 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDurIAN-E 2: Duration Informed Attention Network with Adaptive Variational Autoencoder and Adversarial Learning for Expressive Text-to-Speech Synthesis
Oct 17, 2024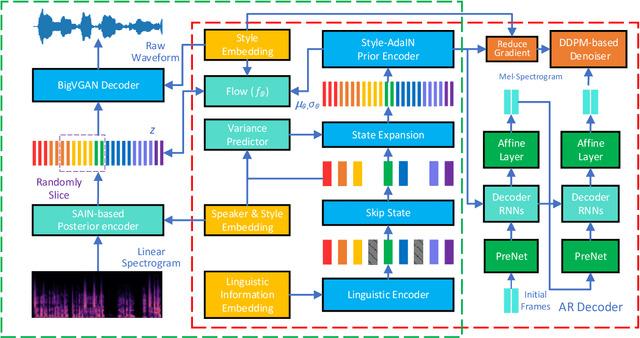
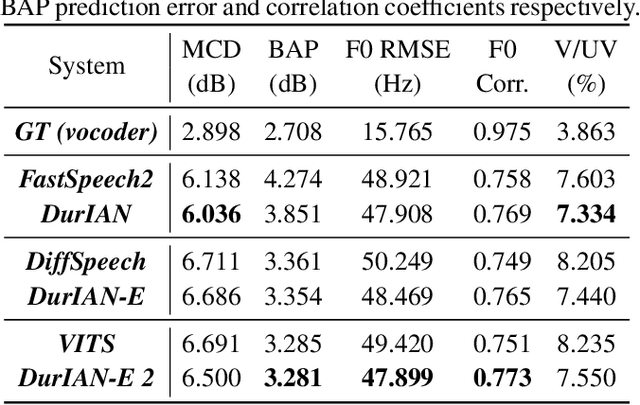
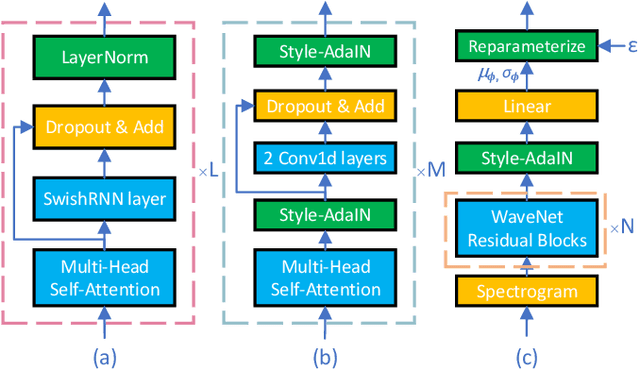

This paper proposes an improved version of DurIAN-E (DurIAN-E 2), which is also a duration informed attention neural network for expressive and high-fidelity text-to-speech (TTS) synthesis. Similar with the DurIAN-E model, multiple stacked SwishRNN-based Transformer blocks are utilized as linguistic encoders and Style-Adaptive Instance Normalization (SAIN) layers are also exploited into frame-level encoders to improve the modeling ability of expressiveness in the proposed the DurIAN-E 2. Meanwhile, motivated by other TTS models using generative models such as VITS, the proposed DurIAN-E 2 utilizes variational autoencoders (VAEs) augmented with normalizing flows and a BigVGAN waveform generator with adversarial training strategy, which further improve the synthesized speech quality and expressiveness. Both objective test and subjective evaluation results prove that the proposed expressive TTS model DurIAN-E 2 can achieve better performance than several state-of-the-art approaches besides DurIAN-E.
Listen Again and Choose the Right Answer: A New Paradigm for Automatic Speech Recognition with Large Language Models
May 16, 2024



Recent advances in large language models (LLMs) have promoted generative error correction (GER) for automatic speech recognition (ASR), which aims to predict the ground-truth transcription from the decoded N-best hypotheses. Thanks to the strong language generation ability of LLMs and rich information in the N-best list, GER shows great effectiveness in enhancing ASR results. However, it still suffers from two limitations: 1) LLMs are unaware of the source speech during GER, which may lead to results that are grammatically correct but violate the source speech content, 2) N-best hypotheses usually only vary in a few tokens, making it redundant to send all of them for GER, which could confuse LLM about which tokens to focus on and thus lead to increased miscorrection. In this paper, we propose ClozeGER, a new paradigm for ASR generative error correction. First, we introduce a multimodal LLM (i.e., SpeechGPT) to receive source speech as extra input to improve the fidelity of correction output. Then, we reformat GER as a cloze test with logits calibration to remove the input information redundancy and simplify GER with clear instructions. Experiments show that ClozeGER achieves a new breakthrough over vanilla GER on 9 popular ASR datasets.
Multichannel AV-wav2vec2: A Framework for Learning Multichannel Multi-Modal Speech Representation
Jan 07, 2024



Self-supervised speech pre-training methods have developed rapidly in recent years, which show to be very effective for many near-field single-channel speech tasks. However, far-field multichannel speech processing is suffering from the scarcity of labeled multichannel data and complex ambient noises. The efficacy of self-supervised learning for far-field multichannel and multi-modal speech processing has not been well explored. Considering that visual information helps to improve speech recognition performance in noisy scenes, in this work we propose a multichannel multi-modal speech self-supervised learning framework AV-wav2vec2, which utilizes video and multichannel audio data as inputs. First, we propose a multi-path structure to process multichannel audio streams and a visual stream in parallel, with intra- and inter-channel contrastive losses as training targets to fully exploit the spatiotemporal information in multichannel speech data. Second, based on contrastive learning, we use additional single-channel audio data, which is trained jointly to improve the performance of speech representation. Finally, we use a Chinese multichannel multi-modal dataset in real scenarios to validate the effectiveness of the proposed method on audio-visual speech recognition (AVSR), automatic speech recognition (ASR), visual speech recognition (VSR) and audio-visual speaker diarization (AVSD) tasks.
Rep2wav: Noise Robust text-to-speech Using self-supervised representations
Sep 04, 2023



Benefiting from the development of deep learning, text-to-speech (TTS) techniques using clean speech have achieved significant performance improvements. The data collected from real scenes often contains noise and generally needs to be denoised by speech enhancement models. Noise-robust TTS models are often trained using the enhanced speech, which thus suffer from speech distortion and background noise that affect the quality of the synthesized speech. Meanwhile, it was shown that self-supervised pre-trained models exhibit excellent noise robustness on many speech tasks, implying that the learned representation has a better tolerance for noise perturbations. In this work, we therefore explore pre-trained models to improve the noise robustness of TTS models. Based on HiFi-GAN, we first propose a representation-to-waveform vocoder, which aims to learn to map the representation of pre-trained models to the waveform. We then propose a text-to-representation FastSpeech2 model, which aims to learn to map text to pre-trained model representations. Experimental results on the LJSpeech and LibriTTS datasets show that our method outperforms those using speech enhancement methods in both subjective and objective metrics. Audio samples are available at: https://zqs01.github.io/rep2wav.
Noise-aware Speech Enhancement using Diffusion Probabilistic Model
Jul 16, 2023



With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech for inference, underexploiting the varying noise information in real-world conditions. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner for guiding the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks, in order to enhance the noise specificity of extracted noise conditioner. Our proposed NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiment evidence on VoiceBank-DEMAND dataset shows that NASE achieves significant improvement over multiple mainstream diffusion SE models, especially on unseen testing noises.
Hearing Lips in Noise: Universal Viseme-Phoneme Mapping and Transfer for Robust Audio-Visual Speech Recognition
Jun 18, 2023



Audio-visual speech recognition (AVSR) provides a promising solution to ameliorate the noise-robustness of audio-only speech recognition with visual information. However, most existing efforts still focus on audio modality to improve robustness considering its dominance in AVSR task, with noise adaptation techniques such as front-end denoise processing. Though effective, these methods are usually faced with two practical challenges: 1) lack of sufficient labeled noisy audio-visual training data in some real-world scenarios and 2) less optimal model generality to unseen testing noises. In this work, we investigate the noise-invariant visual modality to strengthen robustness of AVSR, which can adapt to any testing noises while without dependence on noisy training data, a.k.a., unsupervised noise adaptation. Inspired by human perception mechanism, we propose a universal viseme-phoneme mapping (UniVPM) approach to implement modality transfer, which can restore clean audio from visual signals to enable speech recognition under any noisy conditions. Extensive experiments on public benchmarks LRS3 and LRS2 show that our approach achieves the state-of-the-art under various noisy as well as clean conditions. In addition, we also outperform previous state-of-the-arts on visual speech recognition task.
Eeg2vec: Self-Supervised Electroencephalographic Representation Learning
May 23, 2023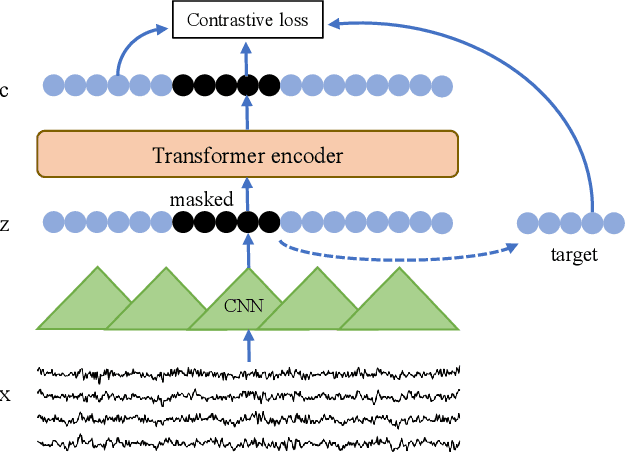
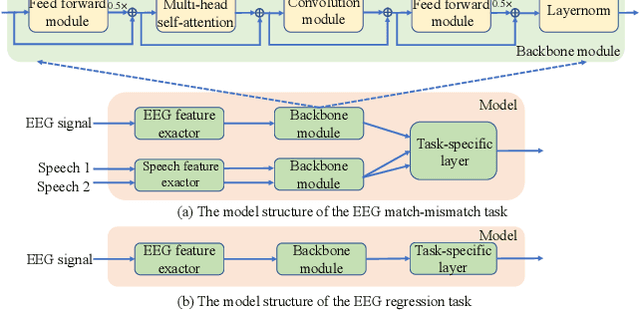
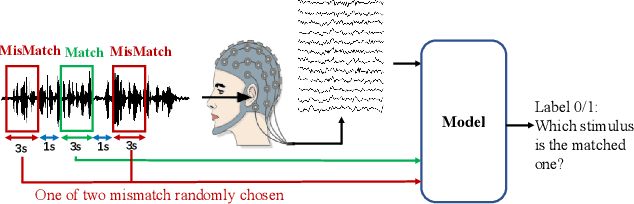
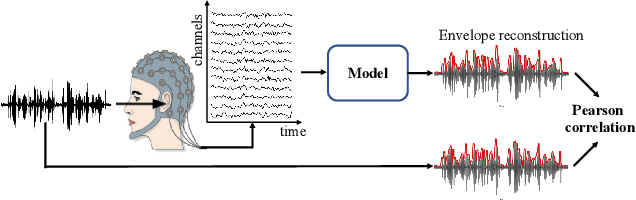
Recently, many efforts have been made to explore how the brain processes speech using electroencephalographic (EEG) signals, where deep learning-based approaches were shown to be applicable in this field. In order to decode speech signals from EEG signals, linear networks, convolutional neural networks (CNN) and long short-term memory networks are often used in a supervised manner. Recording EEG-speech labeled data is rather time-consuming and laborious, while unlabeled EEG data is abundantly available. Whether self-supervised methods are helpful to learn EEG representation to boost the performance of EEG auditory-related tasks has not been well explored. In this work, we first propose a self-supervised model based on contrastive loss and reconstruction loss to learn EEG representations, and then use the obtained pre-trained model as a feature extractor for downstream tasks. Second, for two considered downstream tasks, we use CNNs and Transformer networks to learn local features and global features, respectively. Finally, the EEG data from other channels are mixed into the chosen EEG data for augmentation. The effectiveness of our method is verified on the EEG match-mismatch and EEG regression tasks of the ICASSP2023 Auditory EEG Challenge.
Cross-Modal Global Interaction and Local Alignment for Audio-Visual Speech Recognition
May 16, 2023



Audio-visual speech recognition (AVSR) research has gained a great success recently by improving the noise-robustness of audio-only automatic speech recognition (ASR) with noise-invariant visual information. However, most existing AVSR approaches simply fuse the audio and visual features by concatenation, without explicit interactions to capture the deep correlations between them, which results in sub-optimal multimodal representations for downstream speech recognition task. In this paper, we propose a cross-modal global interaction and local alignment (GILA) approach for AVSR, which captures the deep audio-visual (A-V) correlations from both global and local perspectives. Specifically, we design a global interaction model to capture the A-V complementary relationship on modality level, as well as a local alignment approach to model the A-V temporal consistency on frame level. Such a holistic view of cross-modal correlations enable better multimodal representations for AVSR. Experiments on public benchmarks LRS3 and LRS2 show that our GILA outperforms the supervised learning state-of-the-art.
Wav2code: Restore Clean Speech Representations via Codebook Lookup for Noise-Robust ASR
Apr 23, 2023



Automatic speech recognition (ASR) has gained a remarkable success thanks to recent advances of deep learning, but it usually degrades significantly under real-world noisy conditions. Recent works introduce speech enhancement (SE) as front-end to improve speech quality, which is proved effective but may not be optimal for downstream ASR due to speech distortion problem. Based on that, latest works combine SE and currently popular self-supervised learning (SSL) to alleviate distortion and improve noise robustness. Despite the effectiveness, the speech distortion caused by conventional SE still cannot be completely eliminated. In this paper, we propose a self-supervised framework named Wav2code to implement a generalized SE without distortions for noise-robust ASR. First, in pre-training stage the clean speech representations from SSL model are sent to lookup a discrete codebook via nearest-neighbor feature matching, the resulted code sequence are then exploited to reconstruct the original clean representations, in order to store them in codebook as prior. Second, during finetuning we propose a Transformer-based code predictor to accurately predict clean codes by modeling the global dependency of input noisy representations, which enables discovery and restoration of high-quality clean representations without distortions. Furthermore, we propose an interactive feature fusion network to combine original noisy and the restored clean representations to consider both fidelity and quality, resulting in even more informative features for downstream ASR. Finally, experiments on both synthetic and real noisy datasets demonstrate that Wav2code can solve the speech distortion and improve ASR performance under various noisy conditions, resulting in stronger robustness.
Gradient Remedy for Multi-Task Learning in End-to-End Noise-Robust Speech Recognition
Feb 22, 2023



Speech enhancement (SE) is proved effective in reducing noise from noisy speech signals for downstream automatic speech recognition (ASR), where multi-task learning strategy is employed to jointly optimize these two tasks. However, the enhanced speech learned by SE objective may not always yield good ASR results. From the optimization view, there sometimes exists interference between the gradients of SE and ASR tasks, which could hinder the multi-task learning and finally lead to sub-optimal ASR performance. In this paper, we propose a simple yet effective approach called gradient remedy (GR) to solve interference between task gradients in noise-robust speech recognition, from perspectives of both angle and magnitude. Specifically, we first project the SE task's gradient onto a dynamic surface that is at acute angle to ASR gradient, in order to remove the conflict between them and assist in ASR optimization. Furthermore, we adaptively rescale the magnitude of two gradients to prevent the dominant ASR task from being misled by SE gradient. Experimental results show that the proposed approach well resolves the gradient interference and achieves relative word error rate (WER) reductions of 9.3% and 11.1% over multi-task learning baseline, on RATS and CHiME-4 datasets, respectively. Our code is available at GitHub.