 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets and Recipes for Video Temporal Grounding via Reinforcement Learning
Jul 24, 2025Video Temporal Grounding (VTG) aims to localize relevant temporal segments in videos given natural language queries. Despite recent progress with large vision-language models (LVLMs) and instruction-tuning, existing approaches often suffer from limited temporal awareness and poor generalization. In this work, we introduce a two-stage training framework that integrates supervised fine-tuning with reinforcement learning (RL) to improve both the accuracy and robustness of VTG models. Our approach first leverages high-quality curated cold start data for SFT initialization, followed by difficulty-controlled RL to further enhance temporal localization and reasoning abilities. Comprehensive experiments on multiple VTG benchmarks demonstrate that our method consistently outperforms existing models, particularly in challenging and open-domain scenarios. We conduct an in-depth analysis of training strategies and dataset curation, highlighting the importance of both high-quality cold start data and difficulty-controlled RL. To facilitate further research and industrial adoption, we release all intermediate datasets, models, and code to the community.
HLV-1K: A Large-scale Hour-Long Video Benchmark for Time-Specific Long Video Understanding
Jan 03, 2025



Multimodal large language models have become a popular topic in deep visual understanding due to many promising real-world applications. However, hour-long video understanding, spanning over one hour and containing tens of thousands of visual frames, remains under-explored because of 1) challenging long-term video analyses, 2) inefficient large-model approaches, and 3) lack of large-scale benchmark datasets. Among them, in this paper, we focus on building a large-scale hour-long long video benchmark, HLV-1K, designed to evaluate long video understanding models. HLV-1K comprises 1009 hour-long videos with 14,847 high-quality question answering (QA) and multi-choice question asnwering (MCQA) pairs with time-aware query and diverse annotations, covering frame-level, within-event-level, cross-event-level, and long-term reasoning tasks. We evaluate our benchmark using existing state-of-the-art methods and demonstrate its value for testing deep long video understanding capabilities at different levels and for various tasks. This includes promoting future long video understanding tasks at a granular level, such as deep understanding of long live videos, meeting recordings, and movies.
From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding
Sep 27, 2024



The integration of Large Language Models (LLMs) with visual encoders has recently shown promising performance in visual understanding tasks, leveraging their inherent capability to comprehend and generate human-like text for visual reasoning. Given the diverse nature of visual data, MultiModal Large Language Models (MM-LLMs) exhibit variations in model designing and training for understanding images, short videos, and long videos. Our paper focuses on the substantial differences and unique challenges posed by long video understanding compared to static image and short video understanding. Unlike static images, short videos encompass sequential frames with both spatial and within-event temporal information, while long videos consist of multiple events with between-event and long-term temporal information. In this survey, we aim to trace and summarize the advancements of MM-LLMs from image understanding to long video understanding. We review the differences among various visual understanding tasks and highlight the challenges in long video understanding, including more fine-grained spatiotemporal details, dynamic events, and long-term dependencies. We then provide a detailed summary of the advancements in MM-LLMs in terms of model design and training methodologies for understanding long videos. Finally, we compare the performance of existing MM-LLMs on video understanding benchmarks of various lengths and discuss potential future directions for MM-LLMs in long video understanding.
Text-based Talking Video Editing with Cascaded Conditional Diffusion
Jul 20, 2024
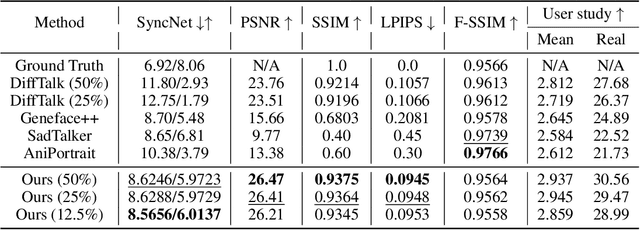


Text-based talking-head video editing aims to efficiently insert, delete, and substitute segments of talking videos through a user-friendly text editing approach. It is challenging because of \textbf{1)} generalizable talking-face representation, \textbf{2)} seamless audio-visual transitions, and \textbf{3)} identity-preserved talking faces. Previous works either require minutes of talking-face video training data and expensive test-time optimization for customized talking video editing or directly generate a video sequence without considering in-context information, leading to a poor generalizable representation, or incoherent transitions, or even inconsistent identity. In this paper, we propose an efficient cascaded conditional diffusion-based framework, which consists of two stages: audio to dense-landmark motion and motion to video. \textit{\textbf{In the first stage}}, we first propose a dynamic weighted in-context diffusion module to synthesize dense-landmark motions given an edited audio. \textit{\textbf{In the second stage}}, we introduce a warping-guided conditional diffusion module. The module first interpolates between the start and end frames of the editing interval to generate smooth intermediate frames. Then, with the help of the audio-to-dense motion images, these intermediate frames are warped to obtain coarse intermediate frames. Conditioned on the warped intermedia frames, a diffusion model is adopted to generate detailed and high-resolution target frames, which guarantees coherent and identity-preserved transitions. The cascaded conditional diffusion model decomposes the complex talking editing task into two flexible generation tasks, which provides a generalizable talking-face representation, seamless audio-visual transitions, and identity-preserved faces on a small dataset. Experiments show the effectiveness and superiority of the proposed method.
MIR-GAN: Refining Frame-Level Modality-Invariant Representations with Adversarial Network for Audio-Visual Speech Recognition
Jun 18, 2023



Audio-visual speech recognition (AVSR) attracts a surge of research interest recently by leveraging multimodal signals to understand human speech. Mainstream approaches addressing this task have developed sophisticated architectures and techniques for multi-modality fusion and representation learning. However, the natural heterogeneity of different modalities causes distribution gap between their representations, making it challenging to fuse them. In this paper, we aim to learn the shared representations across modalities to bridge their gap. Different from existing similar methods on other multimodal tasks like sentiment analysis, we focus on the temporal contextual dependencies considering the sequence-to-sequence task setting of AVSR. In particular, we propose an adversarial network to refine frame-level modality-invariant representations (MIR-GAN), which captures the commonality across modalities to ease the subsequent multimodal fusion process. Extensive experiments on public benchmarks LRS3 and LRS2 show that our approach outperforms the state-of-the-arts.
Towards Balanced Active Learning for Multimodal Classification
Jun 14, 2023



Training multimodal networks requires a vast amount of data due to their larger parameter space compared to unimodal networks. Active learning is a widely used technique for reducing data annotation costs by selecting only those samples that could contribute to improving model performance. However, current active learning strategies are mostly designed for unimodal tasks, and when applied to multimodal data, they often result in biased sample selection from the dominant modality. This unfairness hinders balanced multimodal learning, which is crucial for achieving optimal performance. To address this issue, we propose three guidelines for designing a more balanced multimodal active learning strategy. Following these guidelines, a novel approach is proposed to achieve more fair data selection by modulating the gradient embedding with the dominance degree among modalities. Our studies demonstrate that the proposed method achieves more balanced multimodal learning by avoiding greedy sample selection from the dominant modality. Our approach outperforms existing active learning strategies on a variety of multimodal classification tasks. Overall, our work highlights the importance of balancing sample selection in multimodal active learning and provides a practical solution for achieving more balanced active learning for multimodal classification.
UniS-MMC: Multimodal Classification via Unimodality-supervised Multimodal Contrastive Learning
May 16, 2023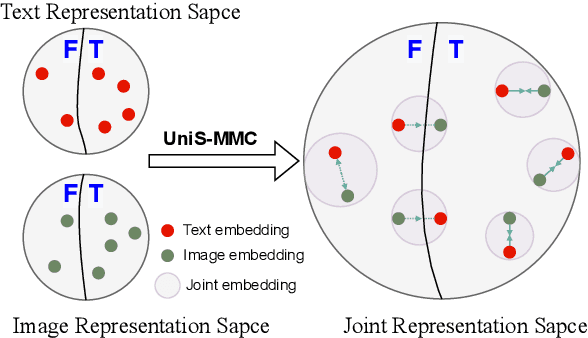
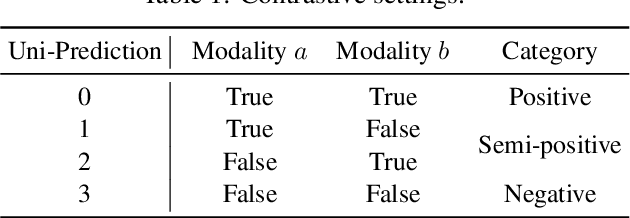
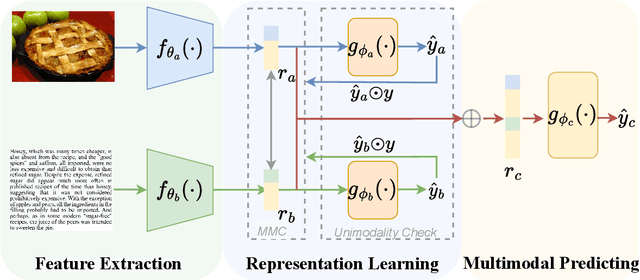
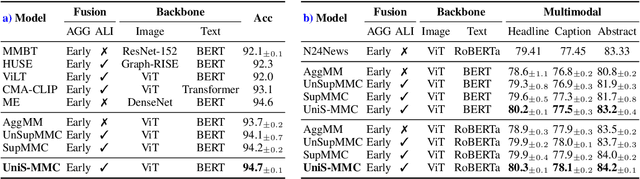
Multimodal learning aims to imitate human beings to acquire complementary information from multiple modalities for various downstream tasks. However, traditional aggregation-based multimodal fusion methods ignore the inter-modality relationship, treat each modality equally, suffer sensor noise, and thus reduce multimodal learning performance. In this work, we propose a novel multimodal contrastive method to explore more reliable multimodal representations under the weak supervision of unimodal predicting. Specifically, we first capture task-related unimodal representations and the unimodal predictions from the introduced unimodal predicting task. Then the unimodal representations are aligned with the more effective one by the designed multimodal contrastive method under the supervision of the unimodal predictions. Experimental results with fused features on two image-text classification benchmarks UPMC-Food-101 and N24News show that our proposed Unimodality-Supervised MultiModal Contrastive UniS-MMC learning method outperforms current state-of-the-art multimodal methods. The detailed ablation study and analysis further demonstrate the advantage of our proposed method.
Cross-Modal Global Interaction and Local Alignment for Audio-Visual Speech Recognition
May 16, 2023



Audio-visual speech recognition (AVSR) research has gained a great success recently by improving the noise-robustness of audio-only automatic speech recognition (ASR) with noise-invariant visual information. However, most existing AVSR approaches simply fuse the audio and visual features by concatenation, without explicit interactions to capture the deep correlations between them, which results in sub-optimal multimodal representations for downstream speech recognition task. In this paper, we propose a cross-modal global interaction and local alignment (GILA) approach for AVSR, which captures the deep audio-visual (A-V) correlations from both global and local perspectives. Specifically, we design a global interaction model to capture the A-V complementary relationship on modality level, as well as a local alignment approach to model the A-V temporal consistency on frame level. Such a holistic view of cross-modal correlations enable better multimodal representations for AVSR. Experiments on public benchmarks LRS3 and LRS2 show that our GILA outperforms the supervised learning state-of-the-art.
Unsupervised Noise adaptation using Data Simulation
Feb 23, 2023



Deep neural network based speech enhancement approaches aim to learn a noisy-to-clean transformation using a supervised learning paradigm. However, such a trained-well transformation is vulnerable to unseen noises that are not included in training set. In this work, we focus on the unsupervised noise adaptation problem in speech enhancement, where the ground truth of target domain data is completely unavailable. Specifically, we propose a generative adversarial network based method to efficiently learn a converse clean-to-noisy transformation using a few minutes of unpaired target domain data. Then this transformation is utilized to generate sufficient simulated data for domain adaptation of the enhancement model. Experimental results show that our method effectively mitigates the domain mismatch between training and test sets, and surpasses the best baseline by a large margin.
Unifying Speech Enhancement and Separation with Gradient Modulation for End-to-End Noise-Robust Speech Separation
Feb 22, 2023



Recent studies in neural network-based monaural speech separation (SS) have achieved a remarkable success thanks to increasing ability of long sequence modeling. However, they would degrade significantly when put under realistic noisy conditions, as the background noise could be mistaken for speaker's speech and thus interfere with the separated sources. To alleviate this problem, we propose a novel network to unify speech enhancement and separation with gradient modulation to improve noise-robustness. Specifically, we first build a unified network by combining speech enhancement (SE) and separation modules, with multi-task learning for optimization, where SE is supervised by parallel clean mixture to reduce noise for downstream speech separation. Furthermore, in order to avoid suppressing valid speaker information when reducing noise, we propose a gradient modulation (GM) strategy to harmonize the SE and SS tasks from optimization view. Experimental results show that our approach achieves the state-of-the-art on large-scale Libri2Mix- and Libri3Mix-noisy datasets, with SI-SNRi results of 16.0 dB and 15.8 dB respectively. Our code is available at GitHub.