 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Selection and Augmentation for Few Examples Code Generation in Large Language Model and its Application in Robotics Control
Mar 11, 2024

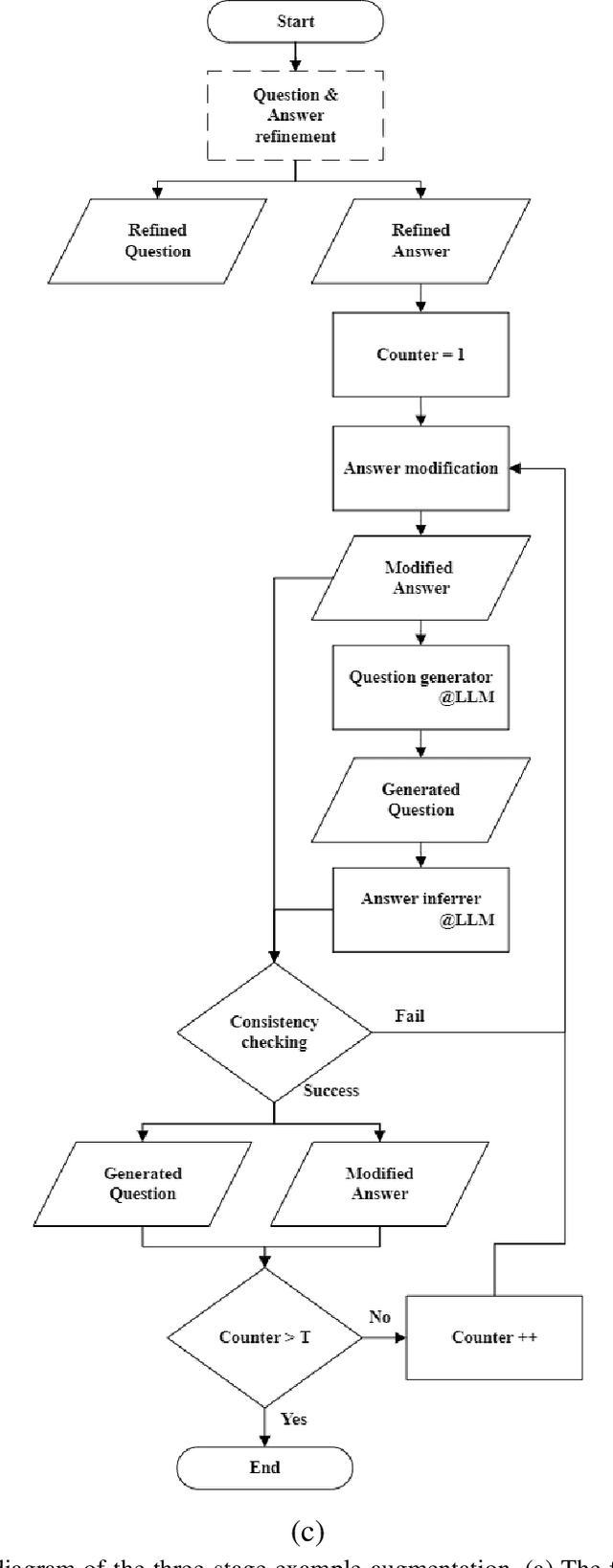
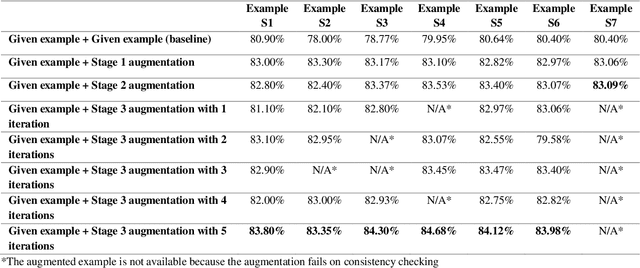
Few-shot prompting and step-by-step reasoning have enhanced the capabilities of Large Language Models (LLMs) in tackling complex tasks including code generation. In this paper, we introduce a prompt selection and augmentation algorithm aimed at improving mathematical reasoning and robot arm operations. Our approach incorporates a multi-stage example augmentation scheme combined with an example selection scheme. This algorithm improves LLM performance by selecting a set of examples that increase diversity, minimize redundancy, and increase relevance to the question. When combined with the Program-of-Thought prompting, our algorithm demonstrates an improvement in performance on the GSM8K and SVAMP benchmarks, with increases of 0.3% and 1.1% respectively. Furthermore, in simulated tabletop environments, our algorithm surpasses the Code-as-Policies approach by achieving a 3.4% increase in successful task completions and a decrease of over 70% in the number of examples used. Its ability to discard examples that contribute little to solving the problem reduces the inferencing time of an LLM-powered robotics system. This algorithm also offers important benefits for industrial process automation by streamlining the development and deployment process, reducing manual programming effort, and enhancing code reusability.
A Study on Wrist Identification for Forensic Investigation
Oct 08, 2019
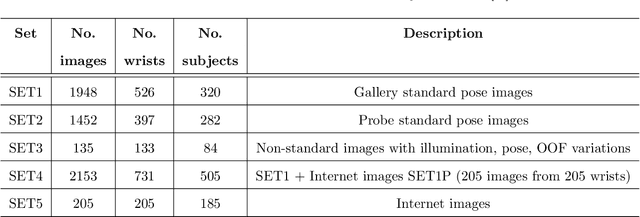

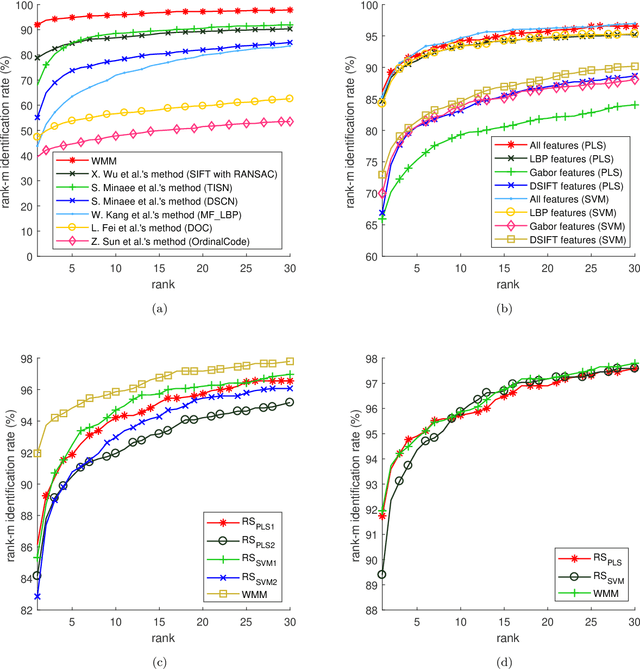
Criminal and victim identification based on crime scene images is an important part of forensic investigation. Criminals usually avoid identification by covering their faces and tattoos in the evidence images, which are taken in uncontrolled environments. Existing identification methods, which make use of biometric traits, such as vein, skin mark, height, skin color, weight, race, etc., are considered for solving this problem. The soft biometric traits, including skin color, gender, height, weight and race, provide useful information but not distinctive enough. Veins and skin marks are limited to high resolution images and some body sites may neither have enough skin marks nor clear veins. Terrorists and rioters tend to expose their wrists in a gesture of triumph, greeting or salute, while paedophiles usually show them when touching victims. However, wrists were neglected by the biometric community for forensic applications. In this paper, a wrist identification algorithm, which includes skin segmentation, key point localization, image to template alignment, large feature set extraction, and classification, is proposed. The proposed algorithm is evaluated on NTU-Wrist-Image-Database-v1, which consists of 3945 images from 731 different wrists, including 205 pairs of wrist images collected from the Internet, taken under uneven illuminations with different poses and resolutions. The experimental results show that wrist is a useful clue for criminal and victim identification. Keywords: biometrics, criminal and victim identification, forensics, wrist.
Temporal Matrix Completion with Locally Linear Latent Factors for Medical Applications
Oct 31, 2016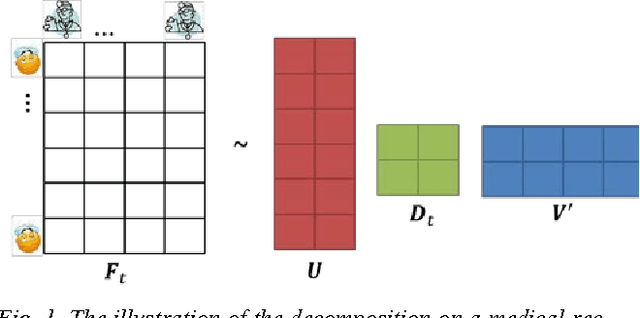
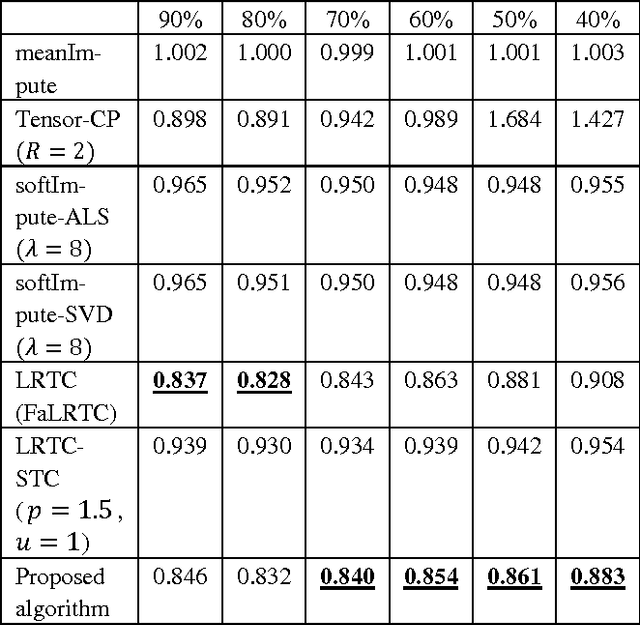
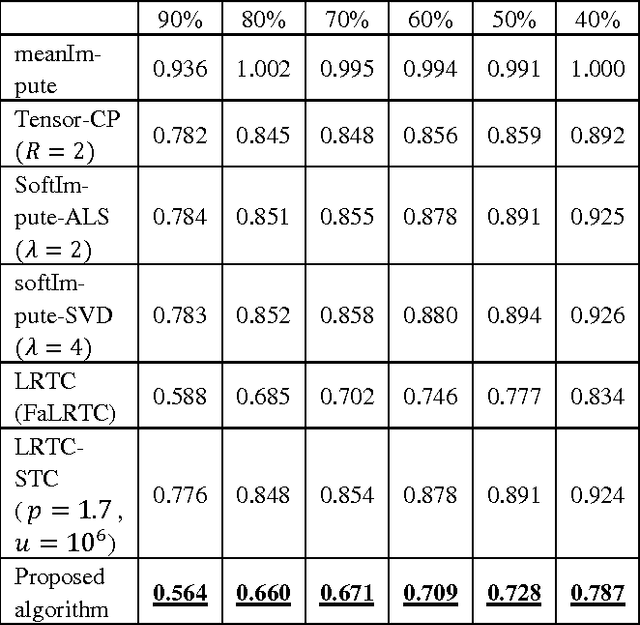
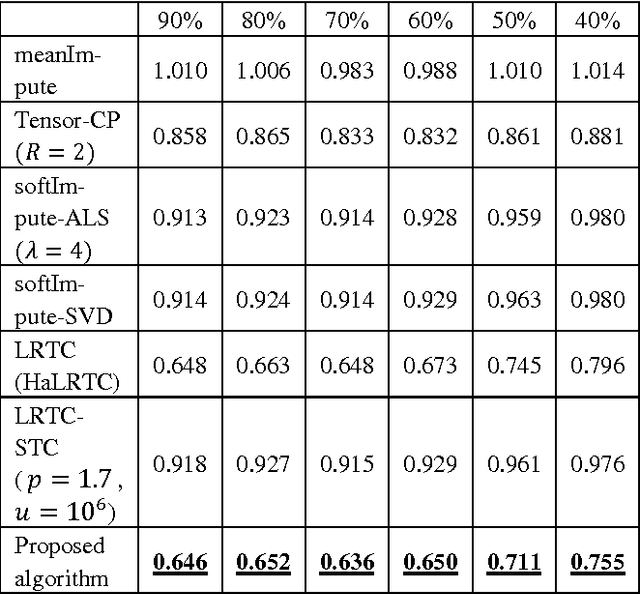
Regular medical records are useful for medical practitioners to analyze and monitor patient health status especially for those with chronic disease, but such records are usually incomplete due to unpunctuality and absence of patients. In order to resolve the missing data problem over time, tensor-based model is suggested for missing data imputation in recent papers because this approach makes use of low rank tensor assumption for highly correlated data. However, when the time intervals between records are long, the data correlation is not high along temporal direction and such assumption is not valid. To address this problem, we propose to decompose a matrix with missing data into its latent factors. Then, the locally linear constraint is imposed on these factors for matrix completion in this paper. By using a publicly available dataset and two medical datasets collected from hospital, experimental results show that the proposed algorithm achieves the best performance by comparing with the existing methods.