 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Schedule Optimization for Fast and Robust Diffusion Model Sampling
Nov 12, 2025


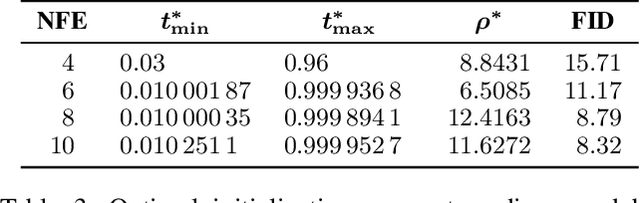
Diffusion probabilistic models have set a new standard for generative fidelity but are hindered by a slow iterative sampling process. A powerful training-free strategy to accelerate this process is Schedule Optimization, which aims to find an optimal distribution of timesteps for a fixed and small Number of Function Evaluations (NFE) to maximize sample quality. To this end, a successful schedule optimization method must adhere to four core principles: effectiveness, adaptivity, practical robustness, and computational efficiency. However, existing paradigms struggle to satisfy these principles simultaneously, motivating the need for a more advanced solution. To overcome these limitations, we propose the Hierarchical-Schedule-Optimizer (HSO), a novel and efficient bi-level optimization framework. HSO reframes the search for a globally optimal schedule into a more tractable problem by iteratively alternating between two synergistic levels: an upper-level global search for an optimal initialization strategy and a lower-level local optimization for schedule refinement. This process is guided by two key innovations: the Midpoint Error Proxy (MEP), a solver-agnostic and numerically stable objective for effective local optimization, and the Spacing-Penalized Fitness (SPF) function, which ensures practical robustness by penalizing pathologically close timesteps. Extensive experiments show that HSO sets a new state-of-the-art for training-free sampling in the extremely low-NFE regime. For instance, with an NFE of just 5, HSO achieves a remarkable FID of 11.94 on LAION-Aesthetics with Stable Diffusion v2.1. Crucially, this level of performance is attained not through costly retraining, but with a one-time optimization cost of less than 8 seconds, presenting a highly practical and efficient paradigm for diffusion model acceleration.
Enhancing Modality Representation and Alignment for Multimodal Cold-start Active Learning
Dec 12, 2024Training multimodal models requires a large amount of labeled data. Active learning (AL) aim to reduce labeling costs. Most AL methods employ warm-start approaches, which rely on sufficient labeled data to train a well-calibrated model that can assess the uncertainty and diversity of unlabeled data. However, when assembling a dataset, labeled data are often scarce initially, leading to a cold-start problem. Additionally, most AL methods seldom address multimodal data, highlighting a research gap in this field. Our research addresses these issues by developing a two-stage method for Multi-Modal Cold-Start Active Learning (MMCSAL). Firstly, we observe the modality gap, a significant distance between the centroids of representations from different modalities, when only using cross-modal pairing information as self-supervision signals. This modality gap affects data selection process, as we calculate both uni-modal and cross-modal distances. To address this, we introduce uni-modal prototypes to bridge the modality gap. Secondly, conventional AL methods often falter in multimodal scenarios where alignment between modalities is overlooked. Therefore, we propose enhancing cross-modal alignment through regularization, thereby improving the quality of selected multimodal data pairs in AL. Finally, our experiments demonstrate MMCSAL's efficacy in selecting multimodal data pairs across three multimodal datasets.
Empowering Computing and Networks Convergence System with Distributed Cooperative Routing
Feb 04, 2024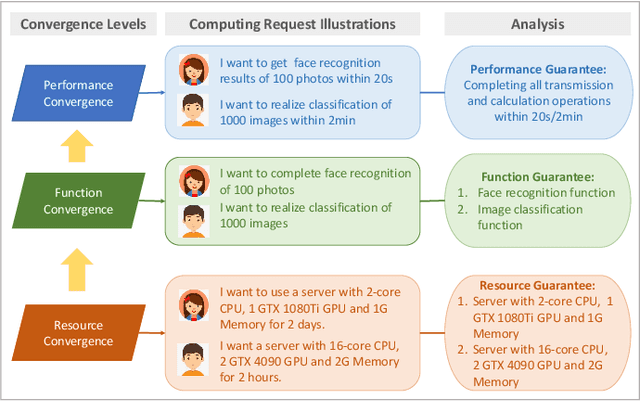
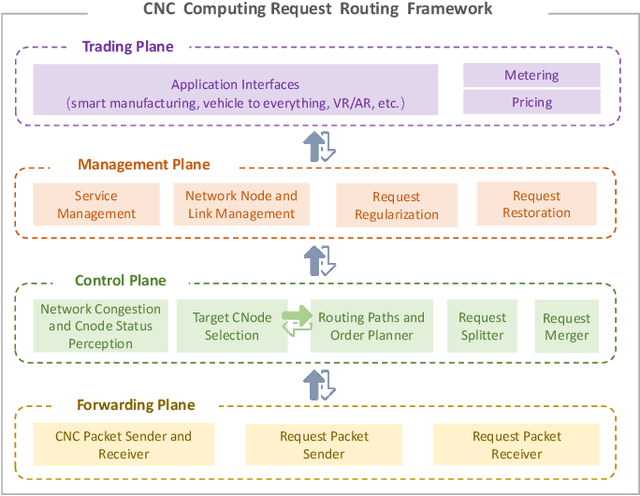
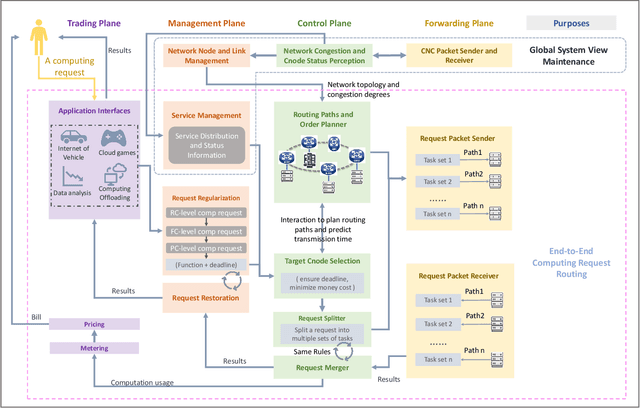
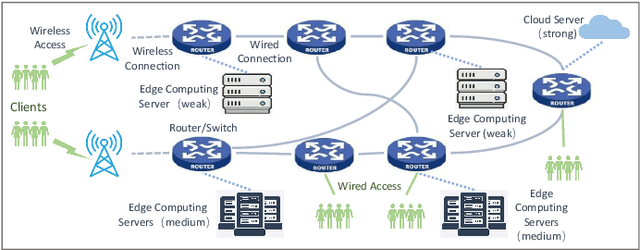
The emergence of intelligent applications and recent advances in the fields of computing and networks are driving the development of computing and networks convergence (CNC) system. However, existing researches failed to achieve comprehensive scheduling optimization of computing and network resources. This shortfall results in some requirements of computing requests unable to be guaranteed in an end-to-end service pattern, negatively impacting the development of CNC systems. In this article, we propose a distributed cooperative routing framework for the CNC system to ensure the deadline requirements and minimize the computation cost of requests. The framework includes trading plane, management plane, control plane and forwarding plane. The cross-plane cooperative end-to-end routing schemes consider both computation efficiency of heterogeneous servers and the network congestion degrees while making routing plan, thereby determining where to execute requests and corresponding routing paths. Simulations results substantiates the performance of our routing schemes in scheduling computing requests in the CNC system.
MLNet: Mutual Learning Network with Neighborhood Invariance for Universal Domain Adaptation
Dec 21, 2023

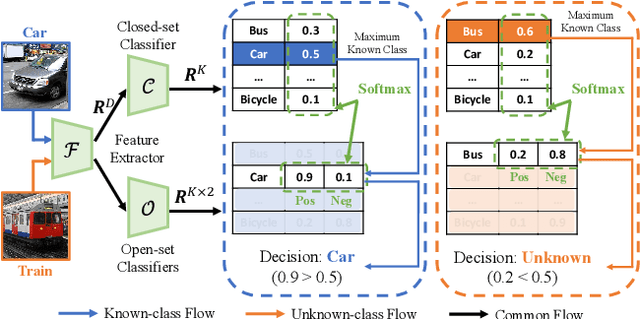

Universal domain adaptation (UniDA) is a practical but challenging problem, in which information about the relation between the source and the target domains is not given for knowledge transfer. Existing UniDA methods may suffer from the problems of overlooking intra-domain variations in the target domain and difficulty in separating between the similar known and unknown class. To address these issues, we propose a novel Mutual Learning Network (MLNet) with neighborhood invariance for UniDA. In our method, confidence-guided invariant feature learning with self-adaptive neighbor selection is designed to reduce the intra-domain variations for more generalizable feature representation. By using the cross-domain mixup scheme for better unknown-class identification, the proposed method compensates for the misidentified known-class errors by mutual learning between the closed-set and open-set classifiers. Extensive experiments on three publicly available benchmarks demonstrate that our method achieves the best results compared to the state-of-the-arts in most cases and significantly outperforms the baseline across all the four settings in UniDA. Code is available at https://github.com/YanzuoLu/MLNet.
Towards Balanced Active Learning for Multimodal Classification
Jun 14, 2023



Training multimodal networks requires a vast amount of data due to their larger parameter space compared to unimodal networks. Active learning is a widely used technique for reducing data annotation costs by selecting only those samples that could contribute to improving model performance. However, current active learning strategies are mostly designed for unimodal tasks, and when applied to multimodal data, they often result in biased sample selection from the dominant modality. This unfairness hinders balanced multimodal learning, which is crucial for achieving optimal performance. To address this issue, we propose three guidelines for designing a more balanced multimodal active learning strategy. Following these guidelines, a novel approach is proposed to achieve more fair data selection by modulating the gradient embedding with the dominance degree among modalities. Our studies demonstrate that the proposed method achieves more balanced multimodal learning by avoiding greedy sample selection from the dominant modality. Our approach outperforms existing active learning strategies on a variety of multimodal classification tasks. Overall, our work highlights the importance of balancing sample selection in multimodal active learning and provides a practical solution for achieving more balanced active learning for multimodal classification.
UniS-MMC: Multimodal Classification via Unimodality-supervised Multimodal Contrastive Learning
May 16, 2023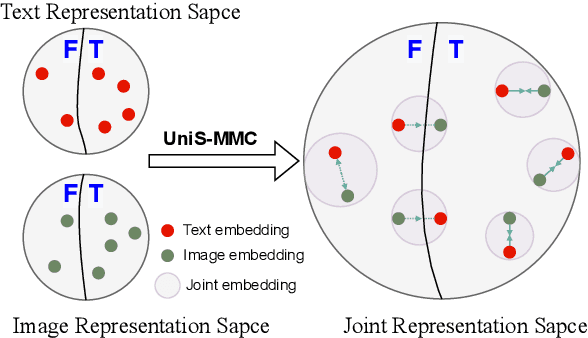
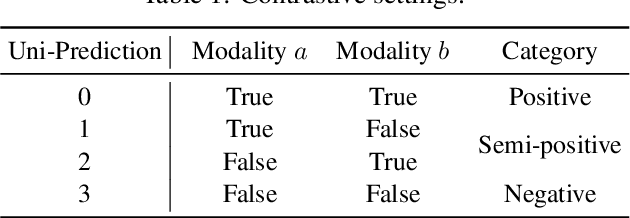
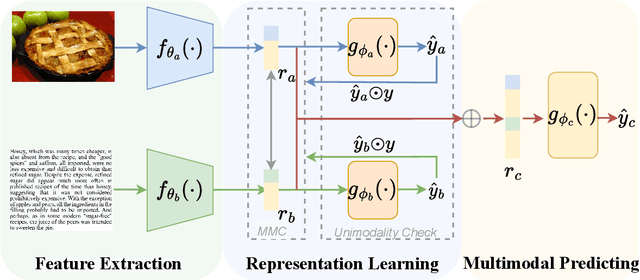
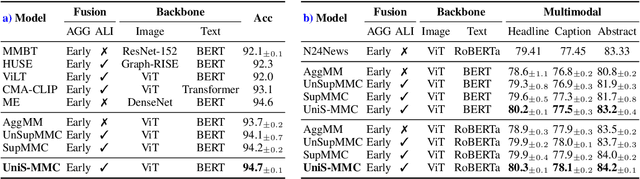
Multimodal learning aims to imitate human beings to acquire complementary information from multiple modalities for various downstream tasks. However, traditional aggregation-based multimodal fusion methods ignore the inter-modality relationship, treat each modality equally, suffer sensor noise, and thus reduce multimodal learning performance. In this work, we propose a novel multimodal contrastive method to explore more reliable multimodal representations under the weak supervision of unimodal predicting. Specifically, we first capture task-related unimodal representations and the unimodal predictions from the introduced unimodal predicting task. Then the unimodal representations are aligned with the more effective one by the designed multimodal contrastive method under the supervision of the unimodal predictions. Experimental results with fused features on two image-text classification benchmarks UPMC-Food-101 and N24News show that our proposed Unimodality-Supervised MultiModal Contrastive UniS-MMC learning method outperforms current state-of-the-art multimodal methods. The detailed ablation study and analysis further demonstrate the advantage of our proposed method.
Realtime Robust Malicious Traffic Detection via Frequency Domain Analysis
Jun 28, 2021



Machine learning (ML) based malicious traffic detection is an emerging security paradigm, particularly for zero-day attack detection, which is complementary to existing rule based detection. However, the existing ML based detection has low detection accuracy and low throughput incurred by inefficient traffic features extraction. Thus, they cannot detect attacks in realtime especially in high throughput networks. Particularly, these detection systems similar to the existing rule based detection can be easily evaded by sophisticated attacks. To this end, we propose Whisper, a realtime ML based malicious traffic detection system that achieves both high accuracy and high throughput by utilizing frequency domain features. It utilizes sequential features represented by the frequency domain features to achieve bounded information loss, which ensures high detection accuracy, and meanwhile constrains the scale of features to achieve high detection throughput. Particularly, attackers cannot easily interfere with the frequency domain features and thus Whisper is robust against various evasion attacks. Our experiments with 42 types of attacks demonstrate that, compared with the state-of-theart systems, Whisper can accurately detect various sophisticated and stealthy attacks, achieving at most 18.36% improvement, while achieving two orders of magnitude throughput. Even under various evasion attacks, Whisper is still able to maintain around 90% detection accuracy.
A Serverless Cloud-Fog Platform for DNN-Based Video Analytics with Incremental Learning
Feb 05, 2021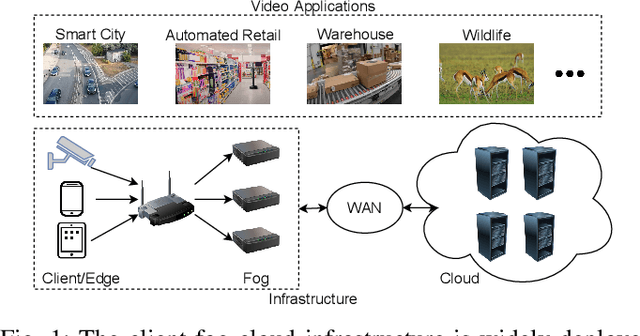
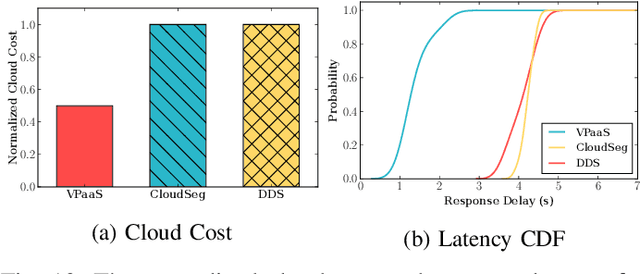
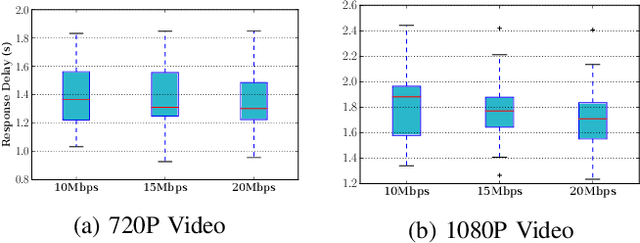
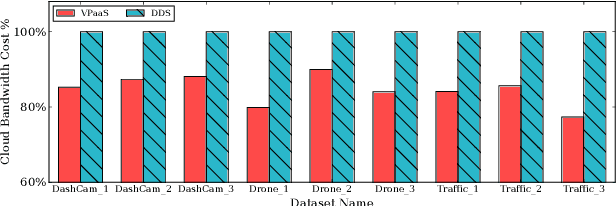
DNN-based video analytics have empowered many new applications (e.g., automated retail). Meanwhile, the proliferation of fog devices provides developers with more design options to improve performance and save cost. To the best of our knowledge, this paper presents the first serverless system that takes full advantage of the client-fog-cloud synergy to better serve the DNN-based video analytics. Specifically, the system aims to achieve two goals: 1) Provide the optimal analytics results under the constraints of lower bandwidth usage and shorter round-trip time (RTT) by judiciously managing the computational and bandwidth resources deployed in the client, fog, and cloud environment. 2) Free developers from tedious administration and operation tasks, including DNN deployment, cloud and fog's resource management. To this end, we implement a holistic cloud-fog system referred to as VPaaS (Video-Platform-as-a-Service). VPaaS adopts serverless computing to enable developers to build a video analytics pipeline by simply programming a set of functions (e.g., model inference), which are then orchestrated to process videos through carefully designed modules. To save bandwidth and reduce RTT, VPaaS provides a new video streaming protocol that only sends low-quality video to the cloud. The state-of-the-art (SOTA) DNNs deployed at the cloud can identify regions of video frames that need further processing at the fog ends. At the fog ends, misidentified labels in these regions can be corrected using a light-weight DNN model. To address the data drift issues, we incorporate limited human feedback into the system to verify the results and adopt incremental learning to improve our system continuously. The evaluation demonstrates that VPaaS is superior to several SOTA systems: it maintains high accuracy while reducing bandwidth usage by up to 21%, RTT by up to 62.5%, and cloud monetary cost by up to 50%.
Robust Attacks on Deep Learning Face Recognition in the Physical World
Nov 27, 2020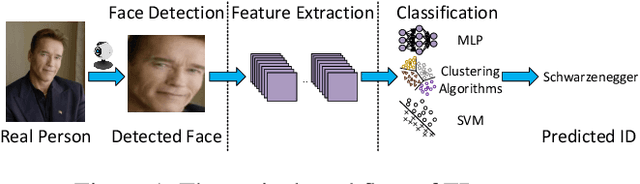



Deep neural networks (DNNs) have been increasingly used in face recognition (FR) systems. Recent studies, however, show that DNNs are vulnerable to adversarial examples, which can potentially mislead the FR systems using DNNs in the physical world. Existing attacks on these systems either generate perturbations working merely in the digital world, or rely on customized equipments to generate perturbations and are not robust in varying physical environments. In this paper, we propose FaceAdv, a physical-world attack that crafts adversarial stickers to deceive FR systems. It mainly consists of a sticker generator and a transformer, where the former can craft several stickers with different shapes and the latter transformer aims to digitally attach stickers to human faces and provide feedbacks to the generator to improve the effectiveness of stickers. We conduct extensive experiments to evaluate the effectiveness of FaceAdv on attacking 3 typical FR systems (i.e., ArcFace, CosFace and FaceNet). The results show that compared with a state-of-the-art attack, FaceAdv can significantly improve success rate of both dodging and impersonating attacks. We also conduct comprehensive evaluations to demonstrate the robustness of FaceAdv.