 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking over Regression for Bayesian Optimization and Molecule Selection
Oct 11, 2024



Bayesian optimization (BO) has become an indispensable tool for autonomous decision-making across diverse applications from autonomous vehicle control to accelerated drug and materials discovery. With the growing interest in self-driving laboratories, BO of chemical systems is crucial for machine learning (ML) guided experimental planning. Typically, BO employs a regression surrogate model to predict the distribution of unseen parts of the search space. However, for the selection of molecules, picking the top candidates with respect to a distribution, the relative ordering of their properties may be more important than their exact values. In this paper, we introduce Rank-based Bayesian Optimization (RBO), which utilizes a ranking model as the surrogate. We present a comprehensive investigation of RBO's optimization performance compared to conventional BO on various chemical datasets. Our results demonstrate similar or improved optimization performance using ranking models, particularly for datasets with rough structure-property landscapes and activity cliffs. Furthermore, we observe a high correlation between the surrogate ranking ability and BO performance, and this ability is maintained even at early iterations of BO optimization when using ranking surrogate models. We conclude that RBO is an effective alternative to regression-based BO, especially for optimizing novel chemical compounds.
Application-Driven Innovation in Machine Learning
Mar 26, 2024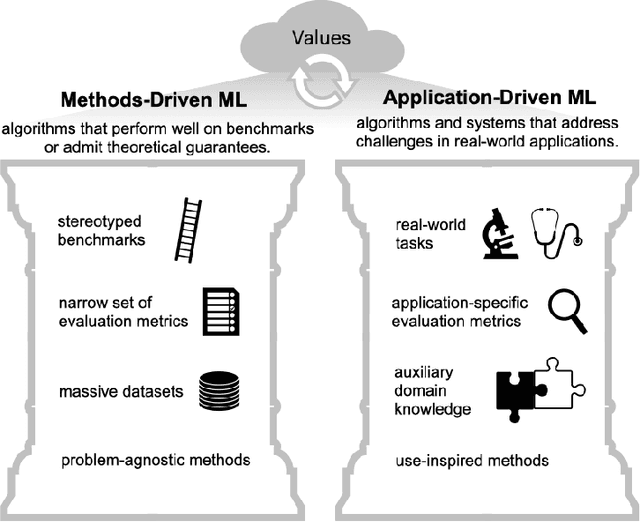
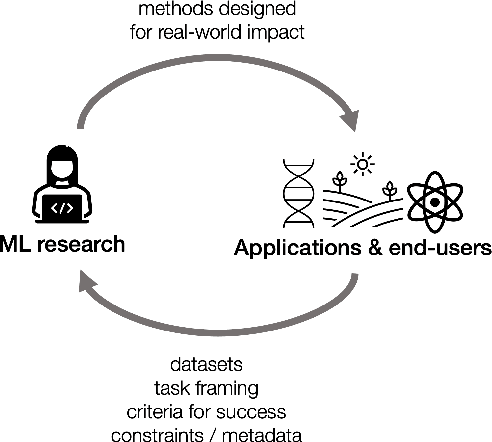
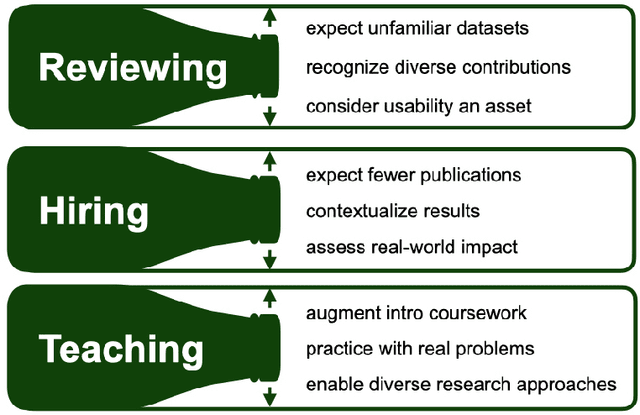
As applications of machine learning proliferate, innovative algorithms inspired by specific real-world challenges have become increasingly important. Such work offers the potential for significant impact not merely in domains of application but also in machine learning itself. In this paper, we describe the paradigm of application-driven research in machine learning, contrasting it with the more standard paradigm of methods-driven research. We illustrate the benefits of application-driven machine learning and how this approach can productively synergize with methods-driven work. Despite these benefits, we find that reviewing, hiring, and teaching practices in machine learning often hold back application-driven innovation. We outline how these processes may be improved.
Learning Zero-Shot Material States Segmentation, by Implanting Natural Image Patterns in Synthetic Data
Mar 14, 2024Visual understanding and segmentation of materials and their states is fundamental for understanding the physical world. The infinite textures, shapes, and often blurry boundaries formed by materials make this task particularly hard to generalize. Whether it's identifying wet regions of a surface, minerals in rocks, infected regions in plants, or pollution in water, each material state has its own unique form. For neural nets to learn general class-agnostic materials segmentation it is necessary to first collect and annotate data that capture this complexity. Collecting and manually annotating real-world images is limited by the cost and precision of manual labor. In contrast, synthetic CGI data is highly accurate and almost cost-free but fails to replicate the vast diversity of the material world. This work offers a method to bridge this crucial gap, by implanting patterns extracted from real-world images, in synthetic data. Hence, patterns automatically collected from natural images are used to map materials into synthetic scenes. This unsupervised approach allows the generated data to capture the vast complexity of the real world while maintaining the precision and scale of synthetic data. We also present the first general benchmark for class-agnostic material state segmentation. The benchmark contains a wide range of real-world images of material states, from cooking, food, rocks, construction, plants, and liquids each in various states (wet/dry/stained/cooked/burned/worn/rusted/sediment/foam...). The annotation includes both partial similarity between regions with similar but not identical materials, and hard segmentation of only points of the exact same material state. We show that net trains on MatSeg significantly outperform existing state-of-the-art methods on this task. The dataset, code, and trained model are available.
MVTrans: Multi-View Perception of Transparent Objects
Feb 22, 2023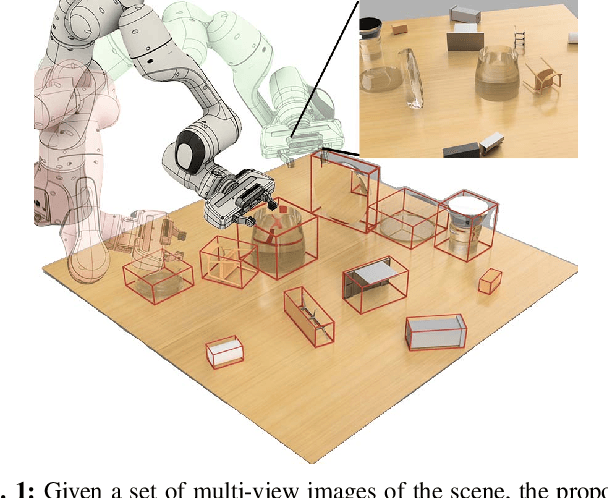

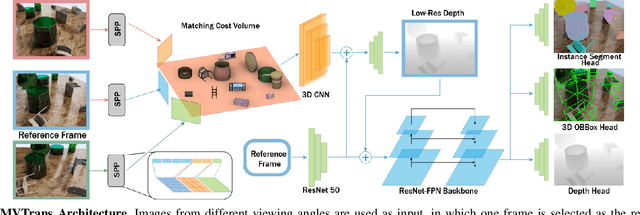

Transparent object perception is a crucial skill for applications such as robot manipulation in household and laboratory settings. Existing methods utilize RGB-D or stereo inputs to handle a subset of perception tasks including depth and pose estimation. However, transparent object perception remains to be an open problem. In this paper, we forgo the unreliable depth map from RGB-D sensors and extend the stereo based method. Our proposed method, MVTrans, is an end-to-end multi-view architecture with multiple perception capabilities, including depth estimation, segmentation, and pose estimation. Additionally, we establish a novel procedural photo-realistic dataset generation pipeline and create a large-scale transparent object detection dataset, Syn-TODD, which is suitable for training networks with all three modalities, RGB-D, stereo and multi-view RGB. Project Site: https://ac-rad.github.io/MVTrans/
An Adaptive Robotics Framework for Chemistry Lab Automation
Dec 19, 2022In the process of materials discovery, chemists currently need to perform many laborious, time-consuming, and often dangerous lab experiments. To accelerate this process, we propose a framework for robots to assist chemists by performing lab experiments autonomously. The solution allows a general-purpose robot to perform diverse chemistry experiments and efficiently make use of available lab tools. Our system can load high-level descriptions of chemistry experiments, perceive a dynamic workspace, and autonomously plan the required actions and motions to perform the given chemistry experiments with common tools found in the existing lab environment. Our architecture uses a modified PDDLStream solver for integrated task and constrained motion planning, which generates plans and motions that are guaranteed to be safe by preventing collisions and spillage. We present a modular framework that can scale to many different experiments, actions, and lab tools. In this work, we demonstrate the utility of our framework on three pouring skills and two foundational chemical experiments for materials synthesis: solubility and recrystallization. More experiments and updated evaluations can be found at https://ac-rad.github.io/arc-icra2023.
One-shot recognition of any material anywhere using contrastive learning with physics-based rendering
Dec 14, 2022


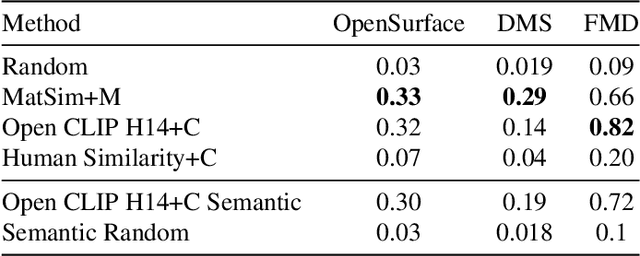
We present MatSim: a synthetic dataset, a benchmark, and a method for computer vision based recognition of similarities and transitions between materials and textures, focusing on identifying any material under any conditions using one or a few examples (one-shot learning). The visual recognition of materials is essential to everything from examining food while cooking to inspecting agriculture, chemistry, and industrial products. In this work, we utilize giant repositories used by computer graphics artists to generate a new CGI dataset for material similarity. We use physics-based rendering (PBR) repositories for visual material simulation, assign these materials random 3D objects, and render images with a vast range of backgrounds and illumination conditions (HDRI). We add a gradual transition between materials to support applications with a smooth transition between states (like gradually cooked food). We also render materials inside transparent containers to support beverage and chemistry lab use cases. We then train a contrastive learning network to generate a descriptor that identifies unfamiliar materials using a single image. We also present a new benchmark for a few-shot material recognition that contains a wide range of real-world examples, including the state of a chemical reaction, rotten/fresh fruits, states of food, different types of construction materials, types of ground, and many other use cases involving material states, transitions and subclasses. We show that a network trained on the MatSim synthetic dataset outperforms state-of-the-art models like Clip on the benchmark, despite being tested on material classes that were not seen during training. The dataset, benchmark, code and trained models are available online.
Calibration and generalizability of probabilistic models on low-data chemical datasets with DIONYSUS
Dec 06, 2022Deep learning models that leverage large datasets are often the state of the art for modelling molecular properties. When the datasets are smaller (< 2000 molecules), it is not clear that deep learning approaches are the right modelling tool. In this work we perform an extensive study of the calibration and generalizability of probabilistic machine learning models on small chemical datasets. Using different molecular representations and models, we analyse the quality of their predictions and uncertainties in a variety of tasks (binary, regression) and datasets. We also introduce two simulated experiments that evaluate their performance: (1) Bayesian optimization guided molecular design, (2) inference on out-of-distribution data via ablated cluster splits. We offer practical insights into model and feature choice for modelling small chemical datasets, a common scenario in new chemical experiments. We have packaged our analysis into the DIONYSUS repository, which is open sourced to aid in reproducibility and extension to new datasets.
Machine Learning for a Sustainable Energy Future
Oct 19, 2022Transitioning from fossil fuels to renewable energy sources is a critical global challenge; it demands advances at the levels of materials, devices, and systems for the efficient harvesting, storage, conversion, and management of renewable energy. Researchers globally have begun incorporating machine learning (ML) techniques with the aim of accelerating these advances. ML technologies leverage statistical trends in data to build models for prediction of material properties, generation of candidate structures, optimization of processes, among other uses; as a result, they can be incorporated into discovery and development pipelines to accelerate progress. Here we review recent advances in ML-driven energy research, outline current and future challenges, and describe what is required moving forward to best lever ML techniques. To start, we give an overview of key ML concepts. We then introduce a set of key performance indicators to help compare the benefits of different ML-accelerated workflows for energy research. We discuss and evaluate the latest advances in applying ML to the development of energy harvesting (photovoltaics), storage (batteries), conversion (electrocatalysis), and management (smart grids). Finally, we offer an outlook of potential research areas in the energy field that stand to further benefit from the application of ML.
AlphaFold Accelerates Artificial Intelligence Powered Drug Discovery: Efficient Discovery of a Novel Cyclin-dependent Kinase 20 (CDK20) Small Molecule Inhibitor
Jan 21, 2022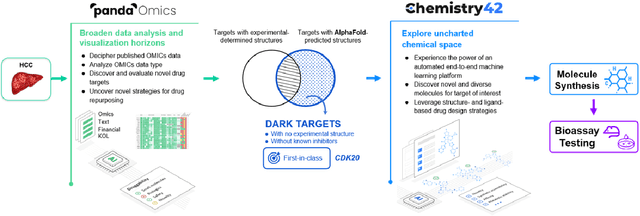

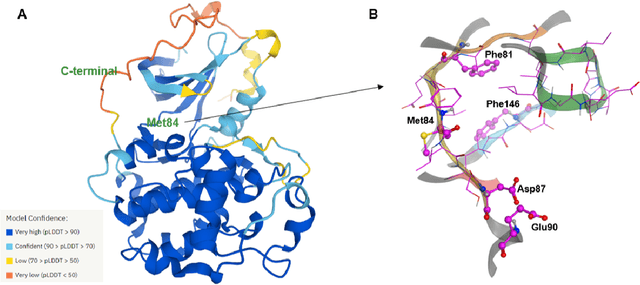
The AlphaFold computer program predicted protein structures for the whole human genome, which has been considered as a remarkable breakthrough both in artificial intelligence (AI) application and structural biology. Despite the varying confidence level, these predicted structures still could significantly contribute to the structure-based drug design of novel targets, especially the ones with no or limited structural information. In this work, we successfully applied AlphaFold in our end-to-end AI-powered drug discovery engines constituted of a biocomputational platform PandaOmics and a generative chemistry platform Chemistry42, to identify a first-in-class hit molecule of a novel target without an experimental structure starting from target selection towards hit identification in a cost- and time-efficient manner. PandaOmics provided the targets of interest and Chemistry42 generated the molecules based on the AlphaFold predicted structure, and the selected molecules were synthesized and tested in biological assays. Through this approach, we identified a small molecule hit compound for CDK20 with a Kd value of 8.9 +/- 1.6 uM (n = 4) within 30 days from target selection and after only synthesizing 7 compounds. To the best of our knowledge, this is the first reported small molecule targeting CDK20 and more importantly, this work is the first demonstration of AlphaFold application in the hit identification process in early drug discovery.
Predicting 3D shapes, masks, and properties of materials, liquids, and objects inside transparent containers, using the TransProteus CGI dataset
Sep 15, 2021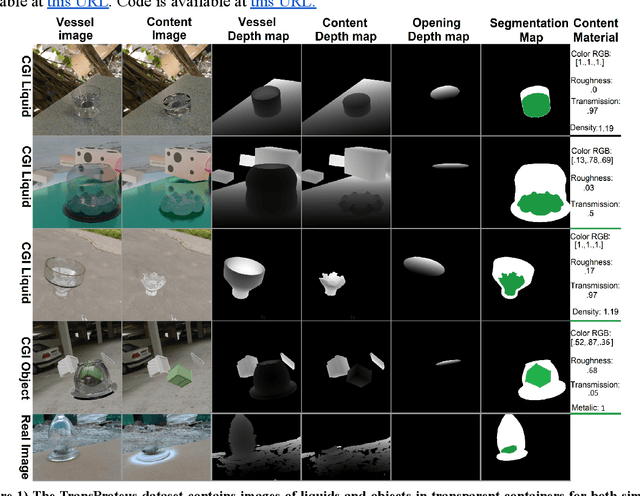
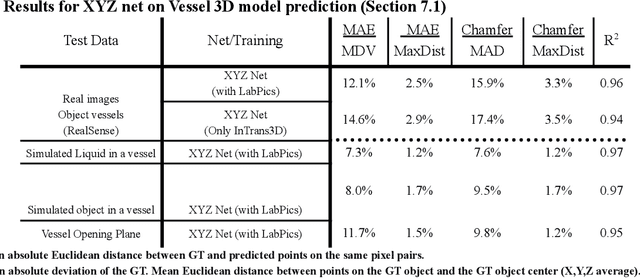
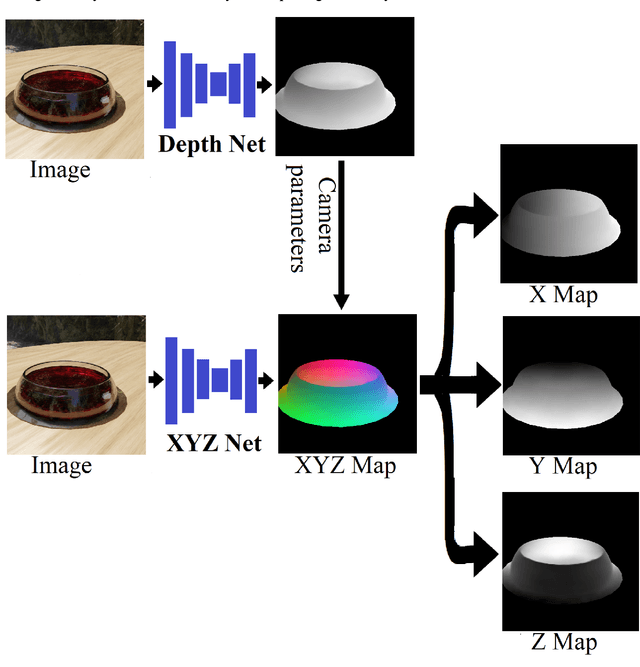
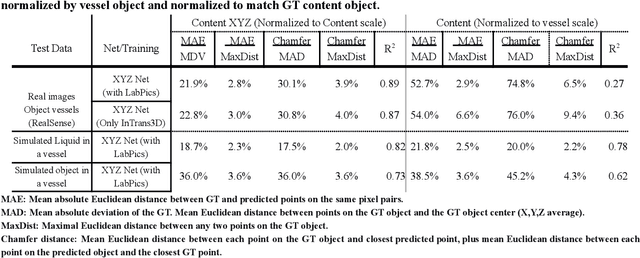
We present TransProteus, a dataset, and methods for predicting the 3D structure, masks, and properties of materials, liquids, and objects inside transparent vessels from a single image without prior knowledge of the image source and camera parameters. Manipulating materials in transparent containers is essential in many fields and depends heavily on vision. This work supplies a new procedurally generated dataset consisting of 50k images of liquids and solid objects inside transparent containers. The image annotations include 3D models, material properties (color/transparency/roughness...), and segmentation masks for the vessel and its content. The synthetic (CGI) part of the dataset was procedurally generated using 13k different objects, 500 different environments (HDRI), and 1450 material textures (PBR) combined with simulated liquids and procedurally generated vessels. In addition, we supply 104 real-world images of objects inside transparent vessels with depth maps of both the vessel and its content. We propose a camera agnostic method that predicts 3D models from an image as an XYZ map. This allows the trained net to predict the 3D model as a map with XYZ coordinates per pixel without prior knowledge of the image source. To calculate the training loss, we use the distance between pairs of points inside the 3D model instead of the absolute XYZ coordinates. This makes the loss function translation invariant. We use this to predict 3D models of vessels and their content from a single image. Finally, we demonstrate a net that uses a single image to predict the material properties of the vessel content and surface.