 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Selection and Augmentation for Few Examples Code Generation in Large Language Model and its Application in Robotics Control
Mar 11, 2024

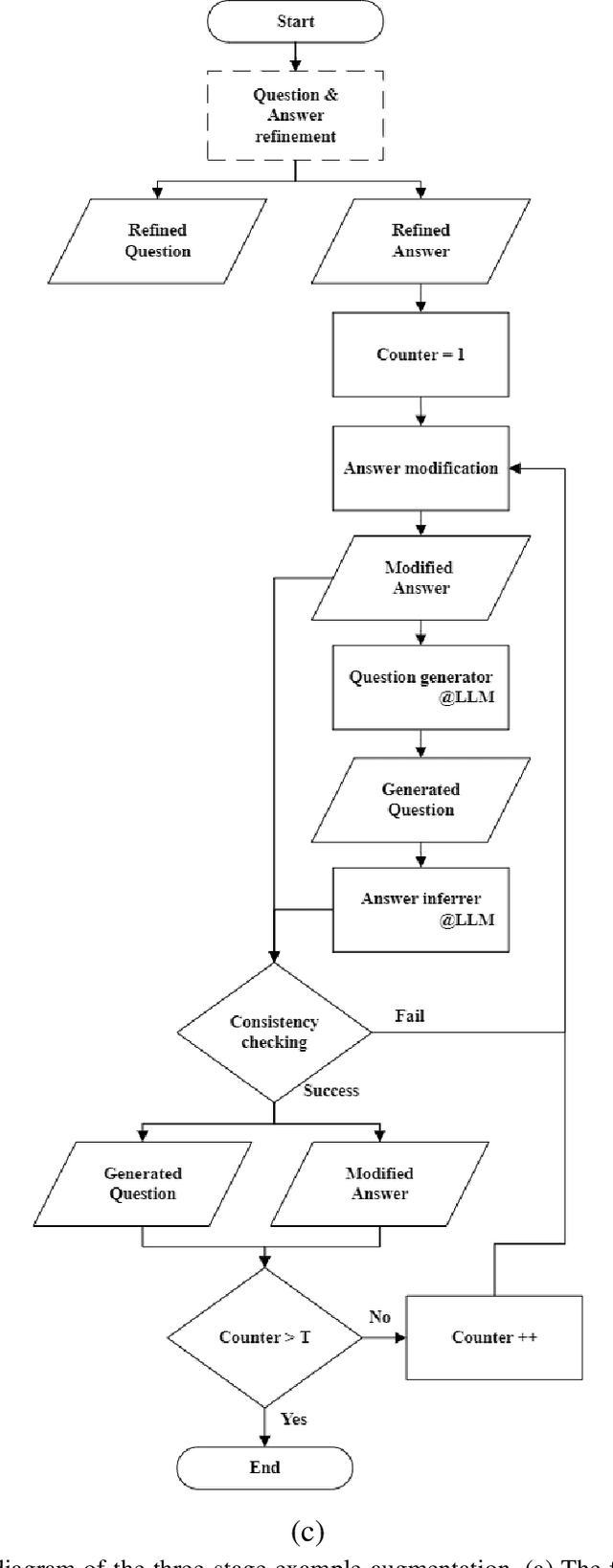
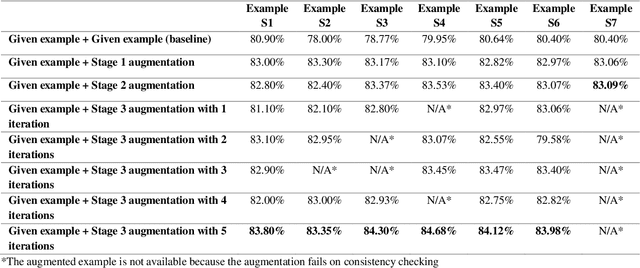
Few-shot prompting and step-by-step reasoning have enhanced the capabilities of Large Language Models (LLMs) in tackling complex tasks including code generation. In this paper, we introduce a prompt selection and augmentation algorithm aimed at improving mathematical reasoning and robot arm operations. Our approach incorporates a multi-stage example augmentation scheme combined with an example selection scheme. This algorithm improves LLM performance by selecting a set of examples that increase diversity, minimize redundancy, and increase relevance to the question. When combined with the Program-of-Thought prompting, our algorithm demonstrates an improvement in performance on the GSM8K and SVAMP benchmarks, with increases of 0.3% and 1.1% respectively. Furthermore, in simulated tabletop environments, our algorithm surpasses the Code-as-Policies approach by achieving a 3.4% increase in successful task completions and a decrease of over 70% in the number of examples used. Its ability to discard examples that contribute little to solving the problem reduces the inferencing time of an LLM-powered robotics system. This algorithm also offers important benefits for industrial process automation by streamlining the development and deployment process, reducing manual programming effort, and enhancing code reusability.