 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Jailbreaking of Large Models by Freeze Training: Lower Layers Exhibit Greater Sensitivity to Harmful Content
Feb 28, 2025



With the widespread application of Large Language Models across various domains, their security issues have increasingly garnered significant attention from both academic and industrial communities. This study conducts sampling and normalization of the parameters of the LLM to generate visual representations and heatmaps of parameter distributions, revealing notable discrepancies in parameter distributions among certain layers within the hidden layers. Further analysis involves calculating statistical metrics for each layer, followed by the computation of a Comprehensive Sensitivity Score based on these metrics, which identifies the lower layers as being particularly sensitive to the generation of harmful content. Based on this finding, we employ a Freeze training strategy, selectively performing Supervised Fine-Tuning only on the lower layers. Experimental results demonstrate that this method significantly reduces training duration and GPU memory consumption while maintaining a high jailbreak success rate and a high harm score, outperforming the results achieved by applying the LoRA method for SFT across all layers. Additionally, the method has been successfully extended to other open-source large models, validating its generality and effectiveness across different model architectures. Furthermore, we compare our method with ohter jailbreak method, demonstrating the superior performance of our approach. By innovatively proposing a method to statistically analyze and compare large model parameters layer by layer, this study provides new insights into the interpretability of large models. These discoveries emphasize the necessity of continuous research and the implementation of adaptive security measures in the rapidly evolving field of LLMs to prevent potential jailbreak attack risks, thereby promoting the development of more robust and secure LLMs.
ViFi-ReID: A Two-Stream Vision-WiFi Multimodal Approach for Person Re-identification
Oct 13, 2024



Person re-identification(ReID), as a crucial technology in the field of security, plays a vital role in safety inspections, personnel counting, and more. Most current ReID approaches primarily extract features from images, which are easily affected by objective conditions such as clothing changes and occlusions. In addition to cameras, we leverage widely available routers as sensing devices by capturing gait information from pedestrians through the Channel State Information (CSI) in WiFi signals and contribute a multimodal dataset. We employ a two-stream network to separately process video understanding and signal analysis tasks, and conduct multi-modal fusion and contrastive learning on pedestrian video and WiFi data. Extensive experiments in real-world scenarios demonstrate that our method effectively uncovers the correlations between heterogeneous data, bridges the gap between visual and signal modalities, significantly expands the sensing range, and improves ReID accuracy across multiple sensors.
Time-Frequency Analysis of Variable-Length WiFi CSI Signals for Person Re-Identification
Jul 12, 2024

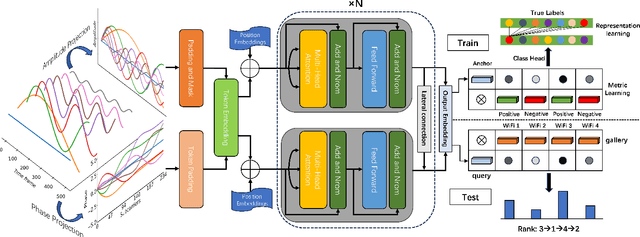
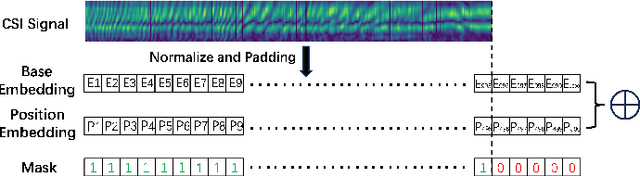
Person re-identification (ReID), as a crucial technology in the field of security, plays an important role in security detection and people counting. Current security and monitoring systems largely rely on visual information, which may infringe on personal privacy and be susceptible to interference from pedestrian appearances and clothing in certain scenarios. Meanwhile, the widespread use of routers offers new possibilities for ReID. This letter introduces a method using WiFi Channel State Information (CSI), leveraging the multipath propagation characteristics of WiFi signals as a basis for distinguishing different pedestrian features. We propose a two-stream network structure capable of processing variable-length data, which analyzes the amplitude in the time domain and the phase in the frequency domain of WiFi signals, fuses time-frequency information through continuous lateral connections, and employs advanced objective functions for representation and metric learning. Tested on a dataset collected in the real world, our method achieves 93.68% mAP and 98.13% Rank-1.
UniFL: Improve Stable Diffusion via Unified Feedback Learning
Apr 08, 2024



Diffusion models have revolutionized the field of image generation, leading to the proliferation of high-quality models and diverse downstream applications. However, despite these significant advancements, the current competitive solutions still suffer from several limitations, including inferior visual quality, a lack of aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present UniFL, a unified framework that leverages feedback learning to enhance diffusion models comprehensively. UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL. Notably, UniFL incorporates three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which optimizes inference speed. In-depth experiments and extensive user studies validate the superior performance of our proposed method in enhancing both the quality of generated models and their acceleration. For instance, UniFL surpasses ImageReward by 17% user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57% and 20% in 4-step inference. Moreover, we have verified the efficacy of our approach in downstream tasks, including Lora, ControlNet, and AnimateDiff.
Wi-Fi-based Personnel Identity Recognition: Addressing Dataset Imbalance with C-DDPMs
Apr 07, 2024



Wireless sensing technologies become increasingly prevalent due to the ubiquitous nature of wireless signals and their inherent privacy-friendly characteristics. Device-free personnel identity recognition, a prevalent application in wireless sensing, is susceptibly challenged by imbalanced channel state information (CSI) datasets. This letter proposes a novel method for CSI dataset augmentation that employs Conditional Denoising Diffusion Probabilistic Models (C-DDPMs) to generate additional samples that address class imbalance issues. The augmentation markedly improves classification accuracies on our homemade dataset, elevating all classes to above 94%.
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024



Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models
Mar 04, 2024



Recent advancement in text-to-image models (e.g., Stable Diffusion) and corresponding personalized technologies (e.g., DreamBooth and LoRA) enables individuals to generate high-quality and imaginative images. However, they often suffer from limitations when generating images with resolutions outside of their trained domain. To overcome this limitation, we present the Resolution Adapter (ResAdapter), a domain-consistent adapter designed for diffusion models to generate images with unrestricted resolutions and aspect ratios. Unlike other multi-resolution generation methods that process images of static resolution with complex post-process operations, ResAdapter directly generates images with the dynamical resolution. Especially, after learning a deep understanding of pure resolution priors, ResAdapter trained on the general dataset, generates resolution-free images with personalized diffusion models while preserving their original style domain. Comprehensive experiments demonstrate that ResAdapter with only 0.5M can process images with flexible resolutions for arbitrary diffusion models. More extended experiments demonstrate that ResAdapter is compatible with other modules (e.g., ControlNet, IP-Adapter and LCM-LoRA) for image generation across a broad range of resolutions, and can be integrated into other multi-resolution model (e.g., ElasticDiffusion) for efficiently generating higher-resolution images. Project link is https://res-adapter.github.io
AutoDiffusion: Training-Free Optimization of Time Steps and Architectures for Automated Diffusion Model Acceleration
Sep 23, 2023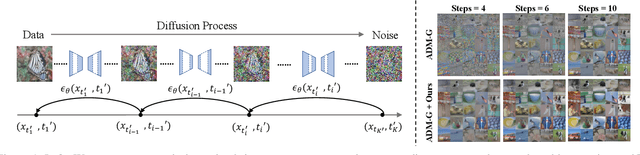

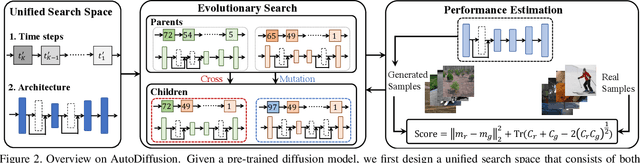
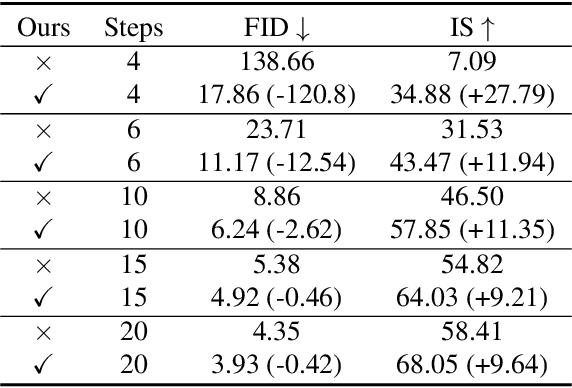
Diffusion models are emerging expressive generative models, in which a large number of time steps (inference steps) are required for a single image generation. To accelerate such tedious process, reducing steps uniformly is considered as an undisputed principle of diffusion models. We consider that such a uniform assumption is not the optimal solution in practice; i.e., we can find different optimal time steps for different models. Therefore, we propose to search the optimal time steps sequence and compressed model architecture in a unified framework to achieve effective image generation for diffusion models without any further training. Specifically, we first design a unified search space that consists of all possible time steps and various architectures. Then, a two stage evolutionary algorithm is introduced to find the optimal solution in the designed search space. To further accelerate the search process, we employ FID score between generated and real samples to estimate the performance of the sampled examples. As a result, the proposed method is (i).training-free, obtaining the optimal time steps and model architecture without any training process; (ii). orthogonal to most advanced diffusion samplers and can be integrated to gain better sample quality. (iii). generalized, where the searched time steps and architectures can be directly applied on different diffusion models with the same guidance scale. Experimental results show that our method achieves excellent performance by using only a few time steps, e.g. 17.86 FID score on ImageNet 64 $\times$ 64 with only four steps, compared to 138.66 with DDIM. The code is available at https://github.com/lilijiangg/AutoDiffusion.
UGC: Unified GAN Compression for Efficient Image-to-Image Translation
Sep 17, 2023



Recent years have witnessed the prevailing progress of Generative Adversarial Networks (GANs) in image-to-image translation. However, the success of these GAN models hinges on ponderous computational costs and labor-expensive training data. Current efficient GAN learning techniques often fall into two orthogonal aspects: i) model slimming via reduced calculation costs; ii)data/label-efficient learning with fewer training data/labels. To combine the best of both worlds, we propose a new learning paradigm, Unified GAN Compression (UGC), with a unified optimization objective to seamlessly prompt the synergy of model-efficient and label-efficient learning. UGC sets up semi-supervised-driven network architecture search and adaptive online semi-supervised distillation stages sequentially, which formulates a heterogeneous mutual learning scheme to obtain an architecture-flexible, label-efficient, and performance-excellent model.
PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models
Sep 11, 2023



Personalized text-to-image generation has emerged as a powerful and sought-after tool, empowering users to create customized images based on their specific concepts and prompts. However, existing approaches to personalization encounter multiple challenges, including long tuning times, large storage requirements, the necessity for multiple input images per identity, and limitations in preserving identity and editability. To address these obstacles, we present PhotoVerse, an innovative methodology that incorporates a dual-branch conditioning mechanism in both text and image domains, providing effective control over the image generation process. Furthermore, we introduce facial identity loss as a novel component to enhance the preservation of identity during training. Remarkably, our proposed PhotoVerse eliminates the need for test time tuning and relies solely on a single facial photo of the target identity, significantly reducing the resource cost associated with image generation. After a single training phase, our approach enables generating high-quality images within only a few seconds. Moreover, our method can produce diverse images that encompass various scenes and styles. The extensive evaluation demonstrates the superior performance of our approach, which achieves the dual objectives of preserving identity and facilitating editability. Project page: https://photoverse2d.github.io/