 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Distribution Matching for Diffusion Distillation Towards Efficient Image and Video Synthesis
Jul 24, 2025
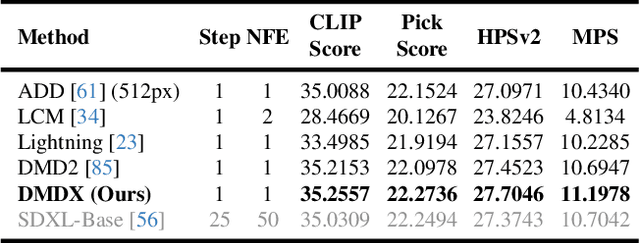
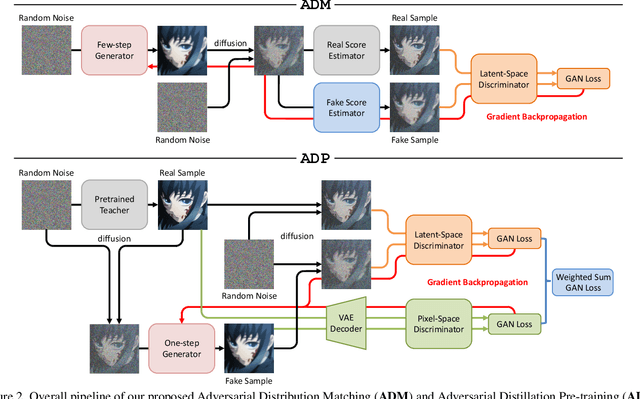
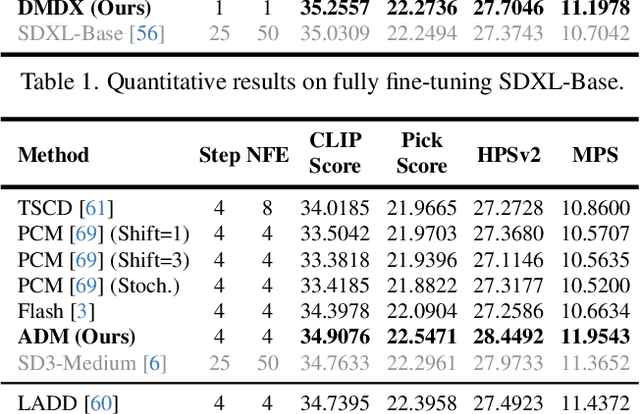
Distribution Matching Distillation (DMD) is a promising score distillation technique that compresses pre-trained teacher diffusion models into efficient one-step or multi-step student generators. Nevertheless, its reliance on the reverse Kullback-Leibler (KL) divergence minimization potentially induces mode collapse (or mode-seeking) in certain applications. To circumvent this inherent drawback, we propose Adversarial Distribution Matching (ADM), a novel framework that leverages diffusion-based discriminators to align the latent predictions between real and fake score estimators for score distillation in an adversarial manner. In the context of extremely challenging one-step distillation, we further improve the pre-trained generator by adversarial distillation with hybrid discriminators in both latent and pixel spaces. Different from the mean squared error used in DMD2 pre-training, our method incorporates the distributional loss on ODE pairs collected from the teacher model, and thus providing a better initialization for score distillation fine-tuning in the next stage. By combining the adversarial distillation pre-training with ADM fine-tuning into a unified pipeline termed DMDX, our proposed method achieves superior one-step performance on SDXL compared to DMD2 while consuming less GPU time. Additional experiments that apply multi-step ADM distillation on SD3-Medium, SD3.5-Large, and CogVideoX set a new benchmark towards efficient image and video synthesis.
Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis
Apr 21, 2024



Recently, a series of diffusion-aware distillation algorithms have emerged to alleviate the computational overhead associated with the multi-step inference process of Diffusion Models (DMs). Current distillation techniques often dichotomize into two distinct aspects: i) ODE Trajectory Preservation; and ii) ODE Trajectory Reformulation. However, these approaches suffer from severe performance degradation or domain shifts. To address these limitations, we propose Hyper-SD, a novel framework that synergistically amalgamates the advantages of ODE Trajectory Preservation and Reformulation, while maintaining near-lossless performance during step compression. Firstly, we introduce Trajectory Segmented Consistency Distillation to progressively perform consistent distillation within pre-defined time-step segments, which facilitates the preservation of the original ODE trajectory from a higher-order perspective. Secondly, we incorporate human feedback learning to boost the performance of the model in a low-step regime and mitigate the performance loss incurred by the distillation process. Thirdly, we integrate score distillation to further improve the low-step generation capability of the model and offer the first attempt to leverage a unified LoRA to support the inference process at all steps. Extensive experiments and user studies demonstrate that Hyper-SD achieves SOTA performance from 1 to 8 inference steps for both SDXL and SD1.5. For example, Hyper-SDXL surpasses SDXL-Lightning by +0.68 in CLIP Score and +0.51 in Aes Score in the 1-step inference.
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024



Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis
Feb 28, 2024
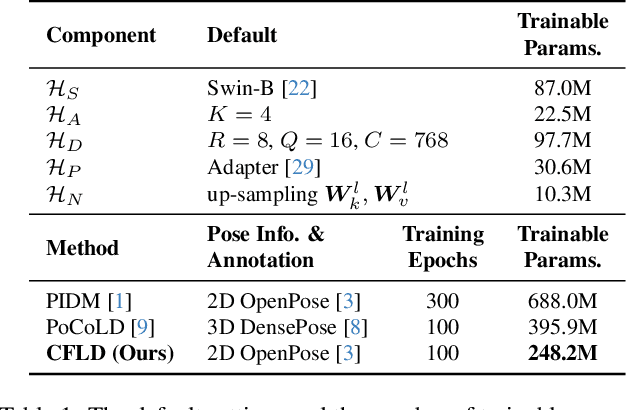
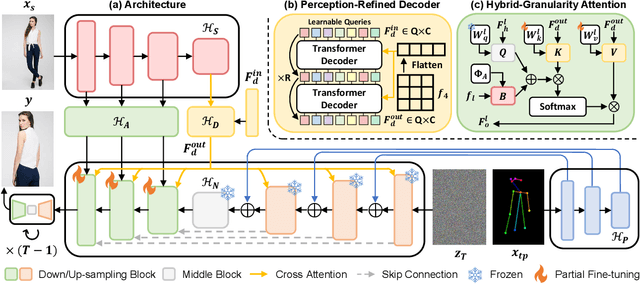
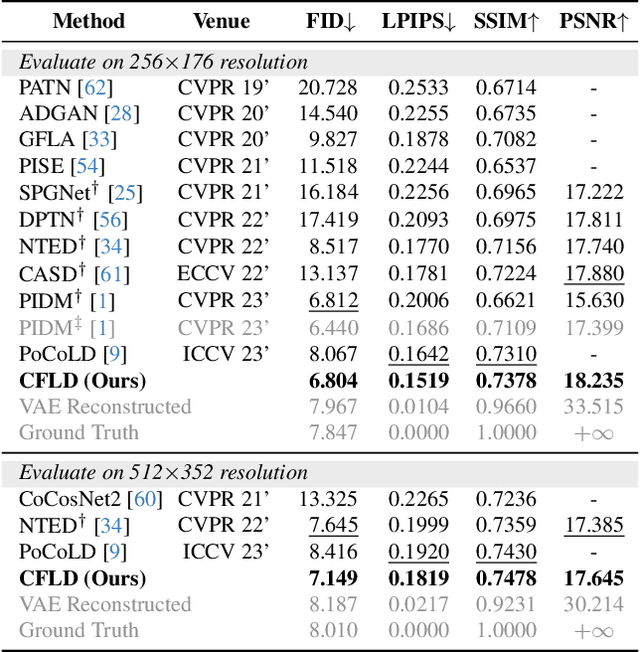
Diffusion model is a promising approach to image generation and has been employed for Pose-Guided Person Image Synthesis (PGPIS) with competitive performance. While existing methods simply align the person appearance to the target pose, they are prone to overfitting due to the lack of a high-level semantic understanding on the source person image. In this paper, we propose a novel Coarse-to-Fine Latent Diffusion (CFLD) method for PGPIS. In the absence of image-caption pairs and textual prompts, we develop a novel training paradigm purely based on images to control the generation process of the pre-trained text-to-image diffusion model. A perception-refined decoder is designed to progressively refine a set of learnable queries and extract semantic understanding of person images as a coarse-grained prompt. This allows for the decoupling of fine-grained appearance and pose information controls at different stages, and thus circumventing the potential overfitting problem. To generate more realistic texture details, a hybrid-granularity attention module is proposed to encode multi-scale fine-grained appearance features as bias terms to augment the coarse-grained prompt. Both quantitative and qualitative experimental results on the DeepFashion benchmark demonstrate the superiority of our method over the state of the arts for PGPIS. Code is available at https://github.com/YanzuoLu/CFLD.
MLNet: Mutual Learning Network with Neighborhood Invariance for Universal Domain Adaptation
Dec 21, 2023

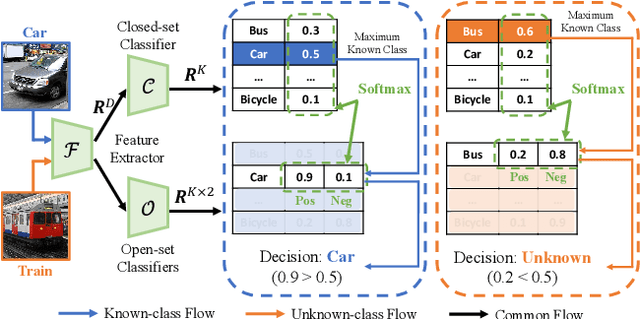

Universal domain adaptation (UniDA) is a practical but challenging problem, in which information about the relation between the source and the target domains is not given for knowledge transfer. Existing UniDA methods may suffer from the problems of overlooking intra-domain variations in the target domain and difficulty in separating between the similar known and unknown class. To address these issues, we propose a novel Mutual Learning Network (MLNet) with neighborhood invariance for UniDA. In our method, confidence-guided invariant feature learning with self-adaptive neighbor selection is designed to reduce the intra-domain variations for more generalizable feature representation. By using the cross-domain mixup scheme for better unknown-class identification, the proposed method compensates for the misidentified known-class errors by mutual learning between the closed-set and open-set classifiers. Extensive experiments on three publicly available benchmarks demonstrate that our method achieves the best results compared to the state-of-the-arts in most cases and significantly outperforms the baseline across all the four settings in UniDA. Code is available at https://github.com/YanzuoLu/MLNet.