 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Streaming Target Speaker Extraction via Chunk-wise Interleaved Splicing of Autoregressive Language Model
Apr 21, 2026While generative models have set new benchmarks for Target Speaker Extraction (TSE), their inherent reliance on global context precludes deployment in real-time applications. Direct adaptation to streaming scenarios often leads to catastrophic inference performance degradation due to the severe mismatch between training and streaming inference. To bridge this gap, we present the first autoregressive (AR) models tailored for streaming TSE. Our approach introduces a Chunk-wise Interleaved Splicing Paradigm that ensures highly efficient and stable streaming inference. To ensure the coherence between the extracted speech segments, we design a historical context refinement mechanism that mitigates boundary discontinuities by leveraging historical information. Experiments on Libri2Mix show that while AR generative baseline exhibits performance degradation at low latencies, our approach maintains 100% stability and superior intelligibility. Furthermore, our streaming results are comparable to or even surpass offline baselines. Additionally, our model achieves a Real-Time-Factor (RTF) of 0.248 on consumer-level GPUs. This work provides empirical evidence that AR generative backbones are viable for latency-sensitive applications through the Chunk-wise Interleaved Splicing Paradigm.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation
Feb 12, 2026Recent advancements in foundation models have revolutionized joint audio-video generation. However, existing approaches typically treat human-centric tasks including reference-based audio-video generation (R2AV), video editing (RV2AV) and audio-driven video animation (RA2V) as isolated objectives. Furthermore, achieving precise, disentangled control over multiple character identities and voice timbres within a single framework remains an open challenge. In this paper, we propose DreamID-Omni, a unified framework for controllable human-centric audio-video generation. Specifically, we design a Symmetric Conditional Diffusion Transformer that integrates heterogeneous conditioning signals via a symmetric conditional injection scheme. To resolve the pervasive identity-timbre binding failures and speaker confusion in multi-person scenarios, we introduce a Dual-Level Disentanglement strategy: Synchronized RoPE at the signal level to ensure rigid attention-space binding, and Structured Captions at the semantic level to establish explicit attribute-subject mappings. Furthermore, we devise a Multi-Task Progressive Training scheme that leverages weakly-constrained generative priors to regularize strongly-constrained tasks, preventing overfitting and harmonizing disparate objectives. Extensive experiments demonstrate that DreamID-Omni achieves comprehensive state-of-the-art performance across video, audio, and audio-visual consistency, even outperforming leading proprietary commercial models. We will release our code to bridge the gap between academic research and commercial-grade applications.
AudioRouter: Data Efficient Audio Understanding via RL based Dual Reasoning
Feb 11, 2026Large Audio Language Models (LALMs) have demonstrated strong capabilities in audio understanding and reasoning. However, their performance on fine grained auditory perception remains unreliable, and existing approaches largely rely on data intensive training to internalize perceptual abilities. We propose AudioRouter, a reinforcement learning framework that enables LALMs to improve audio understanding by learning when and how to use external audio tools. Rather than tightly coupling tool usage with audio reasoning, AudioRouter formulates tool use as an explicit decision making problem and optimizes a lightweight routing policy while keeping the underlying reasoning model frozen. Experimental results show that AudioRouter achieves substantial improvements on standard audio understanding benchmarks while requiring up to 600x less training data to learn tool usage compared with conventional training paradigms. These findings suggest that learning effective tool usage offers a data efficient and scalable alternative to internalizing perceptual abilities in LALMs.
OptiSQL: Executable SQL Generation from Optical Tokens
Jan 21, 2026Executable SQL generation is typically studied in text-to-SQL settings, where tables are provided as fully linearized textual schemas and contents. While effective, this formulation assumes access to structured text and incurs substantial token overhead, which is misaligned with many real-world scenarios where tables appear as visual artifacts in documents or webpages. We investigate whether compact optical representations can serve as an efficient interface for executable semantic parsing. We present OptiSQL, a vision-driven framework that generates executable SQL directly from table images and natural language questions using compact optical tokens. OptiSQL leverages an OCR-oriented visual encoder to compress table structure and content into a small set of optical tokens and fine-tunes a pretrained decoder for SQL generation while freezing the encoder to isolate representation sufficiency. Experiments on a visualized version of Spider 2.0-Snow show that OptiSQL retains strong execution accuracy while reducing table input tokens by an order of magnitude. Robustness analyses further demonstrate that optical tokens preserve essential structural information under visual perturbations.
From Inpainting to Editing: A Self-Bootstrapping Framework for Context-Rich Visual Dubbing
Dec 31, 2025Audio-driven visual dubbing aims to synchronize a video's lip movements with new speech, but is fundamentally challenged by the lack of ideal training data: paired videos where only a subject's lip movements differ while all other visual conditions are identical. Existing methods circumvent this with a mask-based inpainting paradigm, where an incomplete visual conditioning forces models to simultaneously hallucinate missing content and sync lips, leading to visual artifacts, identity drift, and poor synchronization. In this work, we propose a novel self-bootstrapping framework that reframes visual dubbing from an ill-posed inpainting task into a well-conditioned video-to-video editing problem. Our approach employs a Diffusion Transformer, first as a data generator, to synthesize ideal training data: a lip-altered companion video for each real sample, forming visually aligned video pairs. A DiT-based audio-driven editor is then trained on these pairs end-to-end, leveraging the complete and aligned input video frames to focus solely on precise, audio-driven lip modifications. This complete, frame-aligned input conditioning forms a rich visual context for the editor, providing it with complete identity cues, scene interactions, and continuous spatiotemporal dynamics. Leveraging this rich context fundamentally enables our method to achieve highly accurate lip sync, faithful identity preservation, and exceptional robustness against challenging in-the-wild scenarios. We further introduce a timestep-adaptive multi-phase learning strategy as a necessary component to disentangle conflicting editing objectives across diffusion timesteps, thereby facilitating stable training and yielding enhanced lip synchronization and visual fidelity. Additionally, we propose ContextDubBench, a comprehensive benchmark dataset for robust evaluation in diverse and challenging practical application scenarios.
Detecting and Mitigating Insertion Hallucination in Video-to-Audio Generation
Oct 09, 2025Video-to-Audio generation has made remarkable strides in automatically synthesizing sound for video. However, existing evaluation metrics, which focus on semantic and temporal alignment, overlook a critical failure mode: models often generate acoustic events, particularly speech and music, that have no corresponding visual source. We term this phenomenon Insertion Hallucination and identify it as a systemic risk driven by dataset biases, such as the prevalence of off-screen sounds, that remains completely undetected by current metrics. To address this challenge, we first develop a systematic evaluation framework that employs a majority-voting ensemble of multiple audio event detectors. We also introduce two novel metrics to quantify the prevalence and severity of this issue: IH@vid (the fraction of videos with hallucinations) and IH@dur (the fraction of hallucinated duration). Building on this, we propose Posterior Feature Correction, a novel training-free inference-time method that mitigates IH. PFC operates in a two-pass process: it first generates an initial audio output to detect hallucinated segments, and then regenerates the audio after masking the corresponding video features at those timestamps. Experiments on several mainstream V2A benchmarks first reveal that state-of-the-art models suffer from severe IH. In contrast, our PFC method reduces both the prevalence and duration of hallucinations by over 50\% on average, without degrading, and in some cases even improving, conventional metrics for audio quality and temporal synchronization. Our work is the first to formally define, systematically measure, and effectively mitigate Insertion Hallucination, paving the way for more reliable and faithful V2A models.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Sep 10, 2025Human-Centric Video Generation (HCVG) methods seek to synthesize human videos from multimodal inputs, including text, image, and audio. Existing methods struggle to effectively coordinate these heterogeneous modalities due to two challenges: the scarcity of training data with paired triplet conditions and the difficulty of collaborating the sub-tasks of subject preservation and audio-visual sync with multimodal inputs. In this work, we present HuMo, a unified HCVG framework for collaborative multimodal control. For the first challenge, we construct a high-quality dataset with diverse and paired text, reference images, and audio. For the second challenge, we propose a two-stage progressive multimodal training paradigm with task-specific strategies. For the subject preservation task, to maintain the prompt following and visual generation abilities of the foundation model, we adopt the minimal-invasive image injection strategy. For the audio-visual sync task, besides the commonly adopted audio cross-attention layer, we propose a focus-by-predicting strategy that implicitly guides the model to associate audio with facial regions. For joint learning of controllabilities across multimodal inputs, building on previously acquired capabilities, we progressively incorporate the audio-visual sync task. During inference, for flexible and fine-grained multimodal control, we design a time-adaptive Classifier-Free Guidance strategy that dynamically adjusts guidance weights across denoising steps. Extensive experimental results demonstrate that HuMo surpasses specialized state-of-the-art methods in sub-tasks, establishing a unified framework for collaborative multimodal-conditioned HCVG. Project Page: https://phantom-video.github.io/HuMo.
BRIGHT+: Upgrading the BRIGHT Benchmark with MARCUS, a Multi-Agent RAG Clean-Up Suite
Jun 08, 2025Retrieval-Augmented Generation (RAG) systems require corpora that are both structurally clean and semantically coherent. BRIGHT is a recent and influential benchmark designed to evaluate complex multi-hop retrieval across diverse, high-reasoning domains. However, its practical effectiveness is limited by common web-crawled artifacts - such as content redundancy and semantic discontinuity - that impair retrieval accuracy and downstream reasoning. Notably, we find that such issues are concentrated in seven StackExchange-derived subdomains, while other domains (e.g., Coding and Theorem-based content) remain relatively clean. In this study, we present MARCUS, a multi-agent pipeline that leverages large language models (LLMs) to systematically clean and re-chunk BRIGHT into a higher-quality corpus: BRIGHT-Plus. MARCUS applies dedicated agents for structural noise removal and semantic segmentation, preserving answer-bearing spans while improving contextual integrity. Experimental evaluations demonstrate that BRIGHT-Plus yields consistent and significant improvements in both retrieval accuracy and multi-hop reasoning across a diverse set of retrievers. We release both the BRIGHT-Plus corpus and the MARCUS pipeline to support future research on robust, reasoning-centric retrieval.
MagicMan: Generative Novel View Synthesis of Humans with 3D-Aware Diffusion and Iterative Refinement
Aug 26, 2024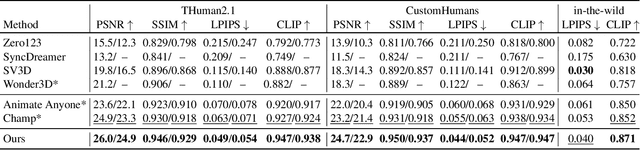
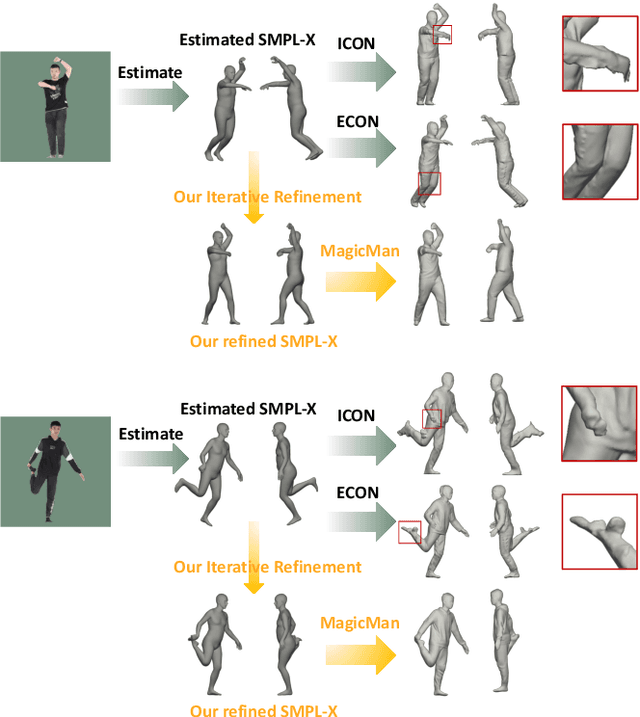
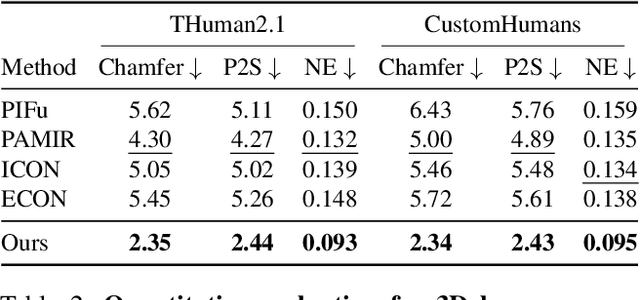
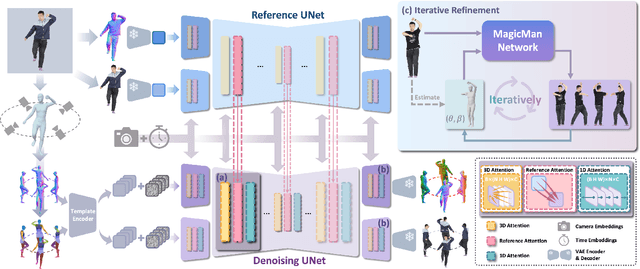
Existing works in single-image human reconstruction suffer from weak generalizability due to insufficient training data or 3D inconsistencies for a lack of comprehensive multi-view knowledge. In this paper, we introduce MagicMan, a human-specific multi-view diffusion model designed to generate high-quality novel view images from a single reference image. As its core, we leverage a pre-trained 2D diffusion model as the generative prior for generalizability, with the parametric SMPL-X model as the 3D body prior to promote 3D awareness. To tackle the critical challenge of maintaining consistency while achieving dense multi-view generation for improved 3D human reconstruction, we first introduce hybrid multi-view attention to facilitate both efficient and thorough information interchange across different views. Additionally, we present a geometry-aware dual branch to perform concurrent generation in both RGB and normal domains, further enhancing consistency via geometry cues. Last but not least, to address ill-shaped issues arising from inaccurate SMPL-X estimation that conflicts with the reference image, we propose a novel iterative refinement strategy, which progressively optimizes SMPL-X accuracy while enhancing the quality and consistency of the generated multi-views. Extensive experimental results demonstrate that our method significantly outperforms existing approaches in both novel view synthesis and subsequent 3D human reconstruction tasks.