 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisambiguation of Chinese Polyphones in an End-to-End Framework with Semantic Features Extracted by Pre-trained BERT
Jan 02, 2025



Grapheme-to-phoneme (G2P) conversion serves as an essential component in Chinese Mandarin text-to-speech (TTS) system, where polyphone disambiguation is the core issue. In this paper, we propose an end-to-end framework to predict the pronunciation of a polyphonic character, which accepts sentence containing polyphonic character as input in the form of Chinese character sequence without the necessity of any preprocessing. The proposed method consists of a pre-trained bidirectional encoder representations from Transformers (BERT) model and a neural network (NN) based classifier. The pre-trained BERT model extracts semantic features from a raw Chinese character sequence and the NN based classifier predicts the polyphonic character's pronunciation according to BERT output. In out experiments, we implemented three classifiers, a fully-connected network based classifier, a long short-term memory (LSTM) network based classifier and a Transformer block based classifier. The experimental results compared with the baseline approach based on LSTM demonstrate that, the pre-trained model extracts effective semantic features, which greatly enhances the performance of polyphone disambiguation. In addition, we also explored the impact of contextual information on polyphone disambiguation.
* Accepted at INTERSPEECH 2019
learning discriminative features from spectrograms using center loss for speech emotion recognition
Jan 02, 2025Identifying the emotional state from speech is essential for the natural interaction of the machine with the speaker. However, extracting effective features for emotion recognition is difficult, as emotions are ambiguous. We propose a novel approach to learn discriminative features from variable length spectrograms for emotion recognition by cooperating softmax cross-entropy loss and center loss together. The softmax cross-entropy loss enables features from different emotion categories separable, and center loss efficiently pulls the features belonging to the same emotion category to their center. By combining the two losses together, the discriminative power will be highly enhanced, which leads to network learning more effective features for emotion recognition. As demonstrated by the experimental results, after introducing center loss, both the unweighted accuracy and weighted accuracy are improved by over 3\% on Mel-spectrogram input, and more than 4\% on Short Time Fourier Transform spectrogram input.
* Accepted at ICASSP 2019
Multi-modal Adversarial Training for Zero-Shot Voice Cloning
Aug 28, 2024A text-to-speech (TTS) model trained to reconstruct speech given text tends towards predictions that are close to the average characteristics of a dataset, failing to model the variations that make human speech sound natural. This problem is magnified for zero-shot voice cloning, a task that requires training data with high variance in speaking styles. We build off of recent works which have used Generative Advsarial Networks (GAN) by proposing a Transformer encoder-decoder architecture to conditionally discriminates between real and generated speech features. The discriminator is used in a training pipeline that improves both the acoustic and prosodic features of a TTS model. We introduce our novel adversarial training technique by applying it to a FastSpeech2 acoustic model and training on Libriheavy, a large multi-speaker dataset, for the task of zero-shot voice cloning. Our model achieves improvements over the baseline in terms of speech quality and speaker similarity. Audio examples from our system are available online.
RFWave: Multi-band Rectified Flow for Audio Waveform Reconstruction
Mar 08, 2024Recent advancements in generative modeling have led to significant progress in audio waveform reconstruction from diverse representations. Although diffusion models have been used for reconstructing audio waveforms, they tend to exhibit latency issues because they operate at the level of individual sample points and require a relatively large number of sampling steps. In this study, we introduce RFWave, a novel multi-band Rectified Flow approach that reconstructs high-fidelity audio waveforms from Mel-spectrograms. RFWave is distinctive for generating complex spectrograms and operating at the frame level, processing all subbands concurrently to enhance efficiency. Thanks to Rectified Flow, which aims for a flat transport trajectory, RFWave requires only 10 sampling steps. Empirical evaluations demonstrate that RFWave achieves exceptional reconstruction quality and superior computational efficiency, capable of generating audio at a speed 90 times faster than real-time.
Cloning one's voice using very limited data in the wild
Oct 08, 2021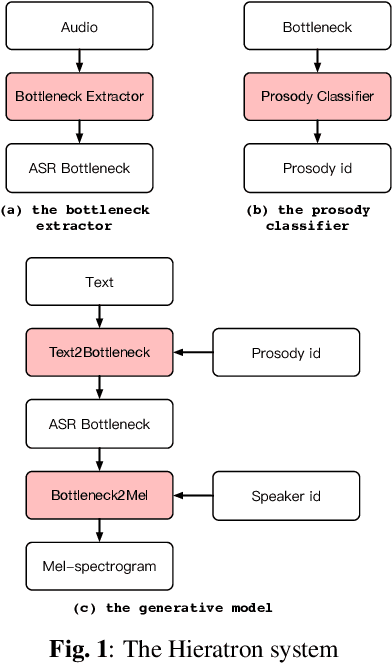
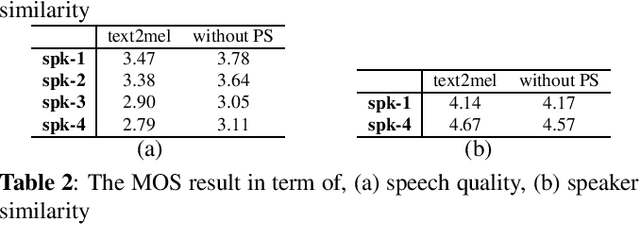
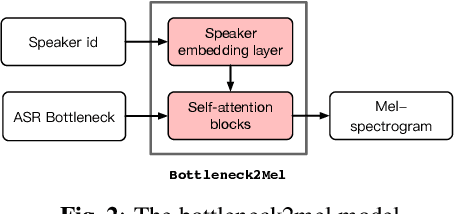
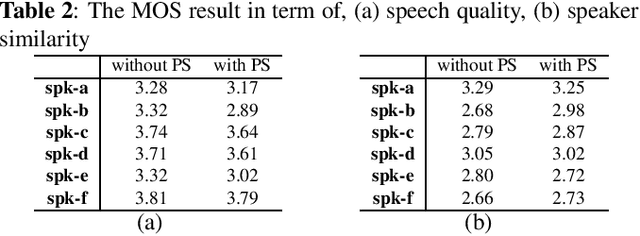
With the increasing popularity of speech synthesis products, the industry has put forward more requirements for personalized speech synthesis: (1) How to use low-resource, easily accessible data to clone a person's voice. (2) How to clone a person's voice while controlling the style and prosody. To solve the above two problems, we proposed the Hieratron model framework in which the prosody and timbre are modeled separately using two modules, therefore, the independent control of timbre and the other characteristics of audio can be achieved while generating speech. The practice shows that, for very limited target speaker data in the wild, Hieratron has obvious advantages over the traditional method, in addition to controlling the style and language of the generated speech, the mean opinion score on speech quality of the generated speech has also been improved by more than 0.2 points.
Unsupervised Cross-Lingual Speech Emotion Recognition Using DomainAdversarial Neural Network
Dec 21, 2020



By using deep learning approaches, Speech Emotion Recog-nition (SER) on a single domain has achieved many excellentresults. However, cross-domain SER is still a challenging taskdue to the distribution shift between source and target domains.In this work, we propose a Domain Adversarial Neural Net-work (DANN) based approach to mitigate this distribution shiftproblem for cross-lingual SER. Specifically, we add a languageclassifier and gradient reversal layer after the feature extractor toforce the learned representation both language-independent andemotion-meaningful. Our method is unsupervised, i. e., labelson target language are not required, which makes it easier to ap-ply our method to other languages. Experimental results showthe proposed method provides an average absolute improve-ment of 3.91% over the baseline system for arousal and valenceclassification task. Furthermore, we find that batch normaliza-tion is beneficial to the performance gain of DANN. Thereforewe also explore the effect of different ways of data combinationfor batch normalization.
Speaker Independent and Multilingual/Mixlingual Speech-Driven Talking Head Generation Using Phonetic Posteriorgrams
Jun 20, 2020
Generating 3D speech-driven talking head has received more and more attention in recent years. Recent approaches mainly have following limitations: 1) most speaker-independent methods need handcrafted features that are time-consuming to design or unreliable; 2) there is no convincing method to support multilingual or mixlingual speech as input. In this work, we propose a novel approach using phonetic posteriorgrams (PPG). In this way, our method doesn't need hand-crafted features and is more robust to noise compared to recent approaches. Furthermore, our method can support multilingual speech as input by building a universal phoneme space. As far as we know, our model is the first to support multilingual/mixlingual speech as input with convincing results. Objective and subjective experiments have shown that our model can generate high quality animations given speech from unseen languages or speakers and be robust to noise.
Noise Robust TTS for Low Resource Speakers using Pre-trained Model and Speech Enhancement
May 26, 2020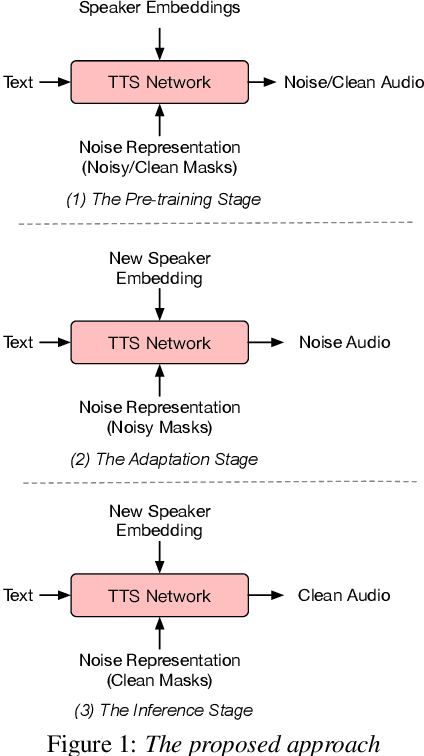
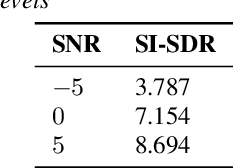
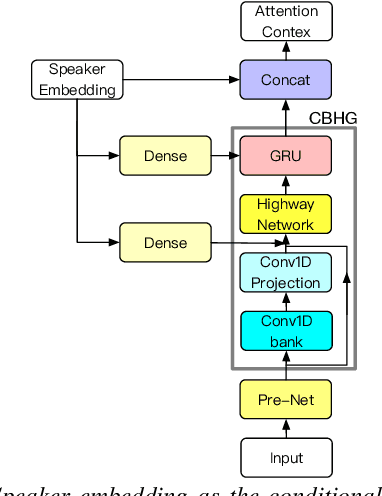
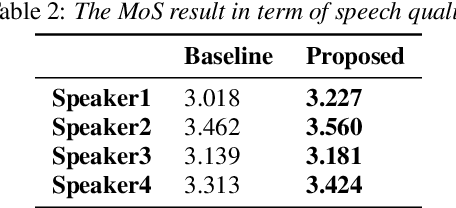
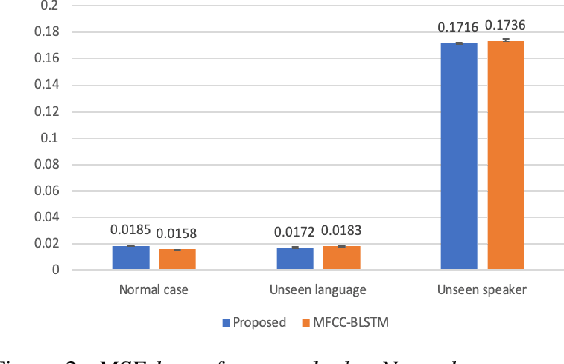
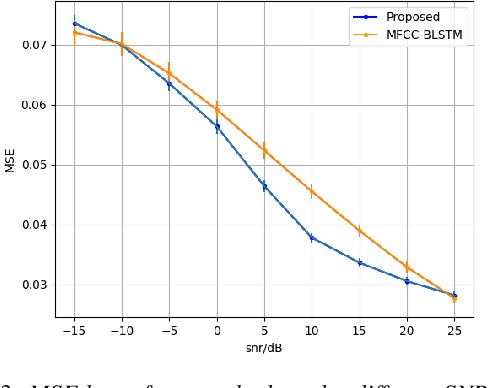
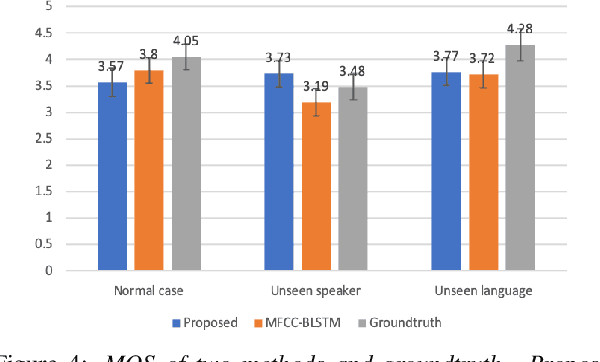
With the popularity of deep neural network, speech synthesis task has achieved significant improvements based on the end-to-end encoder-decoder framework in the recent days. More and more applications relying on speech synthesis technology have been widely used in our daily life. Robust speech synthesis model depends on high quality and customized data which needs lots of collecting efforts. It is worth investigating how to take advantage of low-quality and low resource voice data which can be easily obtained from the Internet for usage of synthesizing personalized voice. In this paper, the proposed end-to-end speech synthesis model uses both speaker embedding and noise representation as conditional inputs to model speaker and noise information respectively. Firstly, the speech synthesis model is pre-trained with both multi-speaker clean data and noisy augmented data; then the pre-trained model is adapted on noisy low-resource new speaker data; finally, by setting the clean speech condition, the model can synthesize the new speaker's clean voice. Experimental results show that the speech generated by the proposed approach has better subjective evaluation results than the method directly fine-tuning pre-trained multi-speaker speech synthesis model with denoised new speaker data.