 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedeadtrees.earth-aerial: A Multi-Resolution Aerial Image Dataset for Tree Cover and Mortality Detection
May 19, 2026Forests worldwide are increasingly threatened by climate change and disturbances such as fire, pests, and pathogens, creating an urgent need for scalable monitoring of tree cover and tree mortality. Aerial imagery from drones and aircraft is a key data source for detailed and large-scale mapping of tree crowns and mortality. However, related progress is limited by the lack of globally representative, harmonized datasets for joint segmentation of tree cover and mortality. We introduce two novel, open, machine-learning-ready datasets to enable joint segmentation of tree cover and tree mortality from centimeter-scale aerial imagery for the first time at global scales. With DTE-aerial-train, we provide a training dataset comprising 385K image patches of size 1024x1024 pixels, with resolutions ranging from 2.5 to 20 cm. It includes multi-class expert-annotated and -audited pseudo-labels for tree cover and mortality. With DTE-aerial-bench, we provide a geographically balanced benchmark test set of 25 globally distributed orthoimages totaling 525 patches with high-quality expert annotations for both tree cover and mortality. Both the training and benchmark datasets span tropical, temperate, boreal, and dryland biomes and cover a wide range of forest structures and mortality patterns. Using the benchmark test set for evaluation, we establish strong reference baselines that improve mortality segmentation across all biomes and scales with significant gains in challenging regions, such as boreal forests, where the F1 score increases from 0.40 to 0.58 with around 45% relative improvement. All data, models, and code will be publicly released under permissive open-source licenses. An interactive visualization of the benchmark dataset is available at deadtrees.earth/releases/dte-aerial-bench.
MIRANDA: MId-feature RANk-adversarial Domain Adaptation toward climate change-robust ecological forecasting with deep learning
Apr 01, 2026Plant phenology modelling aims to predict the timing of seasonal phases, such as leaf-out or flowering, from meteorological time series. Reliable predictions are crucial for anticipating ecosystem responses to climate change. While phenology modelling has traditionally relied on mechanistic approaches, deep learning methods have recently been proposed as flexible, data-driven alternatives with often superior performance. However, mechanistic models tend to outperform deep networks when data distribution shifts are induced by climate change. Domain Adaptation (DA) techniques could help address this limitation. Yet, unlike standard DA settings, climate change induces a temporal continuum of domains and involves both a covariate and label shift, with warmer records and earlier start of spring. To tackle this challenge, we introduce Mid-feature Rank-adversarial Domain Adaptation (MIRANDA). Whereas conventional adversarial methods enforce domain invariance on final latent representations, an approach that does not explicitly address label shift, we apply adversarial regularization to intermediate features. Moreover, instead of a binary domain-classification objective, we employ a rank-based objective that enforces year-invariance in the learned meteorological representations. On a country-scale dataset spanning 70 years and comprising 67,800 phenological observations of 5 tree species, we demonstrate that, unlike conventional DA approaches, MIRANDA improves robustness to climatic distribution shifts and narrows the performance gap with mechanistic models.
Tree crop mapping of South America reveals links to deforestation and conservation
Feb 19, 2026Monitoring tree crop expansion is vital for zero-deforestation policies like the European Union's Regulation on Deforestation-free Products (EUDR). However, these efforts are hindered by a lack of highresolution data distinguishing diverse agricultural systems from forests. Here, we present the first 10m-resolution tree crop map for South America, generated using a multi-modal, spatio-temporal deep learning model trained on Sentinel-1 and Sentinel-2 satellite imagery time series. The map identifies approximately 11 million hectares of tree crops, 23% of which is linked to 2000-2020 forest cover loss. Critically, our analysis reveals that existing regulatory maps supporting the EUDR often classify established agriculture, particularly smallholder agroforestry, as "forest". This discrepancy risks false deforestation alerts and unfair penalties for small-scale farmers. Our work mitigates this risk by providing a high-resolution baseline, supporting conservation policies that are effective, inclusive, and equitable.
LitePT: Lighter Yet Stronger Point Transformer
Dec 15, 2025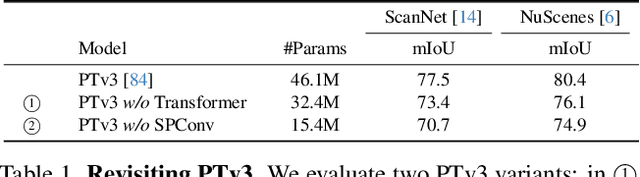
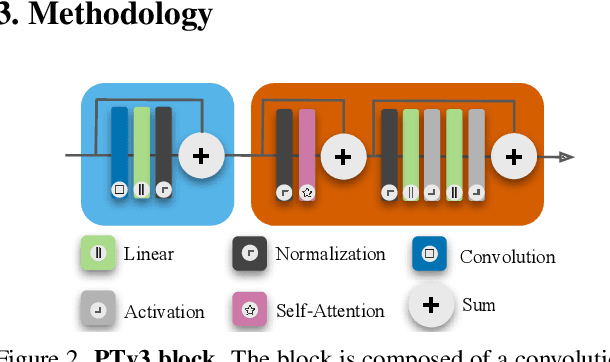
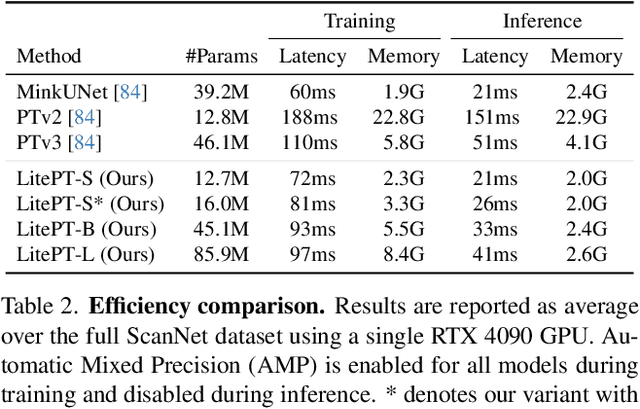
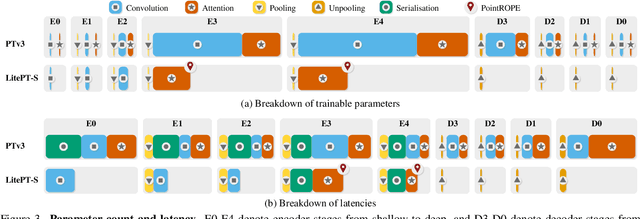
Modern neural architectures for 3D point cloud processing contain both convolutional layers and attention blocks, but the best way to assemble them remains unclear. We analyse the role of different computational blocks in 3D point cloud networks and find an intuitive behaviour: convolution is adequate to extract low-level geometry at high-resolution in early layers, where attention is expensive without bringing any benefits; attention captures high-level semantics and context in low-resolution, deep layers more efficiently. Guided by this design principle, we propose a new, improved 3D point cloud backbone that employs convolutions in early stages and switches to attention for deeper layers. To avoid the loss of spatial layout information when discarding redundant convolution layers, we introduce a novel, training-free 3D positional encoding, PointROPE. The resulting LitePT model has $3.6\times$ fewer parameters, runs $2\times$ faster, and uses $2\times$ less memory than the state-of-the-art Point Transformer V3, but nonetheless matches or even outperforms it on a range of tasks and datasets. Code and models are available at: https://github.com/prs-eth/LitePT.
The Potential of Copernicus Satellites for Disaster Response: Retrieving Building Damage from Sentinel-1 and Sentinel-2
Nov 07, 2025
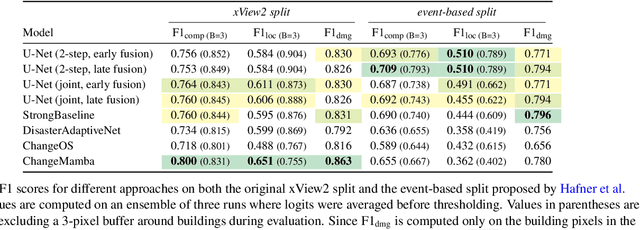

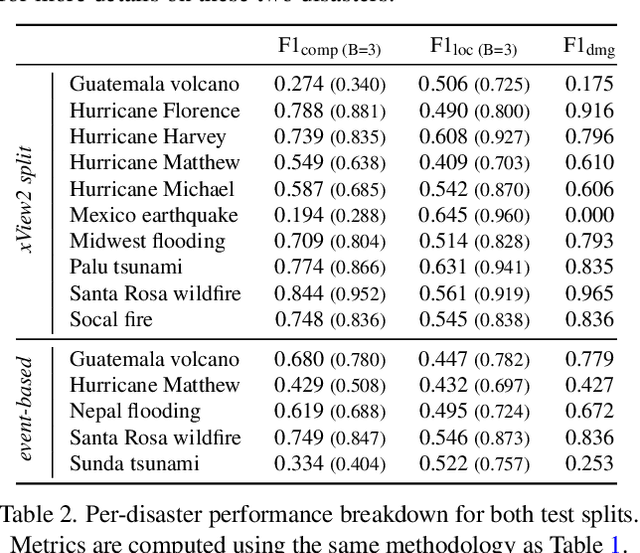
Natural disasters demand rapid damage assessment to guide humanitarian response. Here, we investigate whether medium-resolution Earth observation images from the Copernicus program can support building damage assessment, complementing very-high resolution imagery with often limited availability. We introduce xBD-S12, a dataset of 10,315 pre- and post-disaster image pairs from both Sentinel-1 and Sentinel-2, spatially and temporally aligned with the established xBD benchmark. In a series of experiments, we demonstrate that building damage can be detected and mapped rather well in many disaster scenarios, despite the moderate 10$\,$m ground sampling distance. We also find that, for damage mapping at that resolution, architectural sophistication does not seem to bring much advantage: more complex model architectures tend to struggle with generalization to unseen disasters, and geospatial foundation models bring little practical benefit. Our results suggest that Copernicus images are a viable data source for rapid, wide-area damage assessment and could play an important role alongside VHR imagery. We release the xBD-S12 dataset, code, and trained models to support further research.
SSL4Eco: A Global Seasonal Dataset for Geospatial Foundation Models in Ecology
Apr 25, 2025With the exacerbation of the biodiversity and climate crises, macroecological pursuits such as global biodiversity mapping become more urgent. Remote sensing offers a wealth of Earth observation data for ecological studies, but the scarcity of labeled datasets remains a major challenge. Recently, self-supervised learning has enabled learning representations from unlabeled data, triggering the development of pretrained geospatial models with generalizable features. However, these models are often trained on datasets biased toward areas of high human activity, leaving entire ecological regions underrepresented. Additionally, while some datasets attempt to address seasonality through multi-date imagery, they typically follow calendar seasons rather than local phenological cycles. To better capture vegetation seasonality at a global scale, we propose a simple phenology-informed sampling strategy and introduce corresponding SSL4Eco, a multi-date Sentinel-2 dataset, on which we train an existing model with a season-contrastive objective. We compare representations learned from SSL4Eco against other datasets on diverse ecological downstream tasks and demonstrate that our straightforward sampling method consistently improves representation quality, highlighting the importance of dataset construction. The model pretrained on SSL4Eco reaches state of the art performance on 7 out of 8 downstream tasks spanning (multi-label) classification and regression. We release our code, data, and model weights to support macroecological and computer vision research at https://github.com/PlekhanovaElena/ssl4eco.
Climplicit: Climatic Implicit Embeddings for Global Ecological Tasks
Apr 07, 2025Deep learning on climatic data holds potential for macroecological applications. However, its adoption remains limited among scientists outside the deep learning community due to storage, compute, and technical expertise barriers. To address this, we introduce Climplicit, a spatio-temporal geolocation encoder pretrained to generate implicit climatic representations anywhere on Earth. By bypassing the need to download raw climatic rasters and train feature extractors, our model uses x1000 fewer disk space and significantly reduces computational needs for downstream tasks. We evaluate our Climplicit embeddings on biomes classification, species distribution modeling, and plant trait regression. We find that linear probing our Climplicit embeddings consistently performs better or on par with training a model from scratch on downstream tasks and overall better than alternative geolocation encoding models.
GSR4B: Biomass Map Super-Resolution with Sentinel-1/2 Guidance
Apr 03, 2025

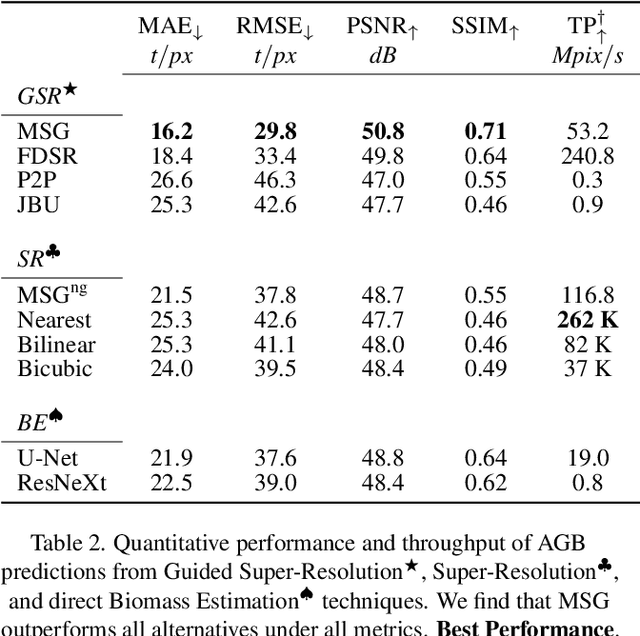

Accurate Above-Ground Biomass (AGB) mapping at both large scale and high spatio-temporal resolution is essential for applications ranging from climate modeling to biodiversity assessment, and sustainable supply chain monitoring. At present, fine-grained AGB mapping relies on costly airborne laser scanning acquisition campaigns usually limited to regional scales. Initiatives such as the ESA CCI map attempt to generate global biomass products from diverse spaceborne sensors but at a coarser resolution. To enable global, high-resolution (HR) mapping, several works propose to regress AGB from HR satellite observations such as ESA Sentinel-1/2 images. We propose a novel way to address HR AGB estimation, by leveraging both HR satellite observations and existing low-resolution (LR) biomass products. We cast this problem as Guided Super-Resolution (GSR), aiming at upsampling LR biomass maps (sources) from $100$ to $10$ m resolution, using auxiliary HR co-registered satellite images (guides). We compare super-resolving AGB maps with and without guidance, against direct regression from satellite images, on the public BioMassters dataset. We observe that Multi-Scale Guidance (MSG) outperforms direct regression both for regression ($-780$ t/ha RMSE) and perception ($+2.0$ dB PSNR) metrics, and better captures high-biomass values, without significant computational overhead. Interestingly, unlike the RGB+Depth setting they were originally designed for, our best-performing AGB GSR approaches are those that most preserve the guide image texture. Our results make a strong case for adopting the GSR framework for accurate HR biomass mapping at scale. Our code and model weights are made publicly available (https://github.com/kaankaramanofficial/GSR4B).
Lossy Neural Compression for Geospatial Analytics: A Review
Mar 03, 2025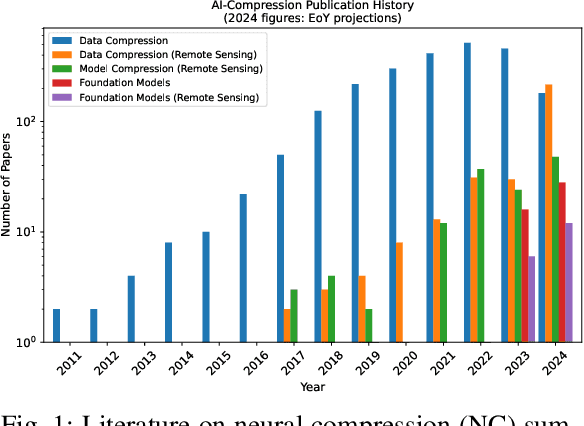
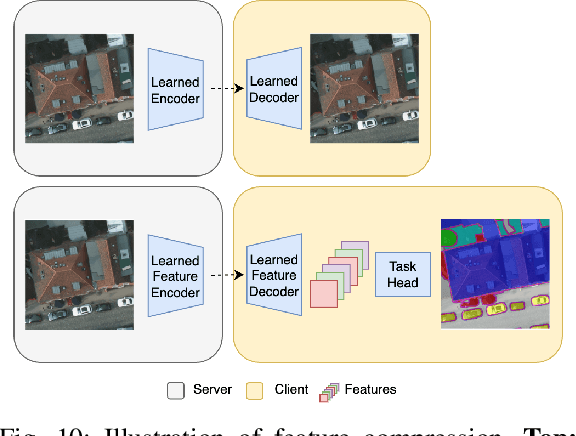
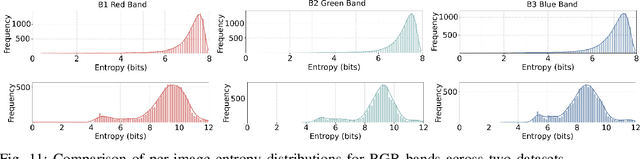
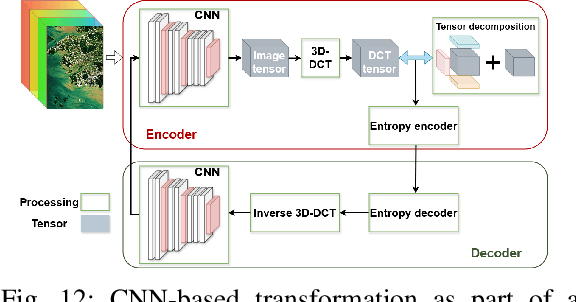
Over the past decades, there has been an explosion in the amount of available Earth Observation (EO) data. The unprecedented coverage of the Earth's surface and atmosphere by satellite imagery has resulted in large volumes of data that must be transmitted to ground stations, stored in data centers, and distributed to end users. Modern Earth System Models (ESMs) face similar challenges, operating at high spatial and temporal resolutions, producing petabytes of data per simulated day. Data compression has gained relevance over the past decade, with neural compression (NC) emerging from deep learning and information theory, making EO data and ESM outputs ideal candidates due to their abundance of unlabeled data. In this review, we outline recent developments in NC applied to geospatial data. We introduce the fundamental concepts of NC including seminal works in its traditional applications to image and video compression domains with focus on lossy compression. We discuss the unique characteristics of EO and ESM data, contrasting them with "natural images", and explain the additional challenges and opportunities they present. Moreover, we review current applications of NC across various EO modalities and explore the limited efforts in ESM compression to date. The advent of self-supervised learning (SSL) and foundation models (FM) has advanced methods to efficiently distill representations from vast unlabeled data. We connect these developments to NC for EO, highlighting the similarities between the two fields and elaborate on the potential of transferring compressed feature representations for machine--to--machine communication. Based on insights drawn from this review, we devise future directions relevant to applications in EO and ESM.
Deep learning meets tree phenology modeling: PhenoFormer vs. process-based models
Oct 30, 2024
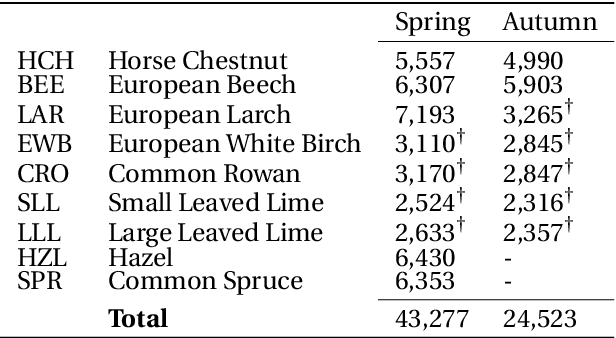
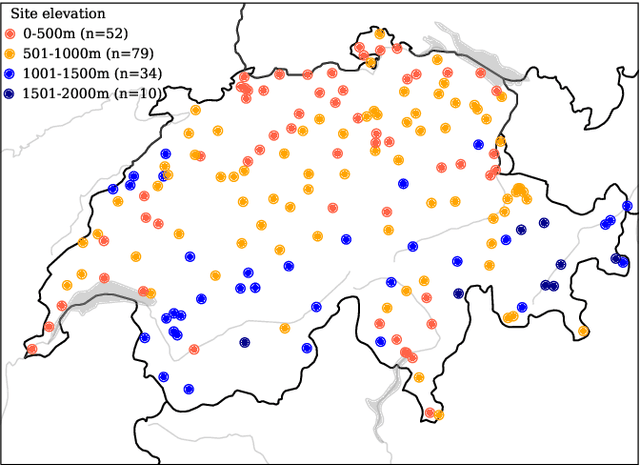

Phenology, the timing of cyclical plant life events such as leaf emergence and coloration, is crucial in the bio-climatic system. Climate change drives shifts in these phenological events, impacting ecosystems and the climate itself. Accurate phenology models are essential to predict the occurrence of these phases under changing climatic conditions. Existing methods include hypothesis-driven process models and data-driven statistical approaches. Process models account for dormancy stages and various phenology drivers, while statistical models typically rely on linear or traditional machine learning techniques. Research shows that process models often outperform statistical methods when predicting under climate conditions outside historical ranges, especially with climate change scenarios. However, deep learning approaches remain underexplored in climate phenology modeling. We introduce PhenoFormer, a neural architecture better suited than traditional statistical methods at predicting phenology under shift in climate data distribution, while also bringing significant improvements or performing on par to the best performing process-based models. Our numerical experiments on a 70-year dataset of 70,000 phenological observations from 9 woody species in Switzerland show that PhenoFormer outperforms traditional machine learning methods by an average of 13% R2 and 1.1 days RMSE for spring phenology, and 11% R2 and 0.7 days RMSE for autumn phenology, while matching or exceeding the best process-based models. Our results demonstrate that deep learning has the potential to be a valuable methodological tool for accurate climate-phenology prediction, and our PhenoFormer is a first promising step in improving phenological predictions before a complete understanding of the underlying physiological mechanisms is available.