 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEeg2vec: Self-Supervised Electroencephalographic Representation Learning
Paper and Code
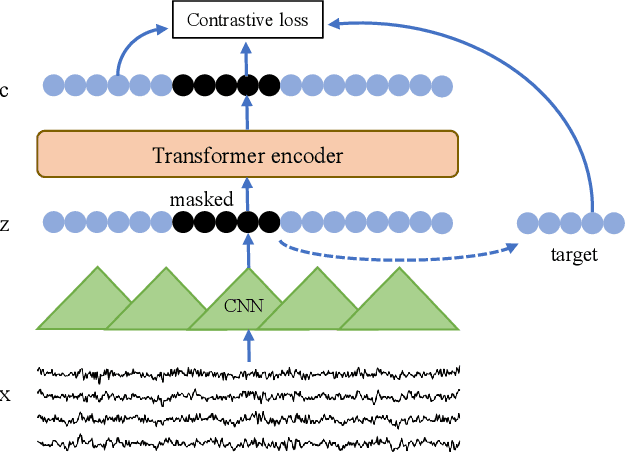
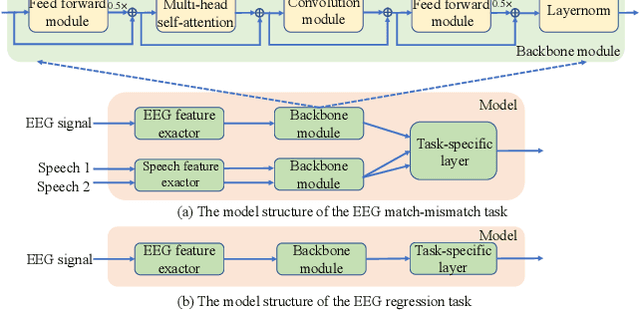
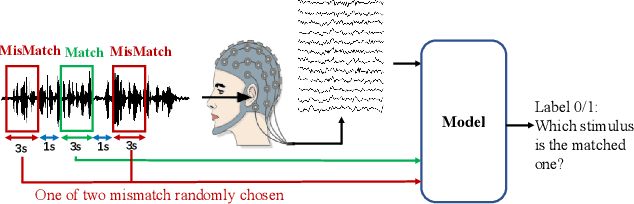
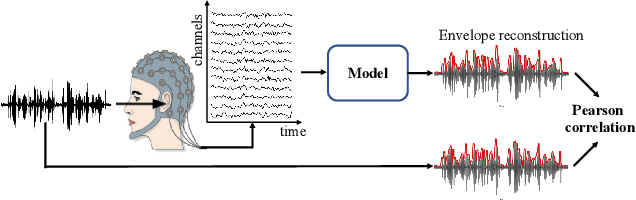
Recently, many efforts have been made to explore how the brain processes speech using electroencephalographic (EEG) signals, where deep learning-based approaches were shown to be applicable in this field. In order to decode speech signals from EEG signals, linear networks, convolutional neural networks (CNN) and long short-term memory networks are often used in a supervised manner. Recording EEG-speech labeled data is rather time-consuming and laborious, while unlabeled EEG data is abundantly available. Whether self-supervised methods are helpful to learn EEG representation to boost the performance of EEG auditory-related tasks has not been well explored. In this work, we first propose a self-supervised model based on contrastive loss and reconstruction loss to learn EEG representations, and then use the obtained pre-trained model as a feature extractor for downstream tasks. Second, for two considered downstream tasks, we use CNNs and Transformer networks to learn local features and global features, respectively. Finally, the EEG data from other channels are mixed into the chosen EEG data for augmentation. The effectiveness of our method is verified on the EEG match-mismatch and EEG regression tasks of the ICASSP2023 Auditory EEG Challenge.