 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Based Genetic Algorithm for Crypto Trading Strategy Optimization
Oct 09, 2025Cryptocurrency markets present formidable challenges for trading strategy optimization due to extreme volatility, non-stationary dynamics, and complex microstructure patterns that render conventional parameter optimization methods fundamentally inadequate. We introduce Cypto Genetic Algorithm Agent (CGA-Agent), a pioneering hybrid framework that synergistically integrates genetic algorithms with intelligent multi-agent coordination mechanisms for adaptive trading strategy parameter optimization in dynamic financial environments. The framework uniquely incorporates real-time market microstructure intelligence and adaptive strategy performance feedback through intelligent mechanisms that dynamically guide evolutionary processes, transcending the limitations of static optimization approaches. Comprehensive empirical evaluation across three cryptocurrencies demonstrates systematic and statistically significant performance improvements on both total returns and risk-adjusted metrics.
learning discriminative features from spectrograms using center loss for speech emotion recognition
Jan 02, 2025Identifying the emotional state from speech is essential for the natural interaction of the machine with the speaker. However, extracting effective features for emotion recognition is difficult, as emotions are ambiguous. We propose a novel approach to learn discriminative features from variable length spectrograms for emotion recognition by cooperating softmax cross-entropy loss and center loss together. The softmax cross-entropy loss enables features from different emotion categories separable, and center loss efficiently pulls the features belonging to the same emotion category to their center. By combining the two losses together, the discriminative power will be highly enhanced, which leads to network learning more effective features for emotion recognition. As demonstrated by the experimental results, after introducing center loss, both the unweighted accuracy and weighted accuracy are improved by over 3\% on Mel-spectrogram input, and more than 4\% on Short Time Fourier Transform spectrogram input.
* Accepted at ICASSP 2019
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 11, 2023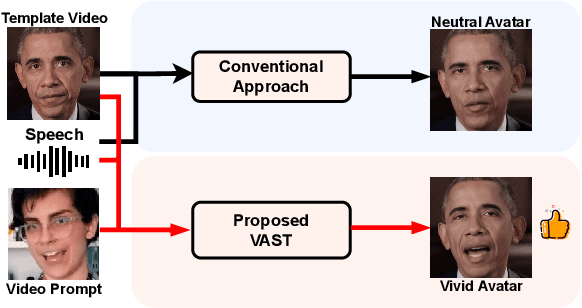

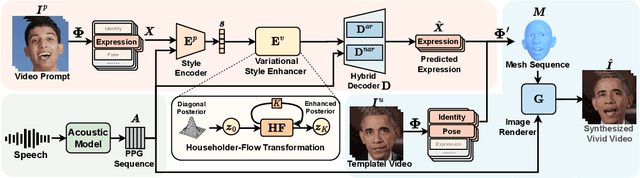

Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
HiFace: High-Fidelity 3D Face Reconstruction by Learning Static and Dynamic Details
Mar 20, 20233D Morphable Models (3DMMs) demonstrate great potential for reconstructing faithful and animatable 3D facial surfaces from a single image. The facial surface is influenced by the coarse shape, as well as the static detail (e,g., person-specific appearance) and dynamic detail (e.g., expression-driven wrinkles). Previous work struggles to decouple the static and dynamic details through image-level supervision, leading to reconstructions that are not realistic. In this paper, we aim at high-fidelity 3D face reconstruction and propose HiFace to explicitly model the static and dynamic details. Specifically, the static detail is modeled as the linear combination of a displacement basis, while the dynamic detail is modeled as the linear interpolation of two displacement maps with polarized expressions. We exploit several loss functions to jointly learn the coarse shape and fine details with both synthetic and real-world datasets, which enable HiFace to reconstruct high-fidelity 3D shapes with animatable details. Extensive quantitative and qualitative experiments demonstrate that HiFace presents state-of-the-art reconstruction quality and faithfully recovers both the static and dynamic details. Our project page can be found at https://project-hiface.github.io
ERA-Solver: Error-Robust Adams Solver for Fast Sampling of Diffusion Probabilistic Models
Feb 06, 2023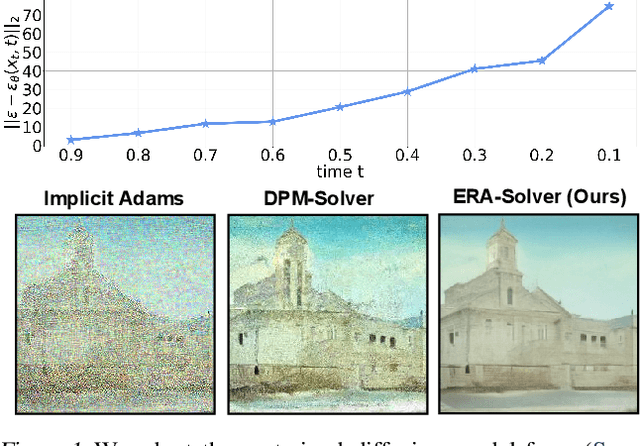

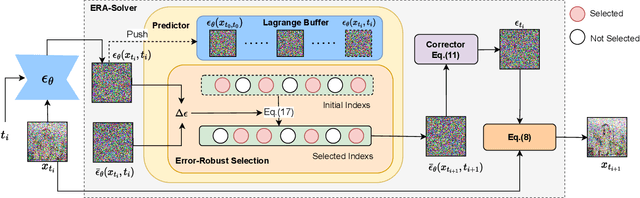
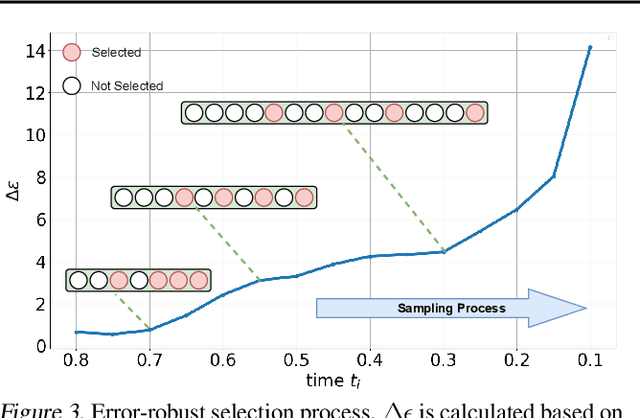
Though denoising diffusion probabilistic models (DDPMs) have achieved remarkable generation results, the low sampling efficiency of DDPMs still limits further applications. Since DDPMs can be formulated as diffusion ordinary differential equations (ODEs), various fast sampling methods can be derived from solving diffusion ODEs. However, we notice that previous sampling methods with fixed analytical form are not robust with the error in the noise estimated from pretrained diffusion models. In this work, we construct an error-robust Adams solver (ERA-Solver), which utilizes the implicit Adams numerical method that consists of a predictor and a corrector. Different from the traditional predictor based on explicit Adams methods, we leverage a Lagrange interpolation function as the predictor, which is further enhanced with an error-robust strategy to adaptively select the Lagrange bases with lower error in the estimated noise. Experiments on Cifar10, LSUN-Church, and LSUN-Bedroom datasets demonstrate that our proposed ERA-Solver achieves 5.14, 9.42, and 9.69 Fenchel Inception Distance (FID) for image generation, with only 10 network evaluations.
Memories are One-to-Many Mapping Alleviators in Talking Face Generation
Dec 12, 2022
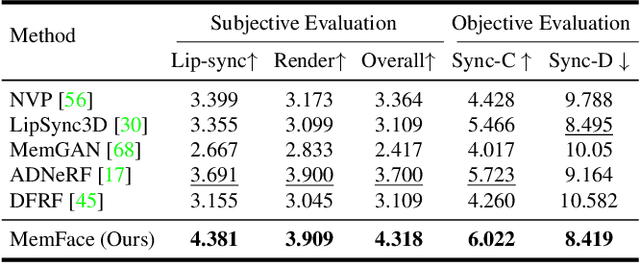
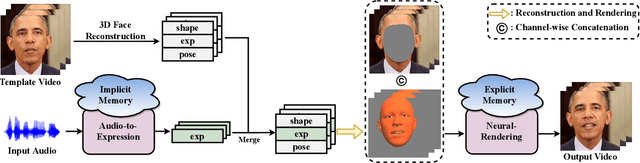
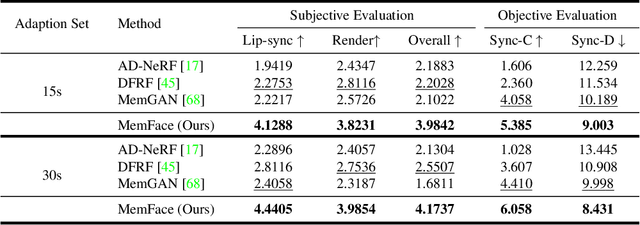
Talking face generation aims at generating photo-realistic video portraits of a target person driven by input audio. Due to its nature of one-to-many mapping from the input audio to the output video (e.g., one speech content may have multiple feasible visual appearances), learning a deterministic mapping like previous works brings ambiguity during training, and thus causes inferior visual results. Although this one-to-many mapping could be alleviated in part by a two-stage framework (i.e., an audio-to-expression model followed by a neural-rendering model), it is still insufficient since the prediction is produced without enough information (e.g., emotions, wrinkles, etc.). In this paper, we propose MemFace to complement the missing information with an implicit memory and an explicit memory that follow the sense of the two stages respectively. More specifically, the implicit memory is employed in the audio-to-expression model to capture high-level semantics in the audio-expression shared space, while the explicit memory is employed in the neural-rendering model to help synthesize pixel-level details. Our experimental results show that our proposed MemFace surpasses all the state-of-the-art results across multiple scenarios consistently and significantly.
StableFace: Analyzing and Improving Motion Stability for Talking Face Generation
Aug 29, 2022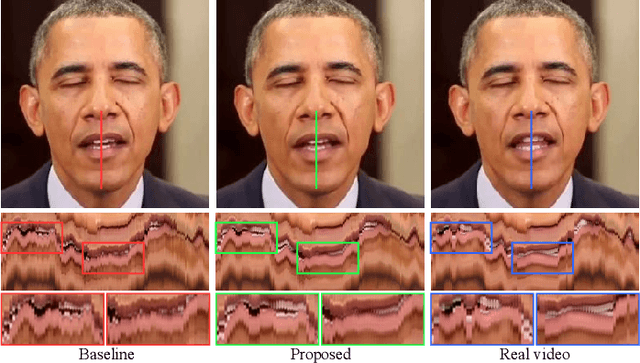
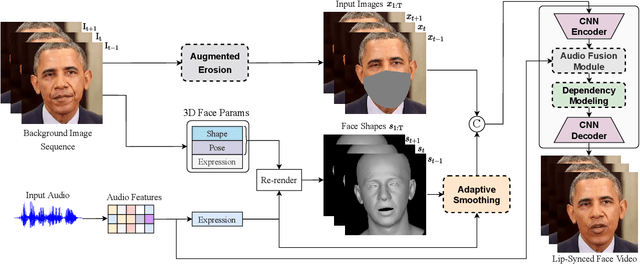
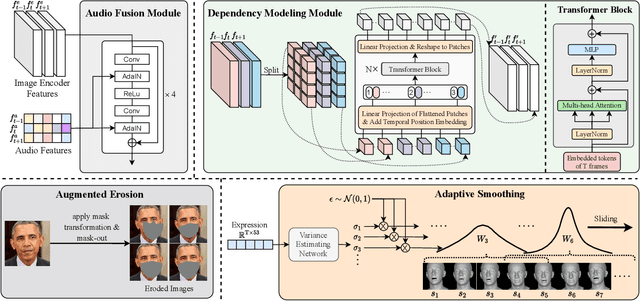

While previous speech-driven talking face generation methods have made significant progress in improving the visual quality and lip-sync quality of the synthesized videos, they pay less attention to lip motion jitters which greatly undermine the realness of talking face videos. What causes motion jitters, and how to mitigate the problem? In this paper, we conduct systematic analyses on the motion jittering problem based on a state-of-the-art pipeline that uses 3D face representations to bridge the input audio and output video, and improve the motion stability with a series of effective designs. We find that several issues can lead to jitters in synthesized talking face video: 1) jitters from the input 3D face representations; 2) training-inference mismatch; 3) lack of dependency modeling among video frames. Accordingly, we propose three effective solutions to address this issue: 1) we propose a gaussian-based adaptive smoothing module to smooth the 3D face representations to eliminate jitters in the input; 2) we add augmented erosions on the input data of the neural renderer in training to simulate the distortion in inference to reduce mismatch; 3) we develop an audio-fused transformer generator to model dependency among video frames. Besides, considering there is no off-the-shelf metric for measuring motion jitters in talking face video, we devise an objective metric (Motion Stability Index, MSI), to quantitatively measure the motion jitters by calculating the reciprocal of variance acceleration. Extensive experimental results show the superiority of our method on motion-stable face video generation, with better quality than previous systems.
Transformer-S2A: Robust and Efficient Speech-to-Animation
Nov 18, 2021
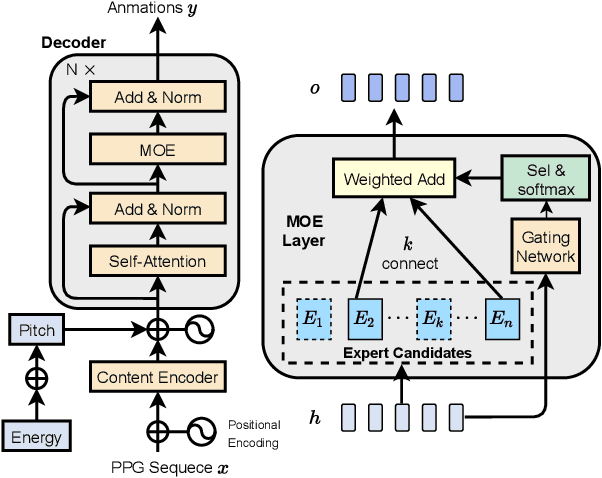
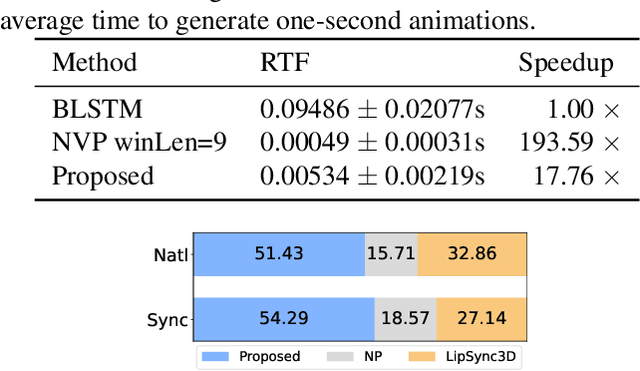

We propose a novel robust and efficient Speech-to-Animation (S2A) approach for synchronized facial animation generation in human-computer interaction. Compared with conventional approaches, the proposed approach utilize phonetic posteriorgrams (PPGs) of spoken phonemes as input to ensure the cross-language and cross-speaker ability, and introduce corresponding prosody features (i.e. pitch and energy) to further enhance the expression of generated animation. Mixtureof-experts (MOE)-based Transformer is employed to better model contextual information while provide significant optimization on computation efficiency. Experiments demonstrate the effectiveness of the proposed approach on both objective and subjective evaluation with 17x inference speedup compared with the state-of-the-art approach.