 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackPlanner: A Centralized Hierarchical Multi-Agent System with Task-Experience Memory Management
Jan 09, 2026Multi-agent systems based on large language models, particularly centralized architectures, have recently shown strong potential for complex and knowledge-intensive tasks. However, central agents often suffer from unstable long-horizon collaboration due to the lack of memory management, leading to context bloat, error accumulation, and poor cross-task generalization. To address both task-level memory inefficiency and the inability to reuse coordination experience, we propose StackPlanner, a hierarchical multi-agent framework with explicit memory control. StackPlanner addresses these challenges by decoupling high-level coordination from subtask execution with active task-level memory control, and by learning to retrieve and exploit reusable coordination experience via structured experience memory and reinforcement learning. Experiments on multiple deep-search and agent system benchmarks demonstrate the effectiveness of our approach in enabling reliable long-horizon multi-agent collaboration.
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Jul 02, 2025Despite the critical role of reward models (RMs) in reinforcement learning from human feedback (RLHF), current state-of-the-art open RMs perform poorly on most existing evaluation benchmarks, failing to capture the spectrum of nuanced and sophisticated human preferences. Even approaches that incorporate advanced training techniques have not yielded meaningful performance improvements. We hypothesize that this brittleness stems primarily from limitations in preference datasets, which are often narrowly scoped, synthetically labeled, or lack rigorous quality control. To address these challenges, we present a large-scale preference dataset comprising 40 million preference pairs, named SynPref-40M. To enable data curation at scale, we design a human-AI synergistic two-stage pipeline that leverages the complementary strengths of human annotation quality and AI scalability. In this pipeline, humans provide verified annotations, while large language models perform automatic curation based on human guidance. Training on this preference mixture, we introduce Skywork-Reward-V2, a suite of eight reward models ranging from 0.6B to 8B parameters, trained on a carefully curated subset of 26 million preference pairs from SynPref-40M. We demonstrate that Skywork-Reward-V2 is versatile across a wide range of capabilities, including alignment with human preferences, objective correctness, safety, resistance to stylistic biases, and best-of-N scaling, achieving state-of-the-art performance across seven major reward model benchmarks. Ablation studies confirm that the effectiveness of our approach stems not only from data scale but also from high-quality curation. The Skywork-Reward-V2 series represents substantial progress in open reward models, highlighting the untapped potential of existing preference datasets and demonstrating how human-AI curation synergy can unlock significantly higher data quality.
Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs
Jun 24, 2025Software engineering (SWE) has recently emerged as a crucial testbed for next-generation LLM agents, demanding inherent capabilities in two critical dimensions: sustained iterative problem-solving (e.g., >50 interaction rounds) and long-context dependency resolution (e.g., >32k tokens). However, the data curation process in SWE remains notoriously time-consuming, as it heavily relies on manual annotation for code file filtering and the setup of dedicated runtime environments to execute and validate unit tests. Consequently, most existing datasets are limited to only a few thousand GitHub-sourced instances. To this end, we propose an incremental, automated data-curation pipeline that systematically scales both the volume and diversity of SWE datasets. Our dataset comprises 10,169 real-world Python task instances from 2,531 distinct GitHub repositories, each accompanied by a task specified in natural language and a dedicated runtime-environment image for automated unit-test validation. We have carefully curated over 8,000 successfully runtime-validated training trajectories from our proposed SWE dataset. When fine-tuning the Skywork-SWE model on these trajectories, we uncover a striking data scaling phenomenon: the trained model's performance for software engineering capabilities in LLMs continues to improve as the data size increases, showing no signs of saturation. Notably, our Skywork-SWE model achieves 38.0% pass@1 accuracy on the SWE-bench Verified benchmark without using verifiers or multiple rollouts, establishing a new state-of-the-art (SOTA) among the Qwen2.5-Coder-32B-based LLMs built on the OpenHands agent framework. Furthermore, with the incorporation of test-time scaling techniques, the performance further improves to 47.0% accuracy, surpassing the previous SOTA results for sub-32B parameter models. We release the Skywork-SWE-32B model checkpoint to accelerate future research.
EL4NER: Ensemble Learning for Named Entity Recognition via Multiple Small-Parameter Large Language Models
May 29, 2025In-Context Learning (ICL) technique based on Large Language Models (LLMs) has gained prominence in Named Entity Recognition (NER) tasks for its lower computing resource consumption, less manual labeling overhead, and stronger generalizability. Nevertheless, most ICL-based NER methods depend on large-parameter LLMs: the open-source models demand substantial computational resources for deployment and inference, while the closed-source ones incur high API costs, raise data-privacy concerns, and hinder community collaboration. To address this question, we propose an Ensemble Learning Method for Named Entity Recognition (EL4NER), which aims at aggregating the ICL outputs of multiple open-source, small-parameter LLMs to enhance overall performance in NER tasks at less deployment and inference cost. Specifically, our method comprises three key components. First, we design a task decomposition-based pipeline that facilitates deep, multi-stage ensemble learning. Second, we introduce a novel span-level sentence similarity algorithm to establish an ICL demonstration retrieval mechanism better suited for NER tasks. Third, we incorporate a self-validation mechanism to mitigate the noise introduced during the ensemble process. We evaluated EL4NER on multiple widely adopted NER datasets from diverse domains. Our experimental results indicate that EL4NER surpasses most closed-source, large-parameter LLM-based methods at a lower parameter cost and even attains state-of-the-art (SOTA) performance among ICL-based methods on certain datasets. These results show the parameter efficiency of EL4NER and underscore the feasibility of employing open-source, small-parameter LLMs within the ICL paradigm for NER tasks.
Parenting: Optimizing Knowledge Selection of Retrieval-Augmented Language Models with Parameter Decoupling and Tailored Tuning
Oct 14, 2024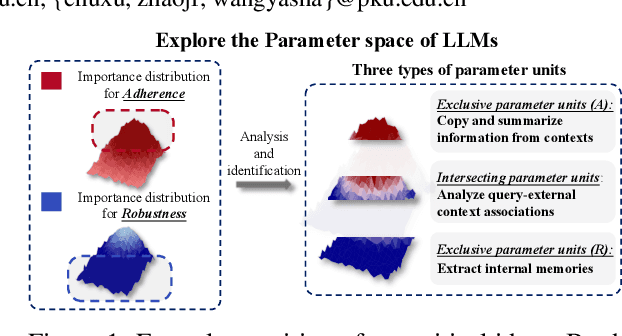
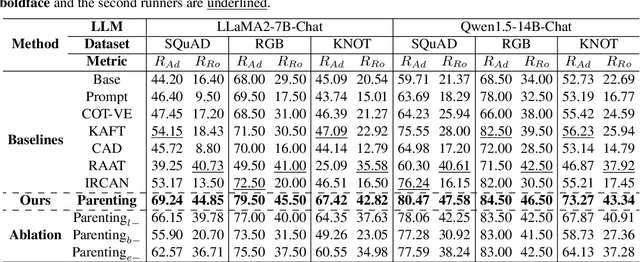
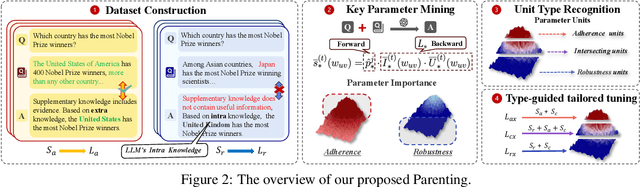
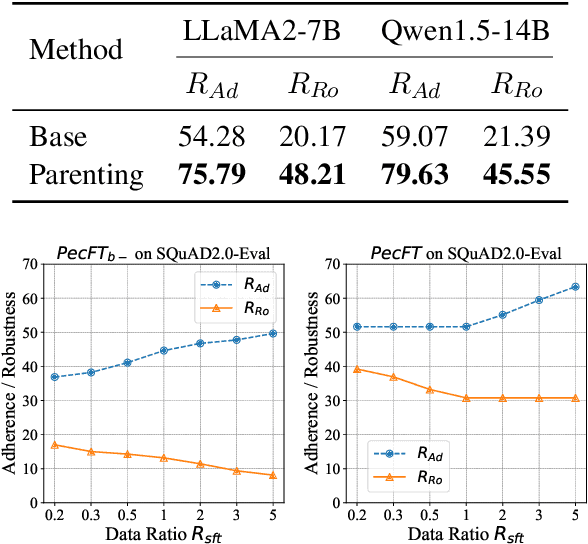
Retrieval-Augmented Generation (RAG) offers an effective solution to the issues faced by Large Language Models (LLMs) in hallucination generation and knowledge obsolescence by incorporating externally retrieved knowledge. However, due to potential conflicts between internal and external knowledge, as well as retrieval noise, LLMs often struggle to effectively integrate external evidence, leading to a decline in performance. Although existing methods attempt to tackle these challenges, they often struggle to strike a balance between model adherence and robustness, resulting in significant learning variance. Inspired by human cognitive processes, we propose Parenting, a novel framework that decouples adherence and robustness within the parameter space of LLMs. Specifically, Parenting utilizes a key parameter mining method based on forward activation gain to identify and isolate the crucial parameter units that are strongly linked to adherence and robustness. Then, Parenting employs a type-guided tailored tuning strategy, applying specific and appropriate fine-tuning methods to parameter units representing different capabilities, aiming to achieve a balanced enhancement of adherence and robustness. Extensive experiments on various datasets and models validate the effectiveness and generalizability of our methods.
KnowPO: Knowledge-aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models
Aug 19, 2024

By integrating external knowledge, Retrieval-Augmented Generation (RAG) has become an effective strategy for mitigating the hallucination problems that large language models (LLMs) encounter when dealing with knowledge-intensive tasks. However, in the process of integrating external non-parametric supporting evidence with internal parametric knowledge, inevitable knowledge conflicts may arise, leading to confusion in the model's responses. To enhance the knowledge selection of LLMs in various contexts, some research has focused on refining their behavior patterns through instruction-tuning. Nonetheless, due to the absence of explicit negative signals and comparative objectives, models fine-tuned in this manner may still exhibit undesirable behaviors such as contextual ignorance and contextual overinclusion. To this end, we propose a Knowledge-aware Preference Optimization strategy, dubbed KnowPO, aimed at achieving adaptive knowledge selection based on contextual relevance in real retrieval scenarios. Concretely, we proposed a general paradigm for constructing knowledge conflict datasets, which comprehensively cover various error types and learn how to avoid these negative signals through preference optimization methods. Simultaneously, we proposed a rewriting strategy and data ratio optimization strategy to address preference imbalances. Experimental results show that KnowPO outperforms previous methods for handling knowledge conflicts by over 37\%, while also exhibiting robust generalization across various out-of-distribution datasets.
KaPO: Knowledge-aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models
Aug 06, 2024By integrating external knowledge, Retrieval-Augmented Generation (RAG) has become an effective strategy for mitigating the hallucination problems that large language models (LLMs) encounter when dealing with knowledge-intensive tasks. However, in the process of integrating external non-parametric supporting evidence with internal parametric knowledge, inevitable knowledge conflicts may arise, leading to confusion in the model's responses. To enhance the knowledge selection of LLMs in various contexts, some research has focused on refining their behavior patterns through instruction-tuning. Nonetheless, due to the absence of explicit negative signals and comparative objectives, models fine-tuned in this manner may still exhibit undesirable behaviors in the intricate and realistic retrieval scenarios. To this end, we propose a Knowledge-aware Preference Optimization, dubbed KaPO, aimed at achieving controllable knowledge selection in real retrieval scenarios. Concretely, we explore and simulate error types across diverse context combinations and learn how to avoid these negative signals through preference optimization methods. Simultaneously, by adjusting the balance between response length and the proportion of preference data representing different behavior patterns, we enhance the adherence capabilities and noise robustness of LLMs in a balanced manner. Experimental results show that KaPO outperforms previous methods for handling knowledge conflicts by over 37%, while also exhibiting robust generalization across various out-of-distribution datasets.