 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupled Video Frame Interpolation and Encoding with Hybrid Event Cameras for Low-Power High-Framerate Video
Mar 28, 2025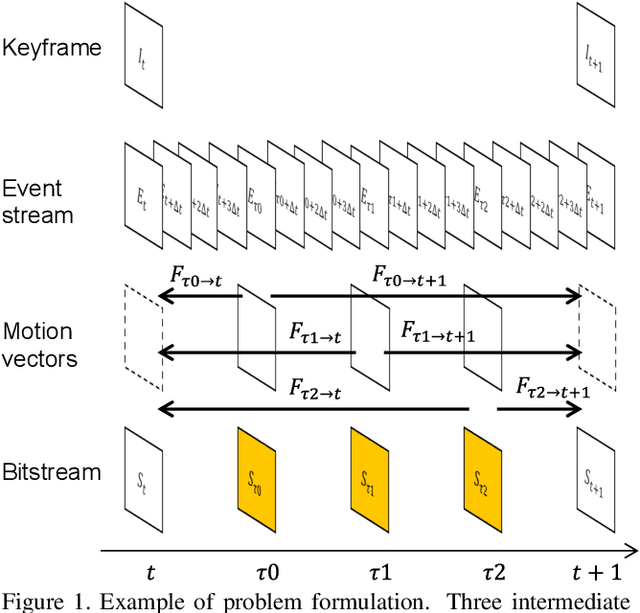
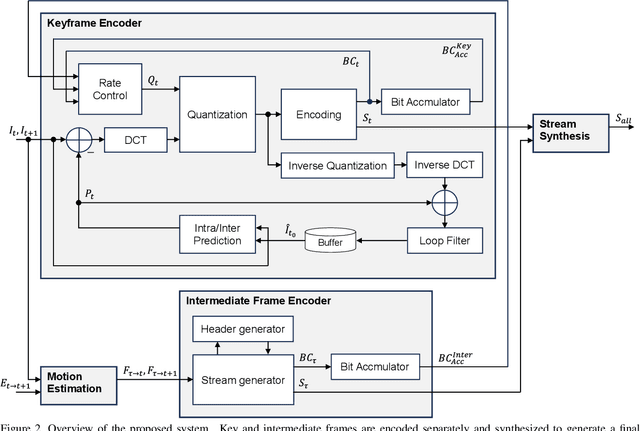
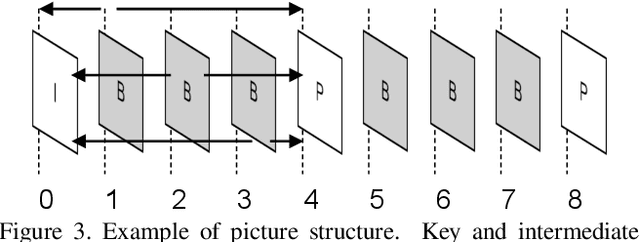
Every generation of mobile devices strives to capture video at higher resolution and frame rate than previous ones. This quality increase also requires additional power and computation to capture and encode high-quality media. We propose a method to reduce the overall power consumption for capturing high-quality videos in mobile devices. Using video frame interpolation (VFI), sensors can be driven at lower frame rate, which reduces sensor power consumption. With modern RGB hybrid event-based vision sensors (EVS), event data can be used to guide the interpolation, leading to results of much higher quality. If applied naively, interpolation methods can be expensive and lead to large amounts of intermediate data before video is encoded. This paper proposes a video encoder that generates a bitstream for high frame rate video without explicit interpolation. The proposed method estimates encoded video data (notably motion vectors) rather than frames. Thus, an encoded video file can be produced directly without explicitly producing intermediate frames.
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Dec 04, 2023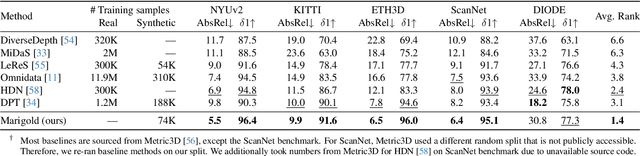
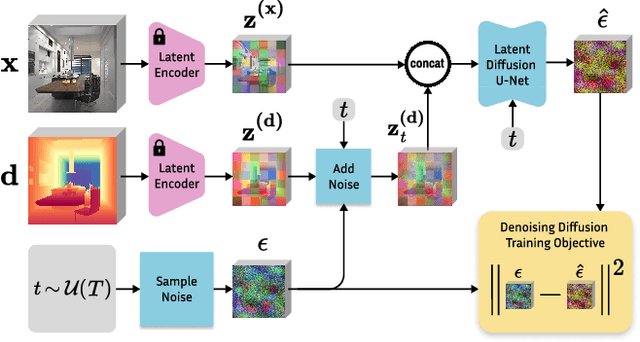
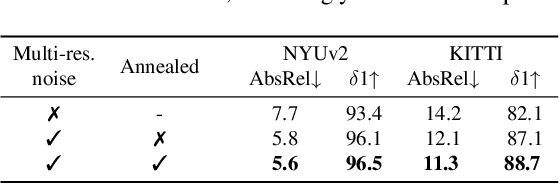
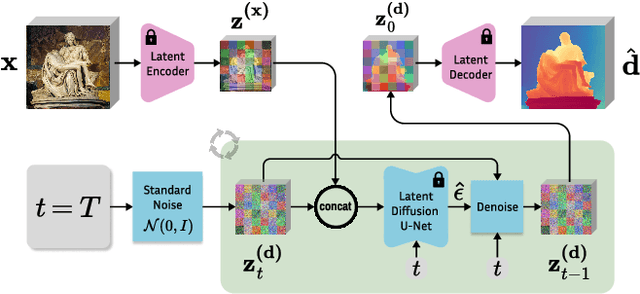
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
Neural Fields with Thermal Activations for Arbitrary-Scale Super-Resolution
Nov 29, 2023Recent approaches for arbitrary-scale single image super-resolution (ASSR) have used local neural fields to represent continuous signals that can be sampled at different rates. However, in such formulation, the point-wise query of field values does not naturally match the point spread function (PSF) of a given pixel. In this work we present a novel way to design neural fields such that points can be queried with a Gaussian PSF, which serves as anti-aliasing when moving across resolutions for ASSR. We achieve this using a novel activation function derived from Fourier theory and the heat equation. This comes at no additional cost: querying a point with a Gaussian PSF in our framework does not affect computational cost, unlike filtering in the image domain. Coupled with a hypernetwork, our method not only provides theoretically guaranteed anti-aliasing, but also sets a new bar for ASSR while also being more parameter-efficient than previous methods.
High-resolution Population Maps Derived from Sentinel-1 and Sentinel-2
Nov 23, 2023Detailed population maps play an important role in diverse fields ranging from humanitarian action to urban planning. Generating such maps in a timely and scalable manner presents a challenge, especially in data-scarce regions. To address it we have developed POPCORN, a population mapping method whose only inputs are free, globally available satellite images from Sentinel-1 and Sentinel-2; and a small number of aggregate population counts over coarse census districts for calibration. Despite the minimal data requirements our approach surpasses the mapping accuracy of existing schemes, including several that rely on building footprints derived from high-resolution imagery. E.g., we were able to produce population maps for Rwanda with 100m GSD based on less than 400 regional census counts. In Kigali, those maps reach an $R^2$ score of 66% w.r.t. a ground truth reference map, with an average error of only $\pm$10 inhabitants/ha. Conveniently, POPCORN retrieves explicit maps of built-up areas and of local building occupancy rates, making the mapping process interpretable and offering additional insights, for instance about the distribution of built-up, but unpopulated areas, e.g., industrial warehouses. Moreover, we find that, once trained, the model can be applied repeatedly to track population changes; and that it can be transferred to geographically similar regions, e.g., from Uganda to Rwanda). With our work we aim to democratize access to up-to-date and high-resolution population maps, recognizing that some regions faced with particularly strong population dynamics may lack the resources for costly micro-census campaigns.
Guided Depth Super-Resolution by Deep Anisotropic Diffusion
Nov 22, 2022Performing super-resolution of a depth image using the guidance from an RGB image is a problem that concerns several fields, such as robotics, medical imaging, and remote sensing. While deep learning methods have achieved good results in this problem, recent work highlighted the value of combining modern methods with more formal frameworks. In this work, we propose a novel approach which combines guided anisotropic diffusion with a deep convolutional network and advances the state of the art for guided depth super-resolution. The edge transferring/enhancing properties of the diffusion are boosted by the contextual reasoning capabilities of modern networks, and a strict adjustment step guarantees perfect adherence to the source image. We achieve unprecedented results in three commonly used benchmarks for guided depth super-resolution. The performance gain compared to other methods is the largest at larger scales, such as x32 scaling. Code for the proposed method will be made available to promote reproducibility of our results.
Satellite-based high-resolution maps of cocoa planted area for Côte d'Ivoire and Ghana
Jun 13, 2022
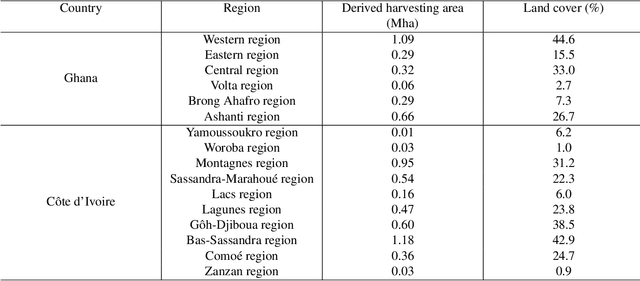
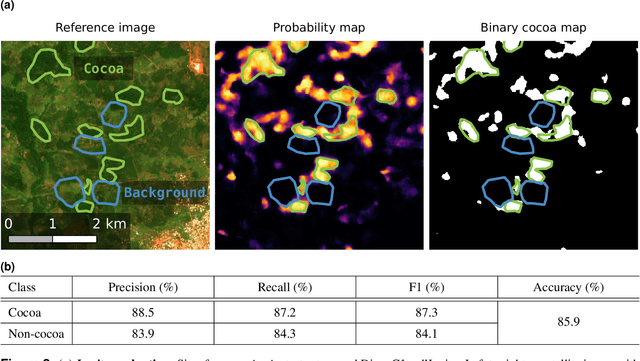
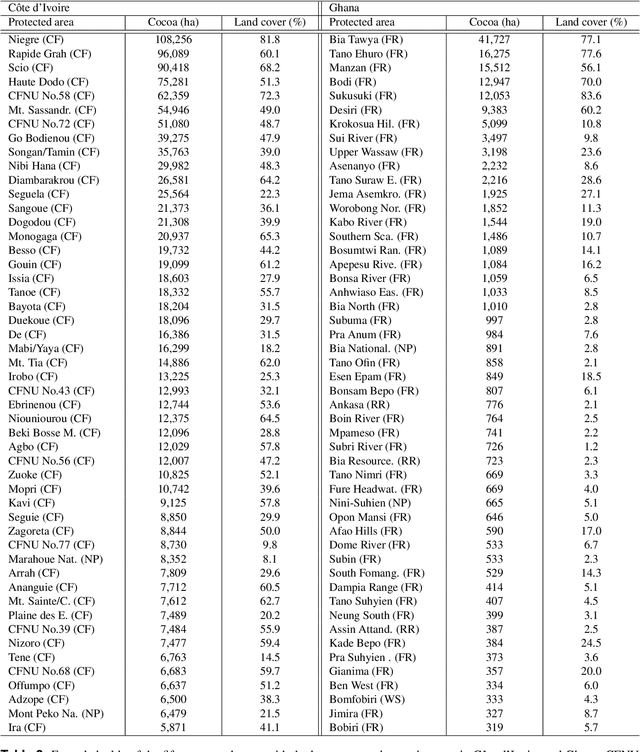
C\^ote d'Ivoire and Ghana, the world's largest producers of cocoa, account for two thirds of the global cocoa production. In both countries, cocoa is the primary perennial crop, providing income to almost two million farmers. Yet precise maps of cocoa planted area are missing, hindering accurate quantification of expansion in protected areas, production and yields, and limiting information available for improved sustainability governance. Here, we combine cocoa plantation data with publicly available satellite imagery in a deep learning framework and create high-resolution maps of cocoa plantations for both countries, validated in situ. Our results suggest that cocoa cultivation is an underlying driver of over 37% and 13% of forest loss in protected areas in C\^ote d'Ivoire and Ghana, respectively, and that official reports substantially underestimate the planted area, up to 40% in Ghana. These maps serve as a crucial building block to advance understanding of conservation and economic development in cocoa producing regions.
Zero-Shot Bird Species Recognition by Learning from Field Guides
Jun 03, 2022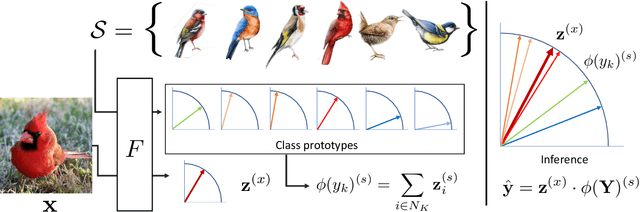
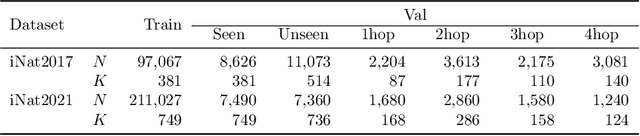
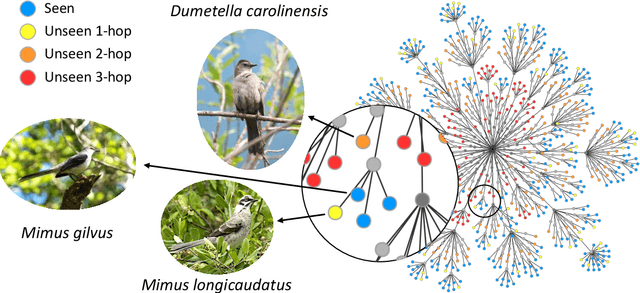

We exploit field guides to learn bird species recognition, in particular zero-shot recognition of unseen species. The illustrations contained in field guides deliberately focus on discriminative properties of a species, and can serve as side information to transfer knowledge from seen to unseen classes. We study two approaches: (1) a contrastive encoding of illustrations that can be fed into zero-shot learning schemes; and (2) a novel method that leverages the fact that illustrations are also images and as such structurally more similar to photographs than other kinds of side information. Our results show that illustrations from field guides, which are readily available for a wide range of species, are indeed a competitive source of side information. On the iNaturalist2021 subset, we obtain a harmonic mean from 749 seen and 739 unseen classes greater than $45\%$ (@top-10) and $15\%$ (@top-1). Which shows that field guides are a valuable option for challenging real-world scenarios with many species.
FiLM-Ensemble: Probabilistic Deep Learning via Feature-wise Linear Modulation
May 31, 2022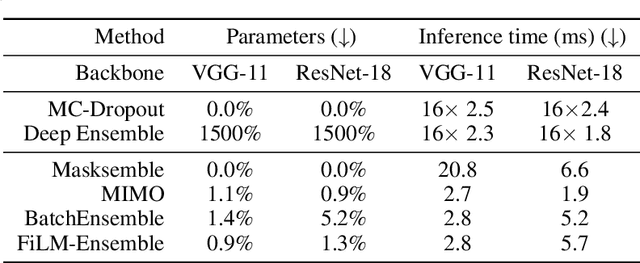
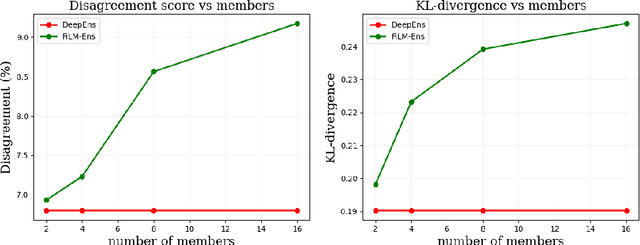
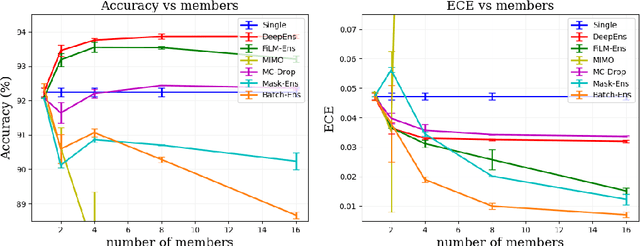
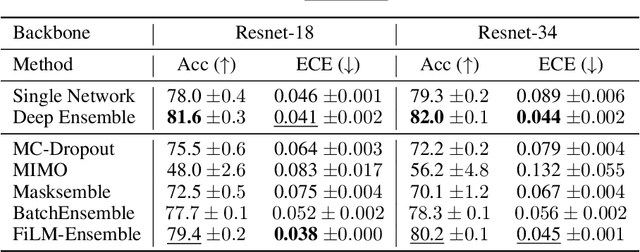
The ability to estimate epistemic uncertainty is often crucial when deploying machine learning in the real world, but modern methods often produce overconfident, uncalibrated uncertainty predictions. A common approach to quantify epistemic uncertainty, usable across a wide class of prediction models, is to train a model ensemble. In a naive implementation, the ensemble approach has high computational cost and high memory demand. This challenges in particular modern deep learning, where even a single deep network is already demanding in terms of compute and memory, and has given rise to a number of attempts to emulate the model ensemble without actually instantiating separate ensemble members. We introduce FiLM-Ensemble, a deep, implicit ensemble method based on the concept of Feature-wise Linear Modulation (FiLM). That technique was originally developed for multi-task learning, with the aim of decoupling different tasks. We show that the idea can be extended to uncertainty quantification: by modulating the network activations of a single deep network with FiLM, one obtains a model ensemble with high diversity, and consequently well-calibrated estimates of epistemic uncertainty, with low computational overhead in comparison. Empirically, FiLM-Ensemble outperforms other implicit ensemble methods, and it and comes very close to the upper bound of an explicit ensemble of networks (sometimes even beating it), at a fraction of the memory cost.
Weakly Supervised Change Detection Using Guided Anisotropic Difusion
Dec 31, 2021



Large scale datasets created from crowdsourced labels or openly available data have become crucial to provide training data for large scale learning algorithms. While these datasets are easier to acquire, the data are frequently noisy and unreliable, which is motivating research on weakly supervised learning techniques. In this paper we propose original ideas that help us to leverage such datasets in the context of change detection. First, we propose the guided anisotropic diffusion (GAD) algorithm, which improves semantic segmentation results using the input images as guides to perform edge preserving filtering. We then show its potential in two weakly-supervised learning strategies tailored for change detection. The first strategy is an iterative learning method that combines model optimisation and data cleansing using GAD to extract the useful information from a large scale change detection dataset generated from open vector data. The second one incorporates GAD within a novel spatial attention layer that increases the accuracy of weakly supervised networks trained to perform pixel-level predictions from image-level labels. Improvements with respect to state-of-the-art are demonstrated on 4 different public datasets.
Guided Anisotropic Diffusion and Iterative Learning for Weakly Supervised Change Detection
Apr 17, 2019



Large scale datasets created from user labels or openly available data have become crucial to provide training data for large scale learning algorithms. While these datasets are easier to acquire, the data are frequently noisy and unreliable, which is motivating research on weakly supervised learning techniques. In this paper we propose an iterative learning method that extracts the useful information from a large scale change detection dataset generated from open vector data to train a fully convolutional network which surpasses the performance obtained by naive supervised learning. We also propose the guided anisotropic diffusion algorithm, which improves semantic segmentation results using the input images as guides to perform edge preserving filtering, and is used in conjunction with the iterative training method to improve results.