 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskSDM with Shapley values to improve flexibility, robustness, and explainability in species distribution modeling
Mar 17, 2025Species Distribution Models (SDMs) play a vital role in biodiversity research, conservation planning, and ecological niche modeling by predicting species distributions based on environmental conditions. The selection of predictors is crucial, strongly impacting both model accuracy and how well the predictions reflect ecological patterns. To ensure meaningful insights, input variables must be carefully chosen to match the study objectives and the ecological requirements of the target species. However, existing SDMs, including both traditional and deep learning-based approaches, often lack key capabilities for variable selection: (i) flexibility to choose relevant predictors at inference without retraining; (ii) robustness to handle missing predictor values without compromising accuracy; and (iii) explainability to interpret and accurately quantify each predictor's contribution. To overcome these limitations, we introduce MaskSDM, a novel deep learning-based SDM that enables flexible predictor selection by employing a masked training strategy. This approach allows the model to make predictions with arbitrary subsets of input variables while remaining robust to missing data. It also provides a clearer understanding of how adding or removing a given predictor affects model performance and predictions. Additionally, MaskSDM leverages Shapley values for precise predictor contribution assessments, improving upon traditional approximations. We evaluate MaskSDM on the global sPlotOpen dataset, modeling the distributions of 12,738 plant species. Our results show that MaskSDM outperforms imputation-based methods and approximates models trained on specific subsets of variables. These findings underscore MaskSDM's potential to increase the applicability and adoption of SDMs, laying the groundwork for developing foundation models in SDMs that can be readily applied to diverse ecological applications.
Multi-Scale and Multimodal Species Distribution Modeling
Nov 06, 2024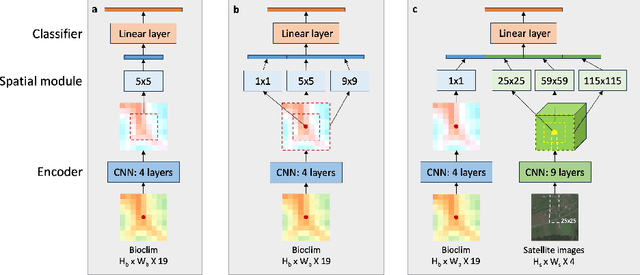
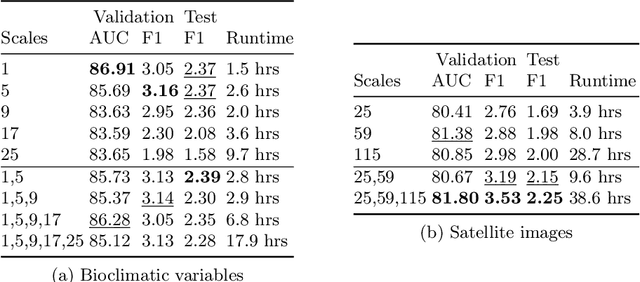
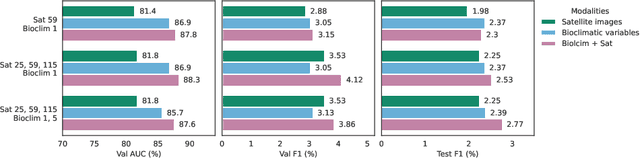
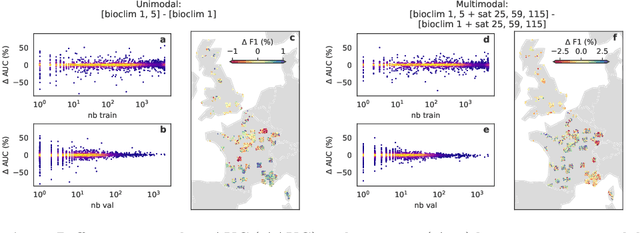
Species distribution models (SDMs) aim to predict the distribution of species by relating occurrence data with environmental variables. Recent applications of deep learning to SDMs have enabled new avenues, specifically the inclusion of spatial data (environmental rasters, satellite images) as model predictors, allowing the model to consider the spatial context around each species' observations. However, the appropriate spatial extent of the images is not straightforward to determine and may affect the performance of the model, as scale is recognized as an important factor in SDMs. We develop a modular structure for SDMs that allows us to test the effect of scale in both single- and multi-scale settings. Furthermore, our model enables different scales to be considered for different modalities, using a late fusion approach. Results on the GeoLifeCLEF 2023 benchmark indicate that considering multimodal data and learning multi-scale representations leads to more accurate models.
Imbalance-aware Presence-only Loss Function for Species Distribution Modeling
Mar 12, 2024

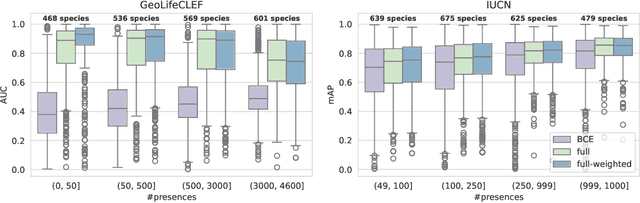

In the face of significant biodiversity decline, species distribution models (SDMs) are essential for understanding the impact of climate change on species habitats by connecting environmental conditions to species occurrences. Traditionally limited by a scarcity of species observations, these models have significantly improved in performance through the integration of larger datasets provided by citizen science initiatives. However, they still suffer from the strong class imbalance between species within these datasets, often resulting in the penalization of rare species--those most critical for conservation efforts. To tackle this issue, this study assesses the effectiveness of training deep learning models using a balanced presence-only loss function on large citizen science-based datasets. We demonstrate that this imbalance-aware loss function outperforms traditional loss functions across various datasets and tasks, particularly in accurately modeling rare species with limited observations.
On the selection and effectiveness of pseudo-absences for species distribution modeling with deep learning
Jan 03, 2024



Species distribution modeling is a highly versatile tool for understanding the intricate relationship between environmental conditions and species occurrences. However, the available data often lacks information on confirmed species absence and is limited to opportunistically sampled, presence-only observations. To overcome this limitation, a common approach is to employ pseudo-absences, which are specific geographic locations designated as negative samples. While pseudo-absences are well-established for single-species distribution models, their application in the context of multi-species neural networks remains underexplored. Notably, the significant class imbalance between species presences and pseudo-absences is often left unaddressed. Moreover, the existence of different types of pseudo-absences (e.g., random and target-group background points) adds complexity to the selection process. Determining the optimal combination of pseudo-absences types is difficult and depends on the characteristics of the data, particularly considering that certain types of pseudo-absences can be used to mitigate geographic biases. In this paper, we demonstrate that these challenges can be effectively tackled by integrating pseudo-absences in the training of multi-species neural networks through modifications to the loss function. This adjustment involves assigning different weights to the distinct terms of the loss function, thereby addressing both the class imbalance and the choice of pseudo-absence types. Additionally, we propose a strategy to set these loss weights using spatial block cross-validation with presence-only data. We evaluate our approach using a benchmark dataset containing independent presence-absence data from six different regions and report improved results when compared to competing approaches.
Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
Oct 10, 2023



Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at www.github.com/marccoru/locationencoder
Implementing and Experimenting with Diffusion Models for Text-to-Image Generation
Sep 22, 2022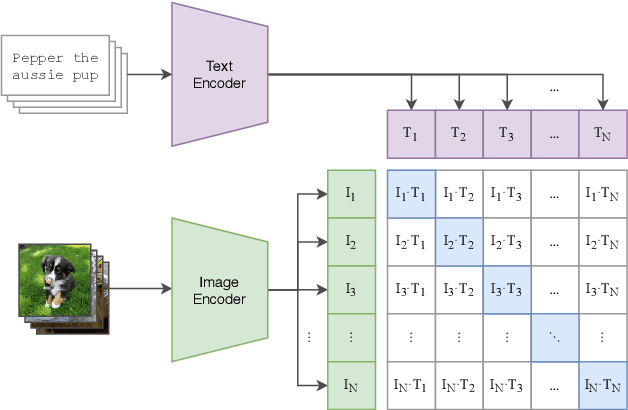

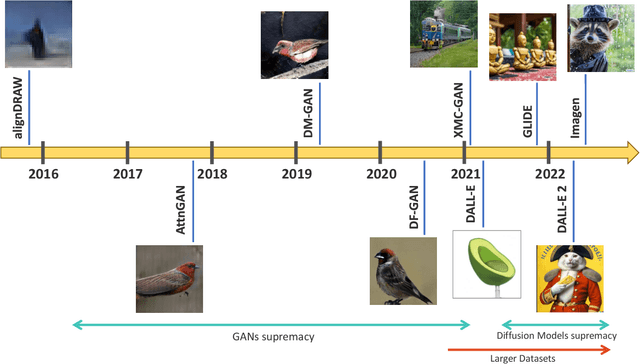
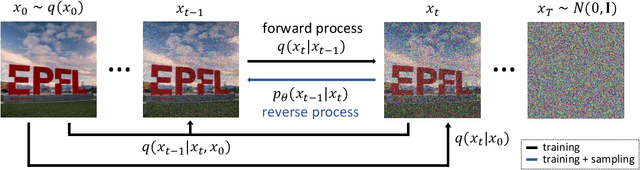
Taking advantage of the many recent advances in deep learning, text-to-image generative models currently have the merit of attracting the general public attention. Two of these models, DALL-E 2 and Imagen, have demonstrated that highly photorealistic images could be generated from a simple textual description of an image. Based on a novel approach for image generation called diffusion models, text-to-image models enable the production of many different types of high resolution images, where human imagination is the only limit. However, these models require exceptionally large amounts of computational resources to train, as well as handling huge datasets collected from the internet. In addition, neither the codebase nor the models have been released. It consequently prevents the AI community from experimenting with these cutting-edge models, making the reproduction of their results complicated, if not impossible. In this thesis, we aim to contribute by firstly reviewing the different approaches and techniques used by these models, and then by proposing our own implementation of a text-to-image model. Highly based on DALL-E 2, we introduce several slight modifications to tackle the high computational cost induced. We thus have the opportunity to experiment in order to understand what these models are capable of, especially in a low resource regime. In particular, we provide additional and analyses deeper than the ones performed by the authors of DALL-E 2, including ablation studies. Besides, diffusion models use so-called guidance methods to help the generating process. We introduce a new guidance method which can be used in conjunction with other guidance methods to improve image quality. Finally, the images generated by our model are of reasonably good quality, without having to sustain the significant training costs of state-of-the-art text-to-image models.
A User Study of Perceived Carbon Footprint
Dec 04, 2019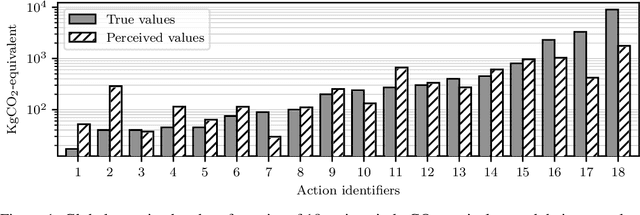
We propose a statistical model to understand people's perception of their carbon footprint. Driven by the observation that few people think of CO2 impact in absolute terms, we design a system to probe people's perception from simple pairwise comparisons of the relative carbon footprint of their actions. The formulation of the model enables us to take an active-learning approach to selecting the pairs of actions that are maximally informative about the model parameters. We define a set of 18 actions and collect a dataset of 2183 comparisons from 176 users on a university campus. The early results reveal promising directions to improve climate communication and enhance climate mitigation.