 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrain Where? Investigating How Pretraining Data Diversity Impacts Geospatial Foundation Model Performance
Apr 22, 2026New geospatial foundation models introduce a new model architecture and pretraining dataset, often sampled using different notions of data diversity. Performance differences are largely attributed to the model architecture or input modalities, while the role of the pretraining dataset is rarely studied. To address this research gap, we conducted a systematic study on how the geographic composition of pretraining data affects a model's downstream performance. We created global and per-continent pretraining datasets and evaluated them on global and per-continent downstream datasets. We found that the pretraining dataset from Europe outperformed global and continent-specific pretraining datasets on both global and local downstream evaluations. To investigate the factors influencing a pretraining dataset's downstream performance, we analysed 10 pretraining datasets using diversity across continents, biomes, landcover and spectral values. We found that only spectral diversity was strongly correlated with performance, while others were weakly correlated. This finding establishes a new dimension of diversity to be accounted for when creating a high-performing pretraining dataset. We open-sourced 7 new pretraining datasets, pretrained models, and our experimental framework at https://github.com/kerner-lab/pretrain-where.
A Proxy Consistency Loss for Grounded Fusion of Earth Observation and Location Encoders
Apr 20, 2026Supervised learning with Earth observation inputs is often limited by the sparsity of high-quality labeled or in-situ measured data to use as training labels. With the abundance of geographic data products, in many cases there are variables correlated with - but different from - the variable of interest that can be leveraged. We integrate such proxy variables within a geographic prior via a trainable location encoder and introduce a proxy consistency loss (PCL) formulation to imbue proxy data into the location encoder. The first key insight behind our approach is to use the location encoder as an agile and flexible way to learn from abundantly available proxy data which can be sampled independently of training label availability. Our second key insight is that we will need to regularize the location encoder appropriately to achieve performance and robustness with limited labeled data. Our experiments on air quality prediction and poverty mapping show that integrating proxy data implicitly through the location encoder outperforms using both as input to an observation encoder and fusion strategies that use frozen, pretrained location embeddings as a geographic prior. Superior performance for in-sample prediction shows that the PCL can incorporate rich information from the proxies, and superior out-of-sample prediction shows that the learned latent embeddings help generalize to areas without training labels.
Mapping on a Budget: Optimizing Spatial Data Collection for ML
Sep 03, 2025



In applications across agriculture, ecology, and human development, machine learning with satellite imagery (SatML) is limited by the sparsity of labeled training data. While satellite data cover the globe, labeled training datasets for SatML are often small, spatially clustered, and collected for other purposes (e.g., administrative surveys or field measurements). Despite the pervasiveness of this issue in practice, past SatML research has largely focused on new model architectures and training algorithms to handle scarce training data, rather than modeling data conditions directly. This leaves scientists and policymakers who wish to use SatML for large-scale monitoring uncertain about whether and how to collect additional data to maximize performance. Here, we present the first problem formulation for the optimization of spatial training data in the presence of heterogeneous data collection costs and realistic budget constraints, as well as novel methods for addressing this problem. In experiments simulating different problem settings across three continents and four tasks, our strategies reveal substantial gains from sample optimization. Further experiments delineate settings for which optimized sampling is particularly effective. The problem formulation and methods we introduce are designed to generalize across application domains for SatML; we put special emphasis on a specific problem setting where our coauthors can immediately use our findings to augment clustered agricultural surveys for SatML monitoring in Togo.
Classification Drives Geographic Bias in Street Scene Segmentation
Dec 15, 2024



Previous studies showed that image datasets lacking geographic diversity can lead to biased performance in models trained on them. While earlier work studied general-purpose image datasets (e.g., ImageNet) and simple tasks like image recognition, we investigated geo-biases in real-world driving datasets on a more complex task: instance segmentation. We examined if instance segmentation models trained on European driving scenes (Eurocentric models) are geo-biased. Consistent with previous work, we found that Eurocentric models were geo-biased. Interestingly, we found that geo-biases came from classification errors rather than localization errors, with classification errors alone contributing 10-90% of the geo-biases in segmentation and 19-88% of the geo-biases in detection. This showed that while classification is geo-biased, localization (including detection and segmentation) is geographically robust. Our findings show that in region-specific models (e.g., Eurocentric models), geo-biases from classification errors can be significantly mitigated by using coarser classes (e.g., grouping car, bus, and truck as 4-wheeler).
Contrasting local and global modeling with machine learning and satellite data: A case study estimating tree canopy height in African savannas
Nov 21, 2024While advances in machine learning with satellite imagery (SatML) are facilitating environmental monitoring at a global scale, developing SatML models that are accurate and useful for local regions remains critical to understanding and acting on an ever-changing planet. As increasing attention and resources are being devoted to training SatML models with global data, it is important to understand when improvements in global models will make it easier to train or fine-tune models that are accurate in specific regions. To explore this question, we contrast local and global training paradigms for SatML through a case study of tree canopy height (TCH) mapping in the Karingani Game Reserve, Mozambique. We find that recent advances in global TCH mapping do not necessarily translate to better local modeling abilities in our study region. Specifically, small models trained only with locally-collected data outperform published global TCH maps, and even outperform globally pretrained models that we fine-tune using local data. Analyzing these results further, we identify specific points of conflict and synergy between local and global modeling paradigms that can inform future research toward aligning local and global performance objectives in geospatial machine learning.
Combining Diverse Information for Coordinated Action: Stochastic Bandit Algorithms for Heterogeneous Agents
Aug 06, 2024


Stochastic multi-agent multi-armed bandits typically assume that the rewards from each arm follow a fixed distribution, regardless of which agent pulls the arm. However, in many real-world settings, rewards can depend on the sensitivity of each agent to their environment. In medical screening, disease detection rates can vary by test type; in preference matching, rewards can depend on user preferences; and in environmental sensing, observation quality can vary across sensors. Since past work does not specify how to allocate agents of heterogeneous but known sensitivity of these types in a stochastic bandit setting, we introduce a UCB-style algorithm, Min-Width, which aggregates information from diverse agents. In doing so, we address the joint challenges of (i) aggregating the rewards, which follow different distributions for each agent-arm pair, and (ii) coordinating the assignments of agents to arms. Min-Width facilitates efficient collaboration among heterogeneous agents, exploiting the known structure in the agents' reward functions to weight their rewards accordingly. We analyze the regret of Min-Width and conduct pseudo-synthetic and fully synthetic experiments to study the performance of different levels of information sharing. Our results confirm that the gains to modeling agent heterogeneity tend to be greater when the sensitivities are more varied across agents, while combining more information does not always improve performance.
Application-Driven Innovation in Machine Learning
Mar 26, 2024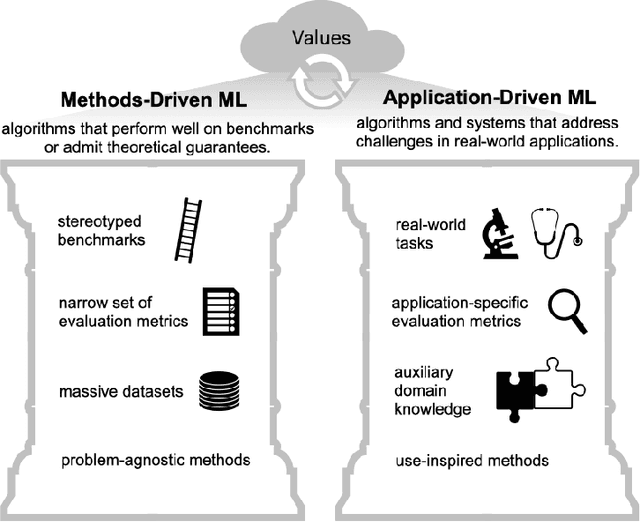
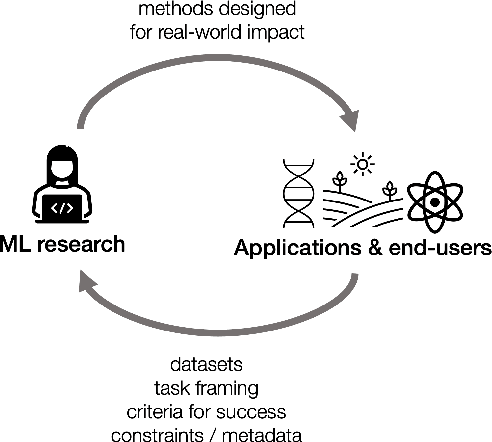
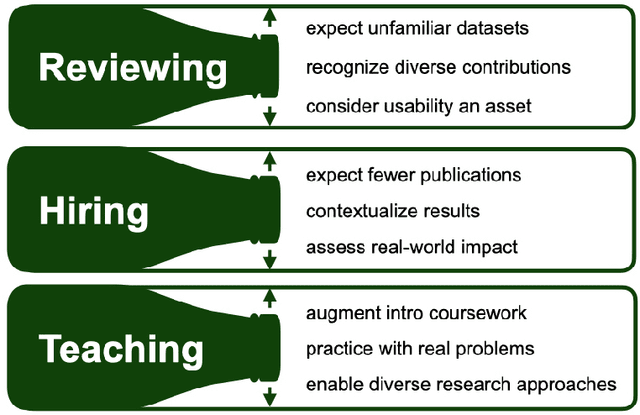
As applications of machine learning proliferate, innovative algorithms inspired by specific real-world challenges have become increasingly important. Such work offers the potential for significant impact not merely in domains of application but also in machine learning itself. In this paper, we describe the paradigm of application-driven research in machine learning, contrasting it with the more standard paradigm of methods-driven research. We illustrate the benefits of application-driven machine learning and how this approach can productively synergize with methods-driven work. Despite these benefits, we find that reviewing, hiring, and teaching practices in machine learning often hold back application-driven innovation. We outline how these processes may be improved.
Mission Critical -- Satellite Data is a Distinct Modality in Machine Learning
Feb 02, 2024Satellite data has the potential to inspire a seismic shift for machine learning -- one in which we rethink existing practices designed for traditional data modalities. As machine learning for satellite data (SatML) gains traction for its real-world impact, our field is at a crossroads. We can either continue applying ill-suited approaches, or we can initiate a new research agenda that centers around the unique characteristics and challenges of satellite data. This position paper argues that satellite data constitutes a distinct modality for machine learning research and that we must recognize it as such to advance the quality and impact of SatML research across theory, methods, and deployment. We outline critical discussion questions and actionable suggestions to transform SatML from merely an intriguing application area to a dedicated research discipline that helps move the needle on big challenges for machine learning and society.
SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
Nov 30, 2023



Geographic location is essential for modeling tasks in fields ranging from ecology to epidemiology to the Earth system sciences. However, extracting relevant and meaningful characteristics of a location can be challenging, often entailing expensive data fusion or data distillation from global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP), a global, general-purpose geographic location encoder that learns an implicit representation of locations from openly available satellite imagery. Trained location encoders provide vector embeddings summarizing the characteristics of any given location for convenient usage in diverse downstream tasks. We show that SatCLIP embeddings, pretrained on globally sampled multi-spectral Sentinel-2 satellite data, can be used in various predictive tasks that depend on location information but not necessarily satellite imagery, including temperature prediction, animal recognition in imagery, and population density estimation. Across tasks, SatCLIP embeddings consistently outperform embeddings from existing pretrained location encoders, ranging from models trained on natural images to models trained on semantic context. SatCLIP embeddings also help to improve geographic generalization. This demonstrates the potential of general-purpose location encoders and opens the door to learning meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
Oct 10, 2023



Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at www.github.com/marccoru/locationencoder