 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskSDM with Shapley values to improve flexibility, robustness, and explainability in species distribution modeling
Mar 17, 2025Species Distribution Models (SDMs) play a vital role in biodiversity research, conservation planning, and ecological niche modeling by predicting species distributions based on environmental conditions. The selection of predictors is crucial, strongly impacting both model accuracy and how well the predictions reflect ecological patterns. To ensure meaningful insights, input variables must be carefully chosen to match the study objectives and the ecological requirements of the target species. However, existing SDMs, including both traditional and deep learning-based approaches, often lack key capabilities for variable selection: (i) flexibility to choose relevant predictors at inference without retraining; (ii) robustness to handle missing predictor values without compromising accuracy; and (iii) explainability to interpret and accurately quantify each predictor's contribution. To overcome these limitations, we introduce MaskSDM, a novel deep learning-based SDM that enables flexible predictor selection by employing a masked training strategy. This approach allows the model to make predictions with arbitrary subsets of input variables while remaining robust to missing data. It also provides a clearer understanding of how adding or removing a given predictor affects model performance and predictions. Additionally, MaskSDM leverages Shapley values for precise predictor contribution assessments, improving upon traditional approximations. We evaluate MaskSDM on the global sPlotOpen dataset, modeling the distributions of 12,738 plant species. Our results show that MaskSDM outperforms imputation-based methods and approximates models trained on specific subsets of variables. These findings underscore MaskSDM's potential to increase the applicability and adoption of SDMs, laying the groundwork for developing foundation models in SDMs that can be readily applied to diverse ecological applications.
Multi-Scale and Multimodal Species Distribution Modeling
Nov 06, 2024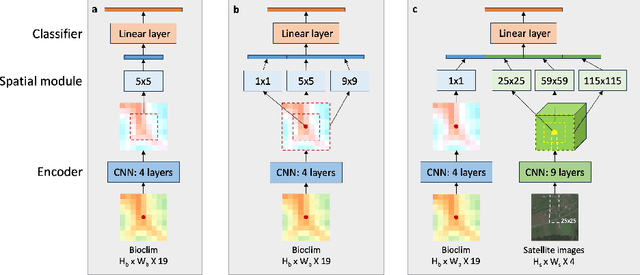
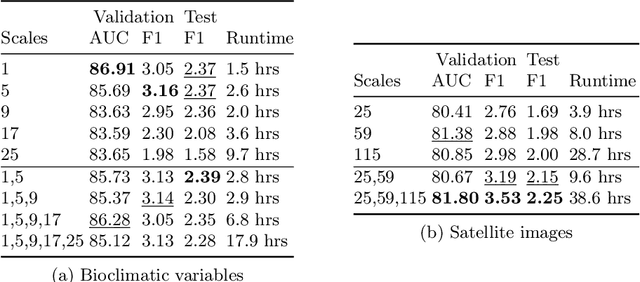
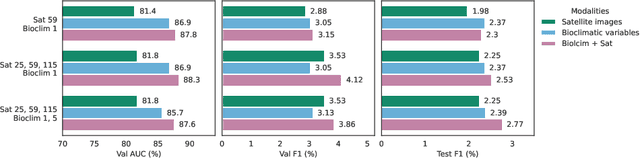
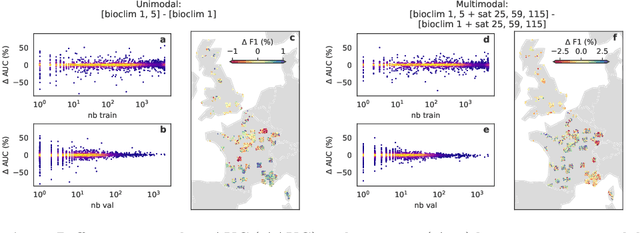
Species distribution models (SDMs) aim to predict the distribution of species by relating occurrence data with environmental variables. Recent applications of deep learning to SDMs have enabled new avenues, specifically the inclusion of spatial data (environmental rasters, satellite images) as model predictors, allowing the model to consider the spatial context around each species' observations. However, the appropriate spatial extent of the images is not straightforward to determine and may affect the performance of the model, as scale is recognized as an important factor in SDMs. We develop a modular structure for SDMs that allows us to test the effect of scale in both single- and multi-scale settings. Furthermore, our model enables different scales to be considered for different modalities, using a late fusion approach. Results on the GeoLifeCLEF 2023 benchmark indicate that considering multimodal data and learning multi-scale representations leads to more accurate models.
POLO -- Point-based, multi-class animal detection
Oct 15, 2024



Automated wildlife surveys based on drone imagery and object detection technology are a powerful and increasingly popular tool in conservation biology. Most detectors require training images with annotated bounding boxes, which are tedious, expensive, and not always unambiguous to create. To reduce the annotation load associated with this practice, we develop POLO, a multi-class object detection model that can be trained entirely on point labels. POLO is based on simple, yet effective modifications to the YOLOv8 architecture, including alterations to the prediction process, training losses, and post-processing. We test POLO on drone recordings of waterfowl containing up to multiple thousands of individual birds in one image and compare it to a regular YOLOv8. Our experiments show that at the same annotation cost, POLO achieves improved accuracy in counting animals in aerial imagery.
On the selection and effectiveness of pseudo-absences for species distribution modeling with deep learning
Jan 03, 2024



Species distribution modeling is a highly versatile tool for understanding the intricate relationship between environmental conditions and species occurrences. However, the available data often lacks information on confirmed species absence and is limited to opportunistically sampled, presence-only observations. To overcome this limitation, a common approach is to employ pseudo-absences, which are specific geographic locations designated as negative samples. While pseudo-absences are well-established for single-species distribution models, their application in the context of multi-species neural networks remains underexplored. Notably, the significant class imbalance between species presences and pseudo-absences is often left unaddressed. Moreover, the existence of different types of pseudo-absences (e.g., random and target-group background points) adds complexity to the selection process. Determining the optimal combination of pseudo-absences types is difficult and depends on the characteristics of the data, particularly considering that certain types of pseudo-absences can be used to mitigate geographic biases. In this paper, we demonstrate that these challenges can be effectively tackled by integrating pseudo-absences in the training of multi-species neural networks through modifications to the loss function. This adjustment involves assigning different weights to the distinct terms of the loss function, thereby addressing both the class imbalance and the choice of pseudo-absence types. Additionally, we propose a strategy to set these loss weights using spatial block cross-validation with presence-only data. We evaluate our approach using a benchmark dataset containing independent presence-absence data from six different regions and report improved results when compared to competing approaches.
Teaching Computer Vision for Ecology
Jan 05, 2023


Computer vision can accelerate ecology research by automating the analysis of raw imagery from sensors like camera traps, drones, and satellites. However, computer vision is an emerging discipline that is rarely taught to ecologists. This work discusses our experience teaching a diverse group of ecologists to prototype and evaluate computer vision systems in the context of an intensive hands-on summer workshop. We explain the workshop structure, discuss common challenges, and propose best practices. This document is intended for computer scientists who teach computer vision across disciplines, but it may also be useful to ecologists or other domain experts who are learning to use computer vision themselves.
Fine-grained Population Mapping from Coarse Census Counts and Open Geodata
Nov 08, 2022Fine-grained population maps are needed in several domains, like urban planning, environmental monitoring, public health, and humanitarian operations. Unfortunately, in many countries only aggregate census counts over large spatial units are collected, moreover, these are not always up-to-date. We present POMELO, a deep learning model that employs coarse census counts and open geodata to estimate fine-grained population maps with 100m ground sampling distance. Moreover, the model can also estimate population numbers when no census counts at all are available, by generalizing across countries. In a series of experiments for several countries in sub-Saharan Africa, the maps produced with POMELOare in good agreement with the most detailed available reference counts: disaggregation of coarse census counts reaches R2 values of 85-89%; unconstrained prediction in the absence of any counts reaches 48-69%.
Seeing biodiversity: perspectives in machine learning for wildlife conservation
Oct 25, 2021

Data acquisition in animal ecology is rapidly accelerating due to inexpensive and accessible sensors such as smartphones, drones, satellites, audio recorders and bio-logging devices. These new technologies and the data they generate hold great potential for large-scale environmental monitoring and understanding, but are limited by current data processing approaches which are inefficient in how they ingest, digest, and distill data into relevant information. We argue that machine learning, and especially deep learning approaches, can meet this analytic challenge to enhance our understanding, monitoring capacity, and conservation of wildlife species. Incorporating machine learning into ecological workflows could improve inputs for population and behavior models and eventually lead to integrated hybrid modeling tools, with ecological models acting as constraints for machine learning models and the latter providing data-supported insights. In essence, by combining new machine learning approaches with ecological domain knowledge, animal ecologists can capitalize on the abundance of data generated by modern sensor technologies in order to reliably estimate population abundances, study animal behavior and mitigate human/wildlife conflicts. To succeed, this approach will require close collaboration and cross-disciplinary education between the computer science and animal ecology communities in order to ensure the quality of machine learning approaches and train a new generation of data scientists in ecology and conservation.
How to find a good image-text embedding for remote sensing visual question answering?
Sep 24, 2021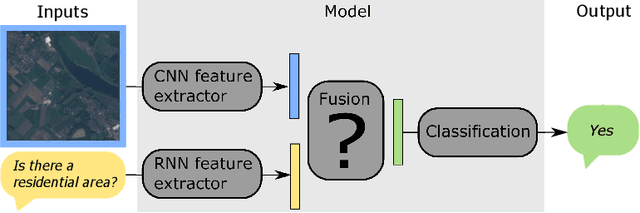
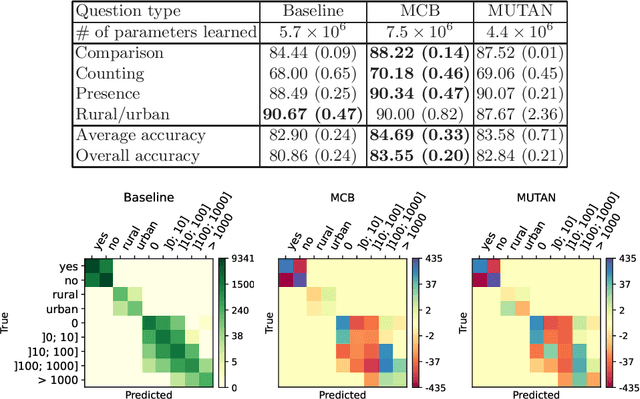
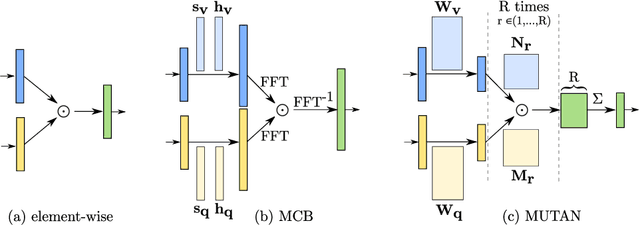

Visual question answering (VQA) has recently been introduced to remote sensing to make information extraction from overhead imagery more accessible to everyone. VQA considers a question (in natural language, therefore easy to formulate) about an image and aims at providing an answer through a model based on computer vision and natural language processing methods. As such, a VQA model needs to jointly consider visual and textual features, which is frequently done through a fusion step. In this work, we study three different fusion methodologies in the context of VQA for remote sensing and analyse the gains in accuracy with respect to the model complexity. Our findings indicate that more complex fusion mechanisms yield an improved performance, yet that seeking a trade-of between model complexity and performance is worthwhile in practice.
Self-Supervised Pretraining and Controlled Augmentation Improve Rare Wildlife Recognition in UAV Images
Aug 17, 2021

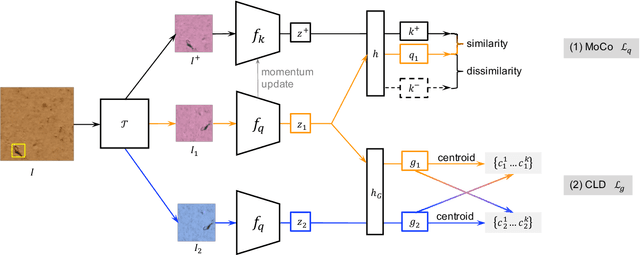

Automated animal censuses with aerial imagery are a vital ingredient towards wildlife conservation. Recent models are generally based on deep learning and thus require vast amounts of training data. Due to their scarcity and minuscule size, annotating animals in aerial imagery is a highly tedious process. In this project, we present a methodology to reduce the amount of required training data by resorting to self-supervised pretraining. In detail, we examine a combination of recent contrastive learning methodologies like Momentum Contrast (MoCo) and Cross-Level Instance-Group Discrimination (CLD) to condition our model on the aerial images without the requirement for labels. We show that a combination of MoCo, CLD, and geometric augmentations outperforms conventional models pre-trained on ImageNet by a large margin. Crucially, our method still yields favorable results even if we reduce the number of training animals to just 10%, at which point our best model scores double the recall of the baseline at similar precision. This effectively allows reducing the number of required annotations to a fraction while still being able to train high-accuracy models in such highly challenging settings.
Mapping Vulnerable Populations with AI
Jul 29, 2021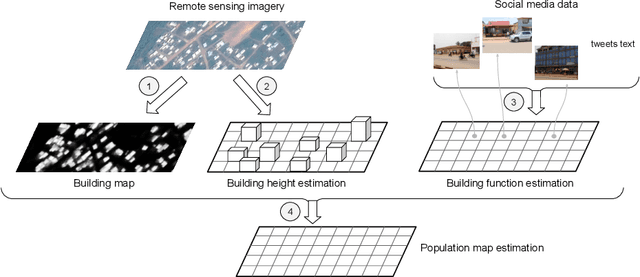


Humanitarian actions require accurate information to efficiently delegate support operations. Such information can be maps of building footprints, building functions, and population densities. While the access to this information is comparably easy in industrialized countries thanks to reliable census data and national geo-data infrastructures, this is not the case for developing countries, where that data is often incomplete or outdated. Building maps derived from remote sensing images may partially remedy this challenge in such countries, but are not always accurate due to different landscape configurations and lack of validation data. Even when they exist, building footprint layers usually do not reveal more fine-grained building properties, such as the number of stories or the building's function (e.g., office, residential, school, etc.). In this project we aim to automate building footprint and function mapping using heterogeneous data sources. In a first step, we intend to delineate buildings from satellite data, using deep learning models for semantic image segmentation. Building functions shall be retrieved by parsing social media data like for instance tweets, as well as ground-based imagery, to automatically identify different buildings functions and retrieve further information such as the number of building stories. Building maps augmented with those additional attributes make it possible to derive more accurate population density maps, needed to support the targeted provision of humanitarian aid.