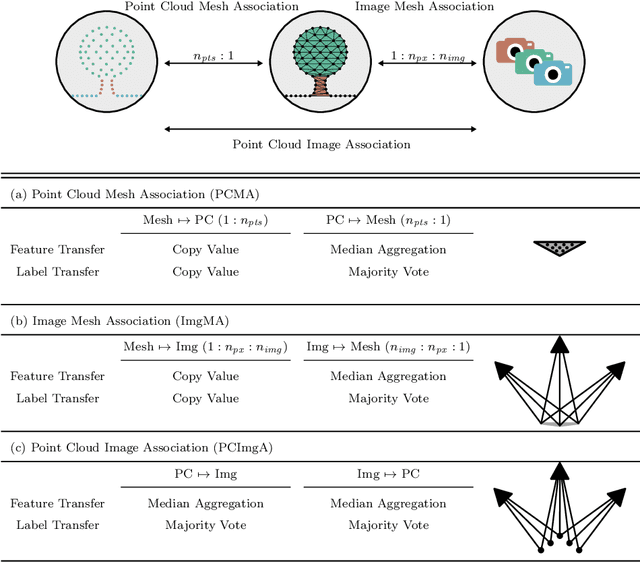
The automatic semantic segmentation of the huge amount of acquired remote sensing data has become an important task in the last decade. Images and Point Clouds (PCs) are fundamental data representations, particularly in urban mapping applications. Textured 3D meshes integrate both data representations geometrically by wiring the PC and texturing the surface elements with available imagery. We present a mesh-centered holistic geometry-driven methodology that explicitly integrates entities of imagery, PC and mesh. Due to its integrative character, we choose the mesh as the core representation that also helps to solve the visibility problem for points in imagery. Utilizing the proposed multi-modal fusion as the backbone and considering the established entity relationships, we enable the sharing of information across the modalities imagery, PC and mesh in a two-fold manner: (i) feature transfer and (ii) label transfer. By these means, we achieve to enrich feature vectors to multi-modal feature vectors for each representation. Concurrently, we achieve to label all representations consistently while reducing the manual label effort to a single representation. Consequently, we facilitate to train machine learning algorithms and to semantically segment any of these data representations - both in a multi-modal and single-modal sense. The paper presents the association mechanism and the subsequent information transfer, which we believe are cornerstones for multi-modal scene analysis. Furthermore, we discuss the preconditions and limitations of the presented approach in detail. We demonstrate the effectiveness of our methodology on the ISPRS 3D semantic labeling contest (Vaihingen 3D) and a proprietary data set (Hessigheim 3D).