 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeed for Speed: Zero-Shot Depth Completion with Single-Step Diffusion
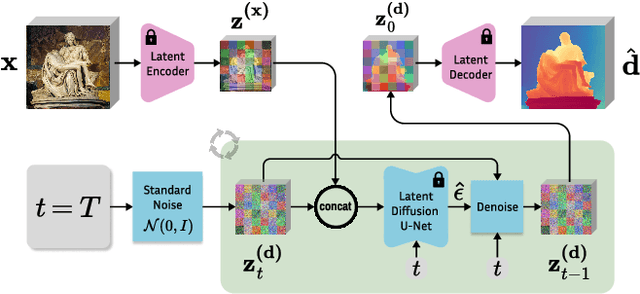
Mar 11, 2026We introduce Marigold-SSD, a single-step, late-fusion depth completion framework that leverages strong diffusion priors while eliminating the costly test-time optimization typically associated with diffusion-based methods. By shifting computational burden from inference to finetuning, our approach enables efficient and robust 3D perception under real-world latency constraints. Marigold-SSD achieves significantly faster inference with a training cost of only 4.5 GPU days. We evaluate our method across four indoor and two outdoor benchmarks, demonstrating strong cross-domain generalization and zero-shot performance compared to existing depth completion approaches. Our approach significantly narrows the efficiency gap between diffusion-based and discriminative models. Finally, we challenge common evaluation protocols by analyzing performance under varying input sparsity levels. Page: https://dtu-pas.github.io/marigold-ssd/
Elastic3D: Controllable Stereo Video Conversion with Guided Latent Decoding
Dec 16, 2025The growing demand for immersive 3D content calls for automated monocular-to-stereo video conversion. We present Elastic3D, a controllable, direct end-to-end method for upgrading a conventional video to a binocular one. Our approach, based on (conditional) latent diffusion, avoids artifacts due to explicit depth estimation and warping. The key to its high-quality stereo video output is a novel, guided VAE decoder that ensures sharp and epipolar-consistent stereo video output. Moreover, our method gives the user control over the strength of the stereo effect (more precisely, the disparity range) at inference time, via an intuitive, scalar tuning knob. Experiments on three different datasets of real-world stereo videos show that our method outperforms both traditional warping-based and recent warping-free baselines and sets a new standard for reliable, controllable stereo video conversion. Please check the project page for the video samples https://elastic3d.github.io.
The Potential of Copernicus Satellites for Disaster Response: Retrieving Building Damage from Sentinel-1 and Sentinel-2
Nov 07, 2025
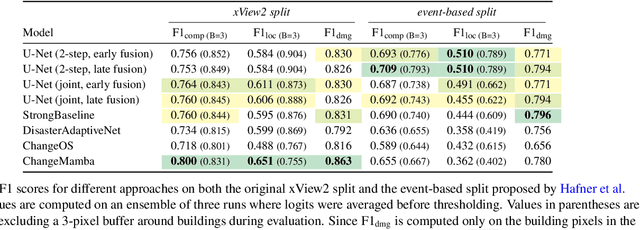

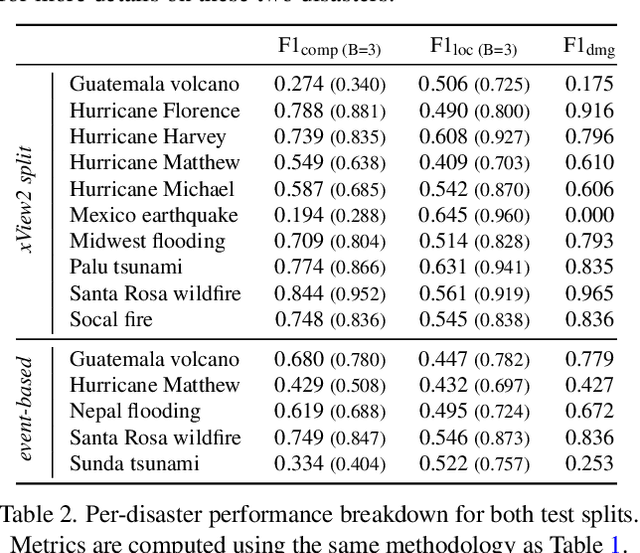
Natural disasters demand rapid damage assessment to guide humanitarian response. Here, we investigate whether medium-resolution Earth observation images from the Copernicus program can support building damage assessment, complementing very-high resolution imagery with often limited availability. We introduce xBD-S12, a dataset of 10,315 pre- and post-disaster image pairs from both Sentinel-1 and Sentinel-2, spatially and temporally aligned with the established xBD benchmark. In a series of experiments, we demonstrate that building damage can be detected and mapped rather well in many disaster scenarios, despite the moderate 10$\,$m ground sampling distance. We also find that, for damage mapping at that resolution, architectural sophistication does not seem to bring much advantage: more complex model architectures tend to struggle with generalization to unseen disasters, and geospatial foundation models bring little practical benefit. Our results suggest that Copernicus images are a viable data source for rapid, wide-area damage assessment and could play an important role alongside VHR imagery. We release the xBD-S12 dataset, code, and trained models to support further research.
Marigold: Affordable Adaptation of Diffusion-Based Image Generators for Image Analysis
May 14, 2025The success of deep learning in computer vision over the past decade has hinged on large labeled datasets and strong pretrained models. In data-scarce settings, the quality of these pretrained models becomes crucial for effective transfer learning. Image classification and self-supervised learning have traditionally been the primary methods for pretraining CNNs and transformer-based architectures. Recently, the rise of text-to-image generative models, particularly those using denoising diffusion in a latent space, has introduced a new class of foundational models trained on massive, captioned image datasets. These models' ability to generate realistic images of unseen content suggests they possess a deep understanding of the visual world. In this work, we present Marigold, a family of conditional generative models and a fine-tuning protocol that extracts the knowledge from pretrained latent diffusion models like Stable Diffusion and adapts them for dense image analysis tasks, including monocular depth estimation, surface normals prediction, and intrinsic decomposition. Marigold requires minimal modification of the pre-trained latent diffusion model's architecture, trains with small synthetic datasets on a single GPU over a few days, and demonstrates state-of-the-art zero-shot generalization. Project page: https://marigoldcomputervision.github.io
Marigold-DC: Zero-Shot Monocular Depth Completion with Guided Diffusion
Dec 18, 2024



Depth completion upgrades sparse depth measurements into dense depth maps guided by a conventional image. Existing methods for this highly ill-posed task operate in tightly constrained settings and tend to struggle when applied to images outside the training domain or when the available depth measurements are sparse, irregularly distributed, or of varying density. Inspired by recent advances in monocular depth estimation, we reframe depth completion as an image-conditional depth map generation guided by sparse measurements. Our method, Marigold-DC, builds on a pretrained latent diffusion model for monocular depth estimation and injects the depth observations as test-time guidance via an optimization scheme that runs in tandem with the iterative inference of denoising diffusion. The method exhibits excellent zero-shot generalization across a diverse range of environments and handles even extremely sparse guidance effectively. Our results suggest that contemporary monocular depth priors greatly robustify depth completion: it may be better to view the task as recovering dense depth from (dense) image pixels, guided by sparse depth; rather than as inpainting (sparse) depth, guided by an image. Project website: https://MarigoldDepthCompletion.github.io/
BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
Jul 25, 2024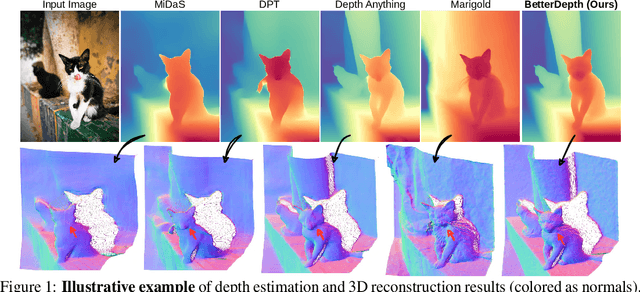

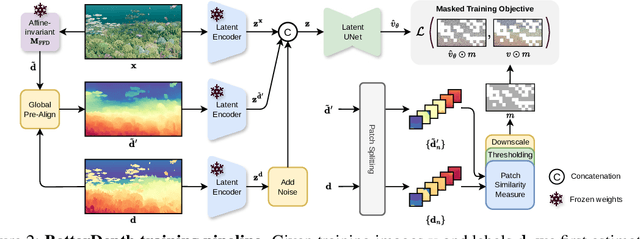
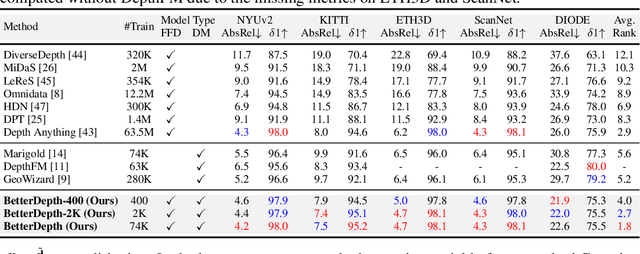
By training over large-scale datasets, zero-shot monocular depth estimation (MDE) methods show robust performance in the wild but often suffer from insufficiently precise details. Although recent diffusion-based MDE approaches exhibit appealing detail extraction ability, they still struggle in geometrically challenging scenes due to the difficulty of gaining robust geometric priors from diverse datasets. To leverage the complementary merits of both worlds, we propose BetterDepth to efficiently achieve geometrically correct affine-invariant MDE performance while capturing fine-grained details. Specifically, BetterDepth is a conditional diffusion-based refiner that takes the prediction from pre-trained MDE models as depth conditioning, in which the global depth context is well-captured, and iteratively refines details based on the input image. For the training of such a refiner, we propose global pre-alignment and local patch masking methods to ensure the faithfulness of BetterDepth to depth conditioning while learning to capture fine-grained scene details. By efficient training on small-scale synthetic datasets, BetterDepth achieves state-of-the-art zero-shot MDE performance on diverse public datasets and in-the-wild scenes. Moreover, BetterDepth can improve the performance of other MDE models in a plug-and-play manner without additional re-training.
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Dec 04, 2023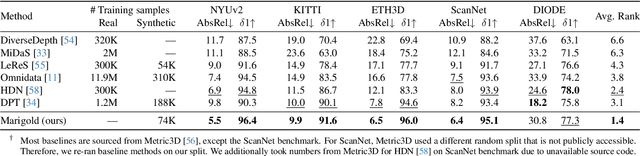
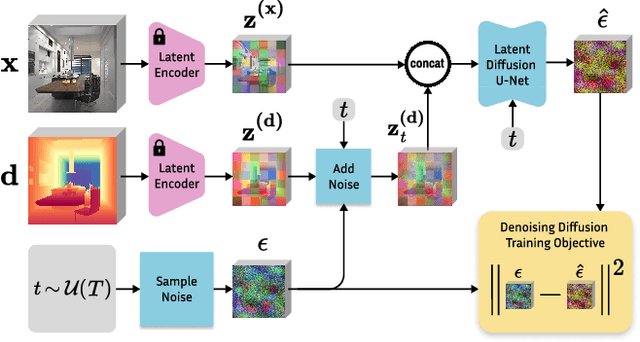
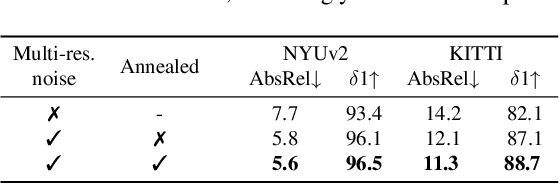
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
Neural Fields with Thermal Activations for Arbitrary-Scale Super-Resolution
Nov 29, 2023Recent approaches for arbitrary-scale single image super-resolution (ASSR) have used local neural fields to represent continuous signals that can be sampled at different rates. However, in such formulation, the point-wise query of field values does not naturally match the point spread function (PSF) of a given pixel. In this work we present a novel way to design neural fields such that points can be queried with a Gaussian PSF, which serves as anti-aliasing when moving across resolutions for ASSR. We achieve this using a novel activation function derived from Fourier theory and the heat equation. This comes at no additional cost: querying a point with a Gaussian PSF in our framework does not affect computational cost, unlike filtering in the image domain. Coupled with a hypernetwork, our method not only provides theoretically guaranteed anti-aliasing, but also sets a new bar for ASSR while also being more parameter-efficient than previous methods.
High-resolution Population Maps Derived from Sentinel-1 and Sentinel-2
Nov 23, 2023Detailed population maps play an important role in diverse fields ranging from humanitarian action to urban planning. Generating such maps in a timely and scalable manner presents a challenge, especially in data-scarce regions. To address it we have developed POPCORN, a population mapping method whose only inputs are free, globally available satellite images from Sentinel-1 and Sentinel-2; and a small number of aggregate population counts over coarse census districts for calibration. Despite the minimal data requirements our approach surpasses the mapping accuracy of existing schemes, including several that rely on building footprints derived from high-resolution imagery. E.g., we were able to produce population maps for Rwanda with 100m GSD based on less than 400 regional census counts. In Kigali, those maps reach an $R^2$ score of 66% w.r.t. a ground truth reference map, with an average error of only $\pm$10 inhabitants/ha. Conveniently, POPCORN retrieves explicit maps of built-up areas and of local building occupancy rates, making the mapping process interpretable and offering additional insights, for instance about the distribution of built-up, but unpopulated areas, e.g., industrial warehouses. Moreover, we find that, once trained, the model can be applied repeatedly to track population changes; and that it can be transferred to geographically similar regions, e.g., from Uganda to Rwanda). With our work we aim to democratize access to up-to-date and high-resolution population maps, recognizing that some regions faced with particularly strong population dynamics may lack the resources for costly micro-census campaigns.
Guided Depth Super-Resolution by Deep Anisotropic Diffusion
Nov 22, 2022Performing super-resolution of a depth image using the guidance from an RGB image is a problem that concerns several fields, such as robotics, medical imaging, and remote sensing. While deep learning methods have achieved good results in this problem, recent work highlighted the value of combining modern methods with more formal frameworks. In this work, we propose a novel approach which combines guided anisotropic diffusion with a deep convolutional network and advances the state of the art for guided depth super-resolution. The edge transferring/enhancing properties of the diffusion are boosted by the contextual reasoning capabilities of modern networks, and a strict adjustment step guarantees perfect adherence to the source image. We achieve unprecedented results in three commonly used benchmarks for guided depth super-resolution. The performance gain compared to other methods is the largest at larger scales, such as x32 scaling. Code for the proposed method will be made available to promote reproducibility of our results.