 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis
Feb 28, 2024
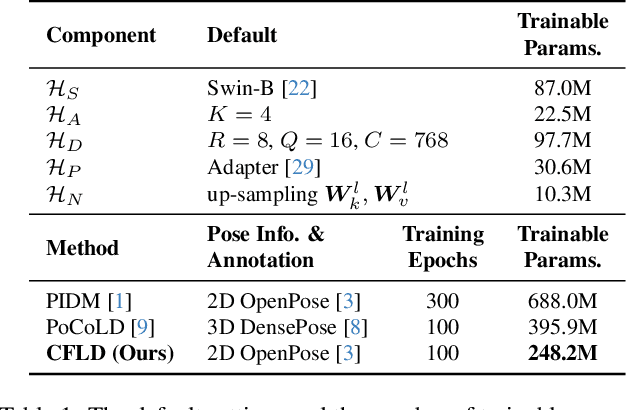
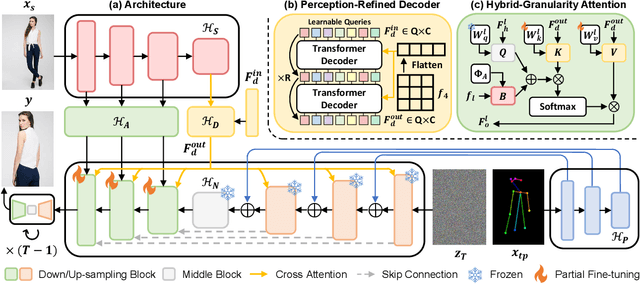
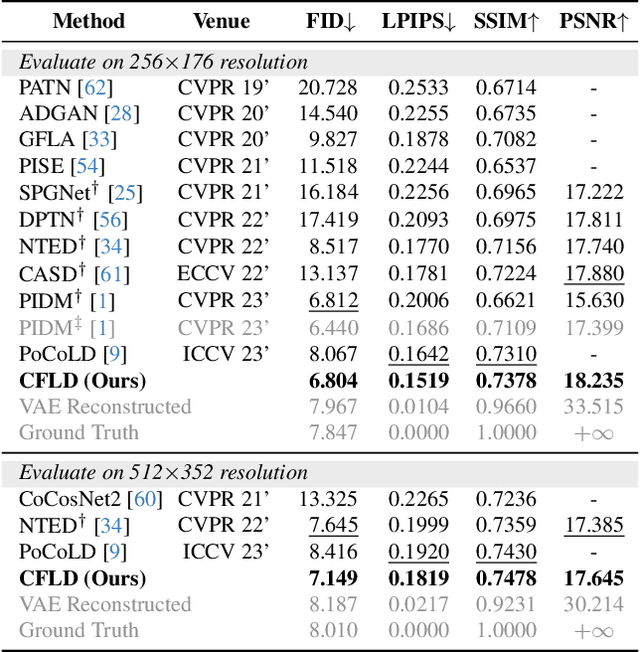
Diffusion model is a promising approach to image generation and has been employed for Pose-Guided Person Image Synthesis (PGPIS) with competitive performance. While existing methods simply align the person appearance to the target pose, they are prone to overfitting due to the lack of a high-level semantic understanding on the source person image. In this paper, we propose a novel Coarse-to-Fine Latent Diffusion (CFLD) method for PGPIS. In the absence of image-caption pairs and textual prompts, we develop a novel training paradigm purely based on images to control the generation process of the pre-trained text-to-image diffusion model. A perception-refined decoder is designed to progressively refine a set of learnable queries and extract semantic understanding of person images as a coarse-grained prompt. This allows for the decoupling of fine-grained appearance and pose information controls at different stages, and thus circumventing the potential overfitting problem. To generate more realistic texture details, a hybrid-granularity attention module is proposed to encode multi-scale fine-grained appearance features as bias terms to augment the coarse-grained prompt. Both quantitative and qualitative experimental results on the DeepFashion benchmark demonstrate the superiority of our method over the state of the arts for PGPIS. Code is available at https://github.com/YanzuoLu/CFLD.
MLNet: Mutual Learning Network with Neighborhood Invariance for Universal Domain Adaptation
Dec 21, 2023

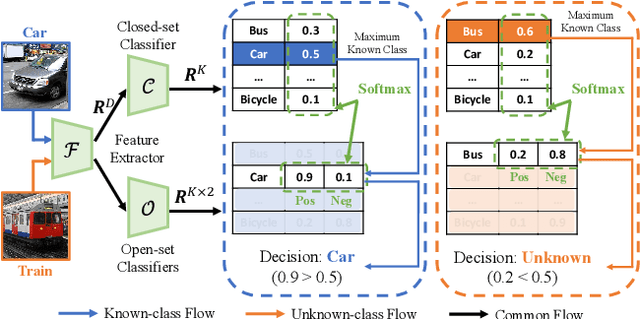

Universal domain adaptation (UniDA) is a practical but challenging problem, in which information about the relation between the source and the target domains is not given for knowledge transfer. Existing UniDA methods may suffer from the problems of overlooking intra-domain variations in the target domain and difficulty in separating between the similar known and unknown class. To address these issues, we propose a novel Mutual Learning Network (MLNet) with neighborhood invariance for UniDA. In our method, confidence-guided invariant feature learning with self-adaptive neighbor selection is designed to reduce the intra-domain variations for more generalizable feature representation. By using the cross-domain mixup scheme for better unknown-class identification, the proposed method compensates for the misidentified known-class errors by mutual learning between the closed-set and open-set classifiers. Extensive experiments on three publicly available benchmarks demonstrate that our method achieves the best results compared to the state-of-the-arts in most cases and significantly outperforms the baseline across all the four settings in UniDA. Code is available at https://github.com/YanzuoLu/MLNet.
Dynamic Label Graph Matching for Unsupervised Video Re-Identification
Sep 27, 2017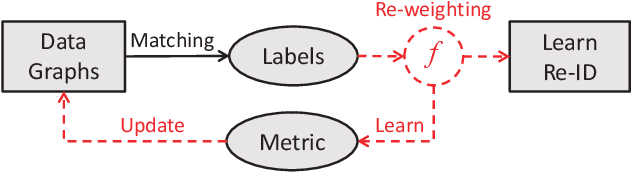

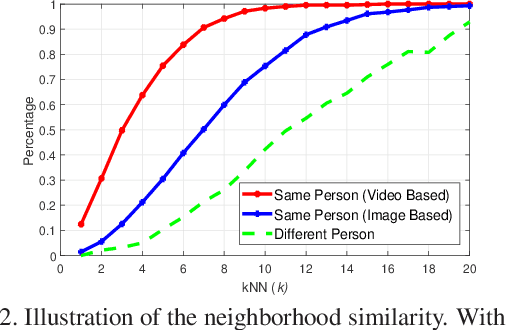
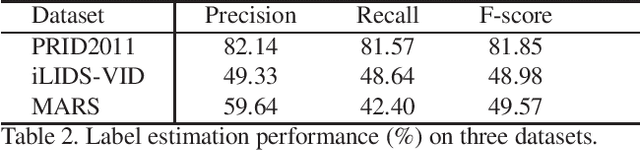
Label estimation is an important component in an unsupervised person re-identification (re-ID) system. This paper focuses on cross-camera label estimation, which can be subsequently used in feature learning to learn robust re-ID models. Specifically, we propose to construct a graph for samples in each camera, and then graph matching scheme is introduced for cross-camera labeling association. While labels directly output from existing graph matching methods may be noisy and inaccurate due to significant cross-camera variations, this paper proposes a dynamic graph matching (DGM) method. DGM iteratively updates the image graph and the label estimation process by learning a better feature space with intermediate estimated labels. DGM is advantageous in two aspects: 1) the accuracy of estimated labels is improved significantly with the iterations; 2) DGM is robust to noisy initial training data. Extensive experiments conducted on three benchmarks including the large-scale MARS dataset show that DGM yields competitive performance to fully supervised baselines, and outperforms competing unsupervised learning methods.
Temporal Matrix Completion with Locally Linear Latent Factors for Medical Applications
Oct 31, 2016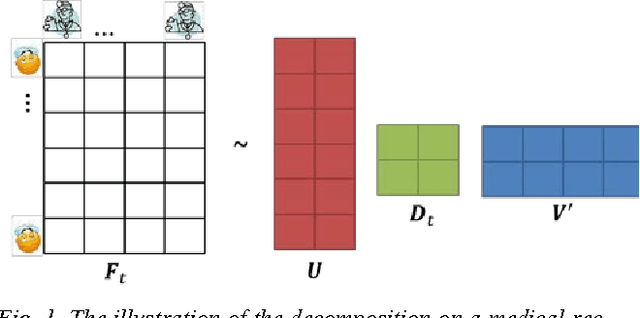
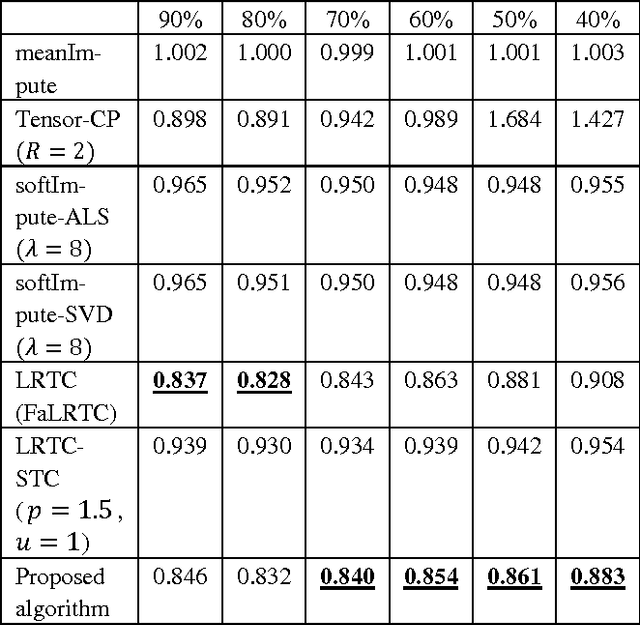
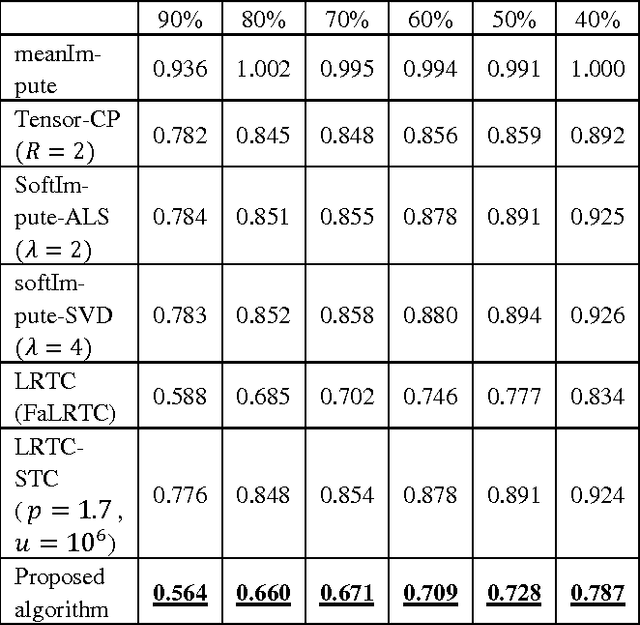
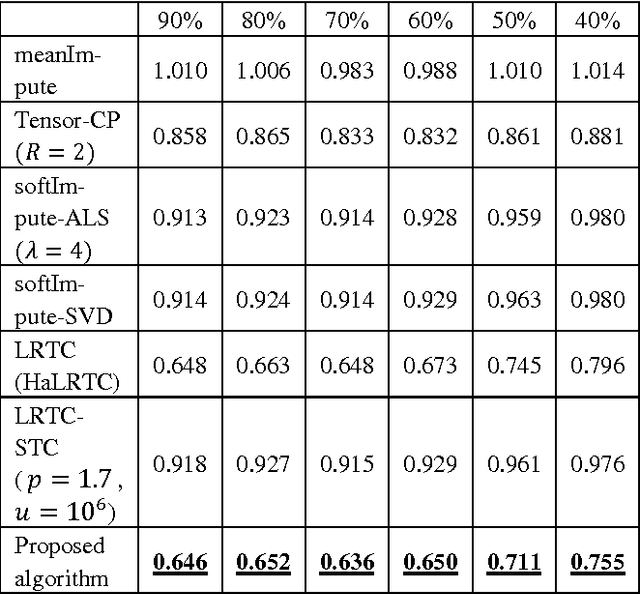
Regular medical records are useful for medical practitioners to analyze and monitor patient health status especially for those with chronic disease, but such records are usually incomplete due to unpunctuality and absence of patients. In order to resolve the missing data problem over time, tensor-based model is suggested for missing data imputation in recent papers because this approach makes use of low rank tensor assumption for highly correlated data. However, when the time intervals between records are long, the data correlation is not high along temporal direction and such assumption is not valid. To address this problem, we propose to decompose a matrix with missing data into its latent factors. Then, the locally linear constraint is imposed on these factors for matrix completion in this paper. By using a publicly available dataset and two medical datasets collected from hospital, experimental results show that the proposed algorithm achieves the best performance by comparing with the existing methods.
Deformable Distributed Multiple Detector Fusion for Multi-Person Tracking
Dec 18, 2015



This paper addresses fully automated multi-person tracking in complex environments with challenging occlusion and extensive pose variations. Our solution combines multiple detectors for a set of different regions of interest (e.g., full-body and head) for multi-person tracking. The use of multiple detectors leads to fewer miss detections as it is able to exploit the complementary strengths of the individual detectors. While the number of false positives may increase with the increased number of bounding boxes detected from multiple detectors, we propose to group the detection outputs by bounding box location and depth information. For robustness to significant pose variations, deformable spatial relationship between detectors are learnt in our multi-person tracking system. On RGBD data from a live Intensive Care Unit (ICU), we show that the proposed method significantly improves multi-person tracking performance over state-of-the-art methods.