 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
SkyReels-V3 Technique Report
Jan 24, 2026Video generation serves as a cornerstone for building world models, where multimodal contextual inference stands as the defining test of capability. In this end, we present SkyReels-V3, a conditional video generation model, built upon a unified multimodal in-context learning framework with diffusion Transformers. SkyReels-V3 model supports three core generative paradigms within a single architecture: reference images-to-video synthesis, video-to-video extension and audio-guided video generation. (i) reference images-to-video model is designed to produce high-fidelity videos with strong subject identity preservation, temporal coherence, and narrative consistency. To enhance reference adherence and compositional stability, we design a comprehensive data processing pipeline that leverages cross frame pairing, image editing, and semantic rewriting, effectively mitigating copy paste artifacts. During training, an image video hybrid strategy combined with multi-resolution joint optimization is employed to improve generalization and robustness across diverse scenarios. (ii) video extension model integrates spatio-temporal consistency modeling with large-scale video understanding, enabling both seamless single-shot continuation and intelligent multi-shot switching with professional cinematographic patterns. (iii) Talking avatar model supports minute-level audio-conditioned video generation by training first-and-last frame insertion patterns and reconstructing key-frame inference paradigms. On the basis of ensuring visual quality, synchronization of audio and videos has been optimized. Extensive evaluations demonstrate that SkyReels-V3 achieves state-of-the-art or near state-of-the-art performance on key metrics including visual quality, instruction following, and specific aspect metrics, approaching leading closed-source systems. Github: https://github.com/SkyworkAI/SkyReels-V3.
Skywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

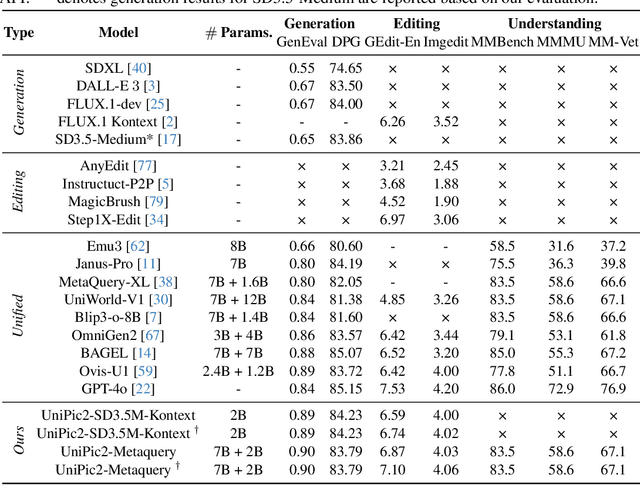
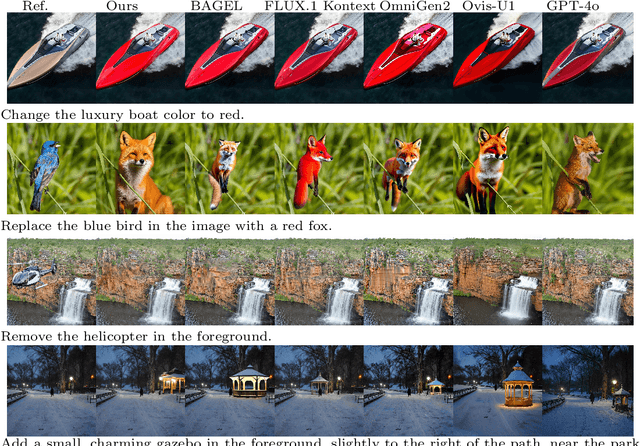
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Matrix-3D: Omnidirectional Explorable 3D World Generation
Aug 11, 2025Explorable 3D world generation from a single image or text prompt forms a cornerstone of spatial intelligence. Recent works utilize video model to achieve wide-scope and generalizable 3D world generation. However, existing approaches often suffer from a limited scope in the generated scenes. In this work, we propose Matrix-3D, a framework that utilize panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction. We first train a trajectory-guided panoramic video diffusion model that employs scene mesh renders as condition, to enable high-quality and geometrically consistent scene video generation. To lift the panorama scene video to 3D world, we propose two separate methods: (1) a feed-forward large panorama reconstruction model for rapid 3D scene reconstruction and (2) an optimization-based pipeline for accurate and detailed 3D scene reconstruction. To facilitate effective training, we also introduce the Matrix-Pano dataset, the first large-scale synthetic collection comprising 116K high-quality static panoramic video sequences with depth and trajectory annotations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance in panoramic video generation and 3D world generation. See more in https://matrix-3d.github.io.
Skywork-R1V3 Technical Report
Jul 09, 2025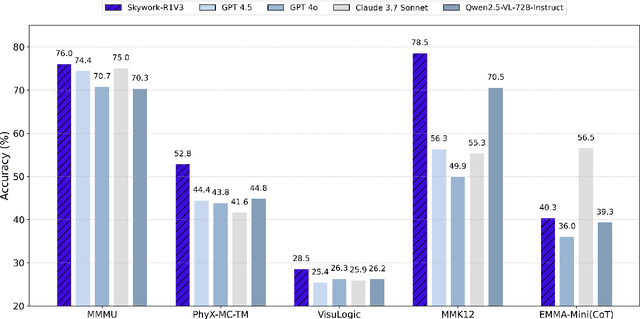
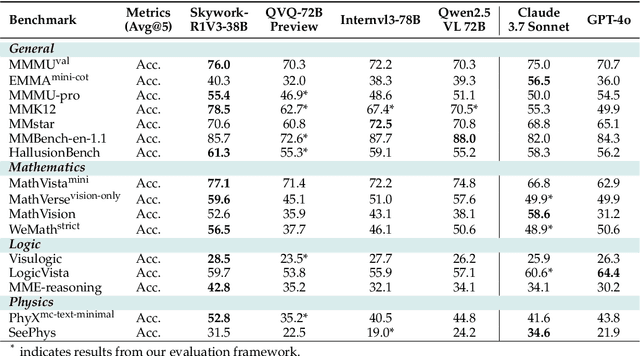
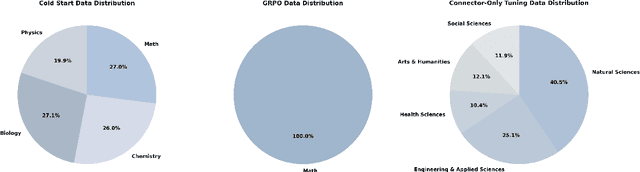

We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model's reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Jul 02, 2025Despite the critical role of reward models (RMs) in reinforcement learning from human feedback (RLHF), current state-of-the-art open RMs perform poorly on most existing evaluation benchmarks, failing to capture the spectrum of nuanced and sophisticated human preferences. Even approaches that incorporate advanced training techniques have not yielded meaningful performance improvements. We hypothesize that this brittleness stems primarily from limitations in preference datasets, which are often narrowly scoped, synthetically labeled, or lack rigorous quality control. To address these challenges, we present a large-scale preference dataset comprising 40 million preference pairs, named SynPref-40M. To enable data curation at scale, we design a human-AI synergistic two-stage pipeline that leverages the complementary strengths of human annotation quality and AI scalability. In this pipeline, humans provide verified annotations, while large language models perform automatic curation based on human guidance. Training on this preference mixture, we introduce Skywork-Reward-V2, a suite of eight reward models ranging from 0.6B to 8B parameters, trained on a carefully curated subset of 26 million preference pairs from SynPref-40M. We demonstrate that Skywork-Reward-V2 is versatile across a wide range of capabilities, including alignment with human preferences, objective correctness, safety, resistance to stylistic biases, and best-of-N scaling, achieving state-of-the-art performance across seven major reward model benchmarks. Ablation studies confirm that the effectiveness of our approach stems not only from data scale but also from high-quality curation. The Skywork-Reward-V2 series represents substantial progress in open reward models, highlighting the untapped potential of existing preference datasets and demonstrating how human-AI curation synergy can unlock significantly higher data quality.
Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs
Jun 24, 2025Software engineering (SWE) has recently emerged as a crucial testbed for next-generation LLM agents, demanding inherent capabilities in two critical dimensions: sustained iterative problem-solving (e.g., >50 interaction rounds) and long-context dependency resolution (e.g., >32k tokens). However, the data curation process in SWE remains notoriously time-consuming, as it heavily relies on manual annotation for code file filtering and the setup of dedicated runtime environments to execute and validate unit tests. Consequently, most existing datasets are limited to only a few thousand GitHub-sourced instances. To this end, we propose an incremental, automated data-curation pipeline that systematically scales both the volume and diversity of SWE datasets. Our dataset comprises 10,169 real-world Python task instances from 2,531 distinct GitHub repositories, each accompanied by a task specified in natural language and a dedicated runtime-environment image for automated unit-test validation. We have carefully curated over 8,000 successfully runtime-validated training trajectories from our proposed SWE dataset. When fine-tuning the Skywork-SWE model on these trajectories, we uncover a striking data scaling phenomenon: the trained model's performance for software engineering capabilities in LLMs continues to improve as the data size increases, showing no signs of saturation. Notably, our Skywork-SWE model achieves 38.0% pass@1 accuracy on the SWE-bench Verified benchmark without using verifiers or multiple rollouts, establishing a new state-of-the-art (SOTA) among the Qwen2.5-Coder-32B-based LLMs built on the OpenHands agent framework. Furthermore, with the incorporation of test-time scaling techniques, the performance further improves to 47.0% accuracy, surpassing the previous SOTA results for sub-32B parameter models. We release the Skywork-SWE-32B model checkpoint to accelerate future research.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
Skywork-VL Reward: An Effective Reward Model for Multimodal Understanding and Reasoning
May 12, 2025We propose Skywork-VL Reward, a multimodal reward model that provides reward signals for both multimodal understanding and reasoning tasks. Our technical approach comprises two key components: First, we construct a large-scale multimodal preference dataset that covers a wide range of tasks and scenarios, with responses collected from both standard vision-language models (VLMs) and advanced VLM reasoners. Second, we design a reward model architecture based on Qwen2.5-VL-7B-Instruct, integrating a reward head and applying multi-stage fine-tuning using pairwise ranking loss on pairwise preference data. Experimental evaluations show that Skywork-VL Reward achieves state-of-the-art results on multimodal VL-RewardBench and exhibits competitive performance on the text-only RewardBench benchmark. Furthermore, preference data constructed based on our Skywork-VL Reward proves highly effective for training Mixed Preference Optimization (MPO), leading to significant improvements in multimodal reasoning capabilities. Our results underscore Skywork-VL Reward as a significant advancement toward general-purpose, reliable reward models for multimodal alignment. Our model has been publicly released to promote transparency and reproducibility.