 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioGenie: A Training-Free Multi-Agent Framework for Diverse Multimodality-to-Multiaudio Generation
May 28, 2025Multimodality-to-Multiaudio (MM2MA) generation faces significant challenges in synthesizing diverse and contextually aligned audio types (e.g., sound effects, speech, music, and songs) from multimodal inputs (e.g., video, text, images), owing to the scarcity of high-quality paired datasets and the lack of robust multi-task learning frameworks. Recently, multi-agent system shows great potential in tackling the above issues. However, directly applying it to MM2MA task presents three critical challenges: (1) inadequate fine-grained understanding of multimodal inputs (especially for video), (2) the inability of single models to handle diverse audio events, and (3) the absence of self-correction mechanisms for reliable outputs. To this end, we propose AudioGenie, a novel training-free multi-agent system featuring a dual-layer architecture with a generation team and a supervisor team. For the generation team, a fine-grained task decomposition and an adaptive Mixture-of-Experts (MoE) collaborative entity are designed for dynamic model selection, and a trial-and-error iterative refinement module is designed for self-correction. The supervisor team ensures temporal-spatial consistency and verifies outputs through feedback loops. Moreover, we build MA-Bench, the first benchmark for MM2MA tasks, comprising 198 annotated videos with multi-type audios. Experiments demonstrate that our AudioGenie outperforms state-of-the-art (SOTA) methods across 9 metrics in 8 tasks. User study further validate the effectiveness of the proposed method in terms of quality, accuracy, alignment, and aesthetic. The anonymous project website with samples can be found at https://audiogenie.github.io/.
Dopamine Audiobook: A Training-free MLLM Agent for Emotional and Human-like Audiobook Generation
Apr 15, 2025Audiobook generation, which creates vivid and emotion-rich audio works, faces challenges in conveying complex emotions, achieving human-like qualities, and aligning evaluations with human preferences. Existing text-to-speech (TTS) methods are often limited to specific scenarios, struggle with emotional transitions, and lack automatic human-aligned evaluation benchmarks, instead relying on either misaligned automated metrics or costly human assessments. To address these issues, we propose Dopamine Audiobook, a new unified training-free system leveraging a multimodal large language model (MLLM) as an AI agent for emotional and human-like audiobook generation and evaluation. Specifically, we first design a flow-based emotion-enhanced framework that decomposes complex emotional speech synthesis into controllable sub-tasks. Then, we propose an adaptive model selection module that dynamically selects the most suitable TTS methods from a set of existing state-of-the-art (SOTA) TTS methods for diverse scenarios. We further enhance emotional expressiveness through paralinguistic augmentation and prosody retrieval at word and utterance levels. For evaluation, we propose a novel GPT-based evaluation framework incorporating self-critique, perspective-taking, and psychological MagicEmo prompts to ensure human-aligned and self-aligned assessments. Experiments show that our method generates long speech with superior emotional expression to SOTA TTS models in various metrics. Importantly, our evaluation framework demonstrates better alignment with human preferences and transferability across audio tasks. Project website with audio samples can be found at https://dopamine-audiobook.github.io.
DurIAN-E 2: Duration Informed Attention Network with Adaptive Variational Autoencoder and Adversarial Learning for Expressive Text-to-Speech Synthesis
Oct 17, 2024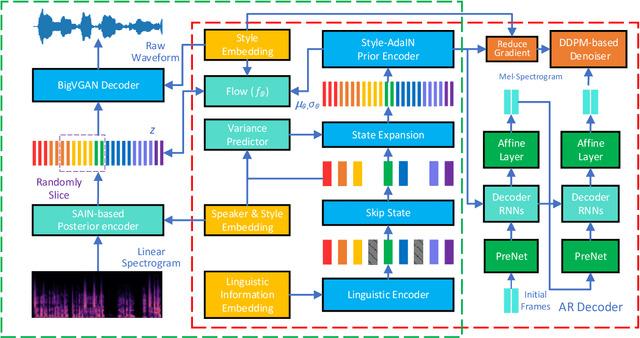
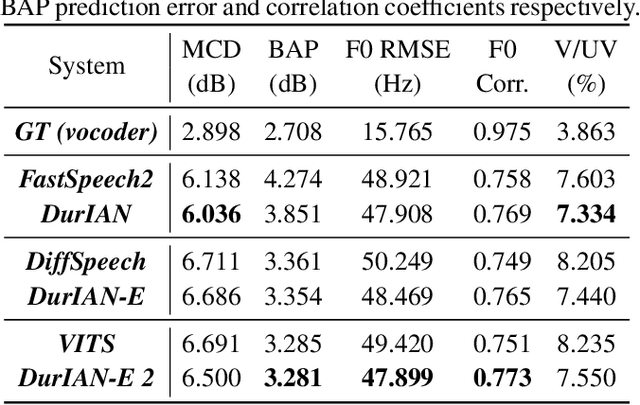
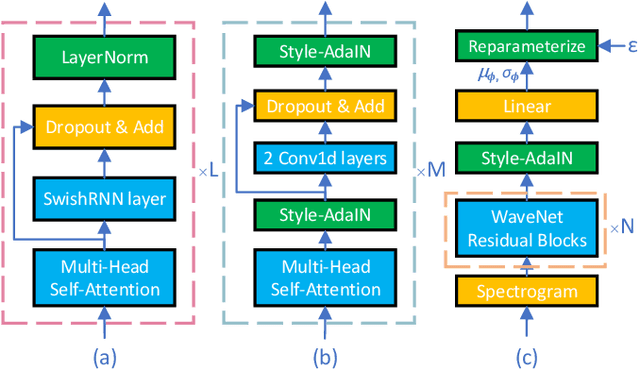

This paper proposes an improved version of DurIAN-E (DurIAN-E 2), which is also a duration informed attention neural network for expressive and high-fidelity text-to-speech (TTS) synthesis. Similar with the DurIAN-E model, multiple stacked SwishRNN-based Transformer blocks are utilized as linguistic encoders and Style-Adaptive Instance Normalization (SAIN) layers are also exploited into frame-level encoders to improve the modeling ability of expressiveness in the proposed the DurIAN-E 2. Meanwhile, motivated by other TTS models using generative models such as VITS, the proposed DurIAN-E 2 utilizes variational autoencoders (VAEs) augmented with normalizing flows and a BigVGAN waveform generator with adversarial training strategy, which further improve the synthesized speech quality and expressiveness. Both objective test and subjective evaluation results prove that the proposed expressive TTS model DurIAN-E 2 can achieve better performance than several state-of-the-art approaches besides DurIAN-E.
DurIAN-E: Duration Informed Attention Network For Expressive Text-to-Speech Synthesis
Sep 22, 2023This paper introduces an improved duration informed attention neural network (DurIAN-E) for expressive and high-fidelity text-to-speech (TTS) synthesis. Inherited from the original DurIAN model, an auto-regressive model structure in which the alignments between the input linguistic information and the output acoustic features are inferred from a duration model is adopted. Meanwhile the proposed DurIAN-E utilizes multiple stacked SwishRNN-based Transformer blocks as linguistic encoders. Style-Adaptive Instance Normalization (SAIN) layers are exploited into frame-level encoders to improve the modeling ability of expressiveness. A denoiser incorporating both denoising diffusion probabilistic model (DDPM) for mel-spectrograms and SAIN modules is conducted to further improve the synthetic speech quality and expressiveness. Experimental results prove that the proposed expressive TTS model in this paper can achieve better performance than the state-of-the-art approaches in both subjective mean opinion score (MOS) and preference tests.
InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
Jan 31, 2023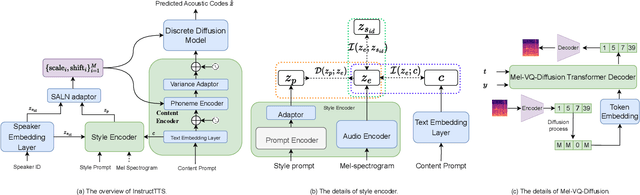
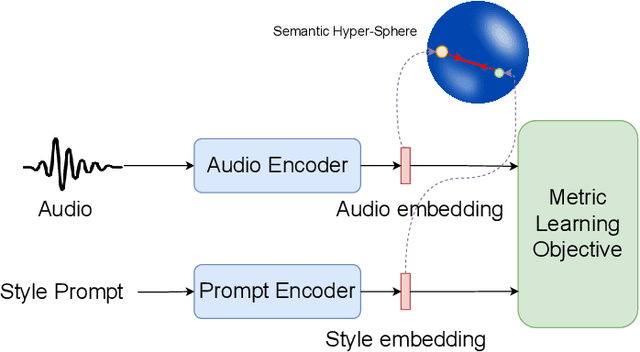
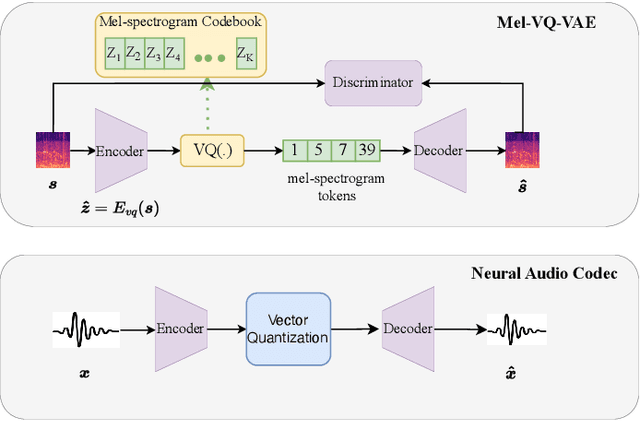
Expressive text-to-speech (TTS) aims to synthesize different speaking style speech according to human's demands. Nowadays, there are two common ways to control speaking styles: (1) Pre-defining a group of speaking style and using categorical index to denote different speaking style. However, there are limitations in the diversity of expressiveness, as these models can only generate the pre-defined styles. (2) Using reference speech as style input, which results in a problem that the extracted style information is not intuitive or interpretable. In this study, we attempt to use natural language as style prompt to control the styles in the synthetic speech, \textit{e.g.}, ``Sigh tone in full of sad mood with some helpless feeling". Considering that there is no existing TTS corpus which is proper to benchmark this novel task, we first construct a speech corpus, whose speech samples are annotated with not only content transcriptions but also style descriptions in natural language. Then we propose an expressive TTS model, named as InstructTTS, which is novel in the sense of following aspects: (1) We fully take the advantage of self-supervised learning and cross-modal metric learning, and propose a novel three-stage training procedure to obtain a robust sentence embedding model, which can effectively capture semantic information from the style prompts and control the speaking style in the generated speech. (2) We propose to model acoustic features in discrete latent space and train a novel discrete diffusion probabilistic model to generate vector-quantized (VQ) acoustic tokens rather than the commonly-used mel spectrogram. (3) We jointly apply mutual information (MI) estimation and minimization during acoustic model training to minimize style-speaker and style-content MI, avoiding possible content and speaker information leakage from the style prompt.
Speaker Independent and Multilingual/Mixlingual Speech-Driven Talking Head Generation Using Phonetic Posteriorgrams
Jun 20, 2020
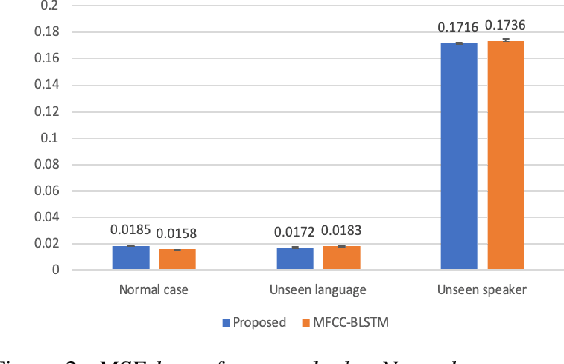
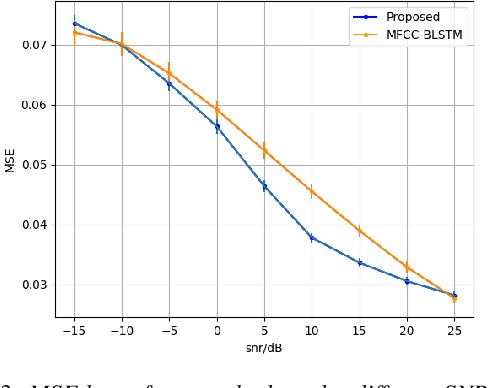
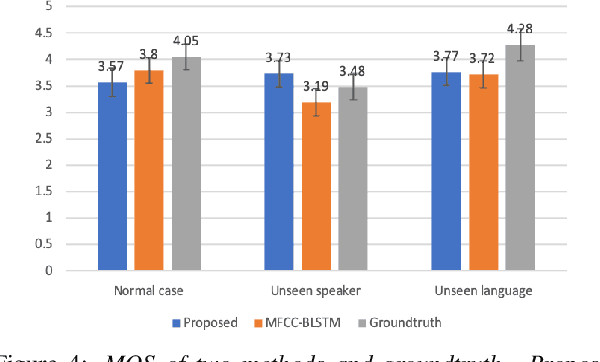
Generating 3D speech-driven talking head has received more and more attention in recent years. Recent approaches mainly have following limitations: 1) most speaker-independent methods need handcrafted features that are time-consuming to design or unreliable; 2) there is no convincing method to support multilingual or mixlingual speech as input. In this work, we propose a novel approach using phonetic posteriorgrams (PPG). In this way, our method doesn't need hand-crafted features and is more robust to noise compared to recent approaches. Furthermore, our method can support multilingual speech as input by building a universal phoneme space. As far as we know, our model is the first to support multilingual/mixlingual speech as input with convincing results. Objective and subjective experiments have shown that our model can generate high quality animations given speech from unseen languages or speakers and be robust to noise.
DurIAN: Duration Informed Attention Network For Multimodal Synthesis
Sep 05, 2019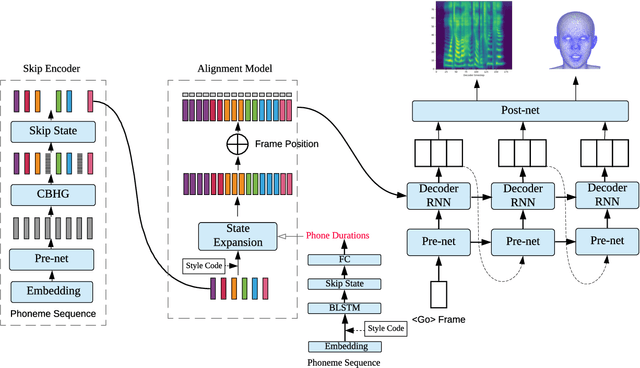
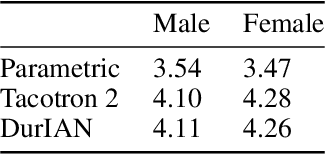
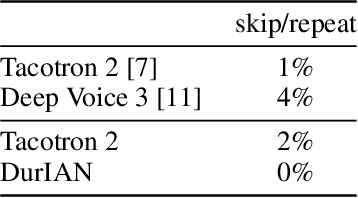
In this paper, we present a generic and robust multimodal synthesis system that produces highly natural speech and facial expression simultaneously. The key component of this system is the Duration Informed Attention Network (DurIAN), an autoregressive model in which the alignments between the input text and the output acoustic features are inferred from a duration model. This is different from the end-to-end attention mechanism used, and accounts for various unavoidable artifacts, in existing end-to-end speech synthesis systems such as Tacotron. Furthermore, DurIAN can be used to generate high quality facial expression which can be synchronized with generated speech with/without parallel speech and face data. To improve the efficiency of speech generation, we also propose a multi-band parallel generation strategy on top of the WaveRNN model. The proposed Multi-band WaveRNN effectively reduces the total computational complexity from 9.8 to 5.5 GFLOPS, and is able to generate audio that is 6 times faster than real time on a single CPU core. We show that DurIAN could generate highly natural speech that is on par with current state of the art end-to-end systems, while at the same time avoid word skipping/repeating errors in those systems. Finally, a simple yet effective approach for fine-grained control of expressiveness of speech and facial expression is introduced.