 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling via Stochastic Interpolants by Langevin-based Velocity and Initialization Estimation in Flow ODEs
Jan 13, 2026We propose a novel method for sampling from unnormalized Boltzmann densities based on a probability-flow ordinary differential equation (ODE) derived from linear stochastic interpolants. The key innovation of our approach is the use of a sequence of Langevin samplers to enable efficient simulation of the flow. Specifically, these Langevin samplers are employed (i) to generate samples from the interpolant distribution at intermediate times and (ii) to construct, starting from these intermediate times, a robust estimator of the velocity field governing the flow ODE. For both applications of the Langevin diffusions, we establish convergence guarantees. Extensive numerical experiments demonstrate the efficiency of the proposed method on challenging multimodal distributions across a range of dimensions, as well as its effectiveness in Bayesian inference tasks.
StackPlanner: A Centralized Hierarchical Multi-Agent System with Task-Experience Memory Management
Jan 09, 2026Multi-agent systems based on large language models, particularly centralized architectures, have recently shown strong potential for complex and knowledge-intensive tasks. However, central agents often suffer from unstable long-horizon collaboration due to the lack of memory management, leading to context bloat, error accumulation, and poor cross-task generalization. To address both task-level memory inefficiency and the inability to reuse coordination experience, we propose StackPlanner, a hierarchical multi-agent framework with explicit memory control. StackPlanner addresses these challenges by decoupling high-level coordination from subtask execution with active task-level memory control, and by learning to retrieve and exploit reusable coordination experience via structured experience memory and reinforcement learning. Experiments on multiple deep-search and agent system benchmarks demonstrate the effectiveness of our approach in enabling reliable long-horizon multi-agent collaboration.
EL4NER: Ensemble Learning for Named Entity Recognition via Multiple Small-Parameter Large Language Models
May 29, 2025In-Context Learning (ICL) technique based on Large Language Models (LLMs) has gained prominence in Named Entity Recognition (NER) tasks for its lower computing resource consumption, less manual labeling overhead, and stronger generalizability. Nevertheless, most ICL-based NER methods depend on large-parameter LLMs: the open-source models demand substantial computational resources for deployment and inference, while the closed-source ones incur high API costs, raise data-privacy concerns, and hinder community collaboration. To address this question, we propose an Ensemble Learning Method for Named Entity Recognition (EL4NER), which aims at aggregating the ICL outputs of multiple open-source, small-parameter LLMs to enhance overall performance in NER tasks at less deployment and inference cost. Specifically, our method comprises three key components. First, we design a task decomposition-based pipeline that facilitates deep, multi-stage ensemble learning. Second, we introduce a novel span-level sentence similarity algorithm to establish an ICL demonstration retrieval mechanism better suited for NER tasks. Third, we incorporate a self-validation mechanism to mitigate the noise introduced during the ensemble process. We evaluated EL4NER on multiple widely adopted NER datasets from diverse domains. Our experimental results indicate that EL4NER surpasses most closed-source, large-parameter LLM-based methods at a lower parameter cost and even attains state-of-the-art (SOTA) performance among ICL-based methods on certain datasets. These results show the parameter efficiency of EL4NER and underscore the feasibility of employing open-source, small-parameter LLMs within the ICL paradigm for NER tasks.
RAGraph: A General Retrieval-Augmented Graph Learning Framework
Oct 31, 2024



Graph Neural Networks (GNNs) have become essential in interpreting relational data across various domains, yet, they often struggle to generalize to unseen graph data that differs markedly from training instances. In this paper, we introduce a novel framework called General Retrieval-Augmented Graph Learning (RAGraph), which brings external graph data into the general graph foundation model to improve model generalization on unseen scenarios. On the top of our framework is a toy graph vector library that we established, which captures key attributes, such as features and task-specific label information. During inference, the RAGraph adeptly retrieves similar toy graphs based on key similarities in downstream tasks, integrating the retrieved data to enrich the learning context via the message-passing prompting mechanism. Our extensive experimental evaluations demonstrate that RAGraph significantly outperforms state-of-the-art graph learning methods in multiple tasks such as node classification, link prediction, and graph classification across both dynamic and static datasets. Furthermore, extensive testing confirms that RAGraph consistently maintains high performance without the need for task-specific fine-tuning, highlighting its adaptability, robustness, and broad applicability.
Parenting: Optimizing Knowledge Selection of Retrieval-Augmented Language Models with Parameter Decoupling and Tailored Tuning
Oct 14, 2024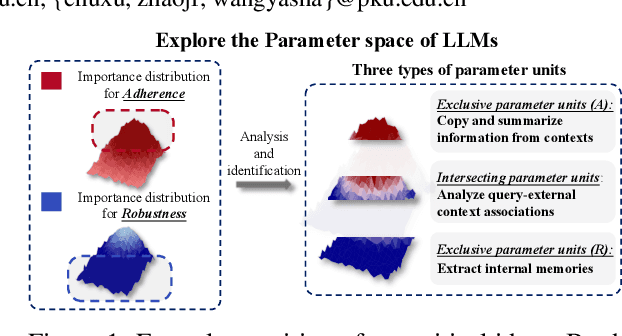
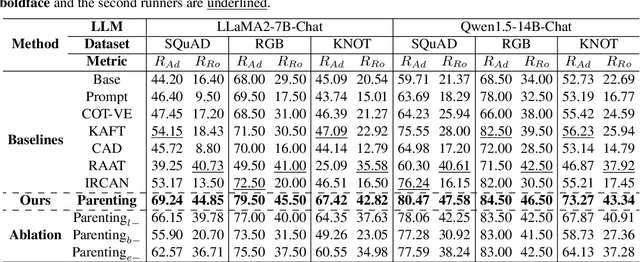
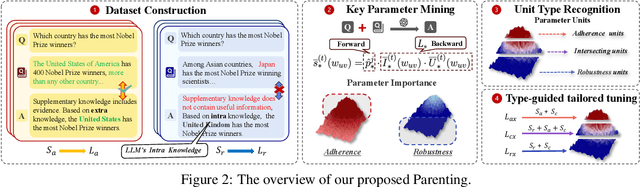
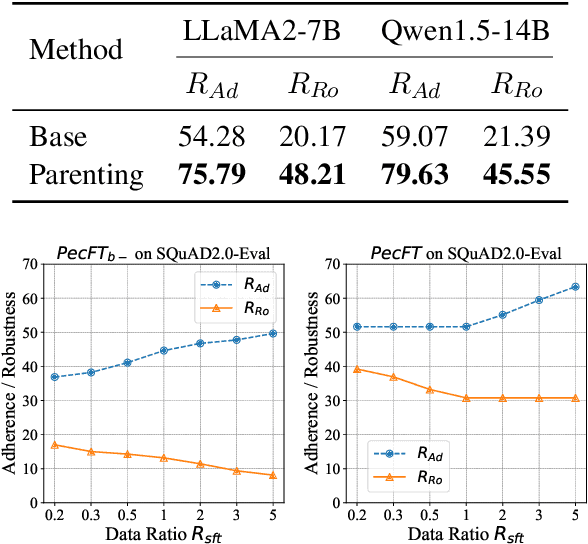
Retrieval-Augmented Generation (RAG) offers an effective solution to the issues faced by Large Language Models (LLMs) in hallucination generation and knowledge obsolescence by incorporating externally retrieved knowledge. However, due to potential conflicts between internal and external knowledge, as well as retrieval noise, LLMs often struggle to effectively integrate external evidence, leading to a decline in performance. Although existing methods attempt to tackle these challenges, they often struggle to strike a balance between model adherence and robustness, resulting in significant learning variance. Inspired by human cognitive processes, we propose Parenting, a novel framework that decouples adherence and robustness within the parameter space of LLMs. Specifically, Parenting utilizes a key parameter mining method based on forward activation gain to identify and isolate the crucial parameter units that are strongly linked to adherence and robustness. Then, Parenting employs a type-guided tailored tuning strategy, applying specific and appropriate fine-tuning methods to parameter units representing different capabilities, aiming to achieve a balanced enhancement of adherence and robustness. Extensive experiments on various datasets and models validate the effectiveness and generalizability of our methods.
LexEval: A Comprehensive Chinese Legal Benchmark for Evaluating Large Language Models
Sep 30, 2024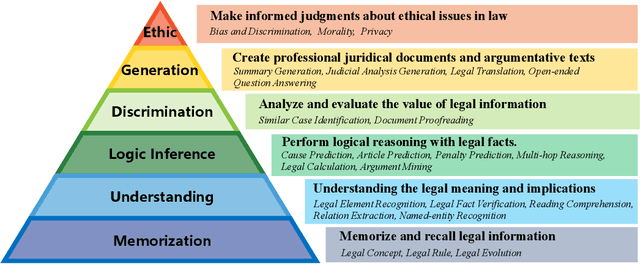



Large language models (LLMs) have made significant progress in natural language processing tasks and demonstrate considerable potential in the legal domain. However, legal applications demand high standards of accuracy, reliability, and fairness. Applying existing LLMs to legal systems without careful evaluation of their potential and limitations could pose significant risks in legal practice. To this end, we introduce a standardized comprehensive Chinese legal benchmark LexEval. This benchmark is notable in the following three aspects: (1) Ability Modeling: We propose a new taxonomy of legal cognitive abilities to organize different tasks. (2) Scale: To our knowledge, LexEval is currently the largest Chinese legal evaluation dataset, comprising 23 tasks and 14,150 questions. (3) Data: we utilize formatted existing datasets, exam datasets and newly annotated datasets by legal experts to comprehensively evaluate the various capabilities of LLMs. LexEval not only focuses on the ability of LLMs to apply fundamental legal knowledge but also dedicates efforts to examining the ethical issues involved in their application. We evaluated 38 open-source and commercial LLMs and obtained some interesting findings. The experiments and findings offer valuable insights into the challenges and potential solutions for developing Chinese legal systems and LLM evaluation pipelines. The LexEval dataset and leaderboard are publicly available at \url{https://github.com/CSHaitao/LexEval} and will be continuously updated.
KnowPO: Knowledge-aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models
Aug 19, 2024

By integrating external knowledge, Retrieval-Augmented Generation (RAG) has become an effective strategy for mitigating the hallucination problems that large language models (LLMs) encounter when dealing with knowledge-intensive tasks. However, in the process of integrating external non-parametric supporting evidence with internal parametric knowledge, inevitable knowledge conflicts may arise, leading to confusion in the model's responses. To enhance the knowledge selection of LLMs in various contexts, some research has focused on refining their behavior patterns through instruction-tuning. Nonetheless, due to the absence of explicit negative signals and comparative objectives, models fine-tuned in this manner may still exhibit undesirable behaviors such as contextual ignorance and contextual overinclusion. To this end, we propose a Knowledge-aware Preference Optimization strategy, dubbed KnowPO, aimed at achieving adaptive knowledge selection based on contextual relevance in real retrieval scenarios. Concretely, we proposed a general paradigm for constructing knowledge conflict datasets, which comprehensively cover various error types and learn how to avoid these negative signals through preference optimization methods. Simultaneously, we proposed a rewriting strategy and data ratio optimization strategy to address preference imbalances. Experimental results show that KnowPO outperforms previous methods for handling knowledge conflicts by over 37\%, while also exhibiting robust generalization across various out-of-distribution datasets.
TC-RAG:Turing-Complete RAG's Case study on Medical LLM Systems
Aug 17, 2024



In the pursuit of enhancing domain-specific Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) emerges as a promising solution to mitigate issues such as hallucinations, outdated knowledge, and limited expertise in highly specialized queries. However, existing approaches to RAG fall short by neglecting system state variables, which are crucial for ensuring adaptive control, retrieval halting, and system convergence. In this paper, we introduce the TC-RAG through rigorous proof, a novel framework that addresses these challenges by incorporating a Turing Complete System to manage state variables, thereby enabling more efficient and accurate knowledge retrieval. By leveraging a memory stack system with adaptive retrieval, reasoning, and planning capabilities, TC-RAG not only ensures the controlled halting of retrieval processes but also mitigates the accumulation of erroneous knowledge via Push and Pop actions. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of TC-RAG over existing methods in accuracy by over 7.20\%. Our dataset and code have been available at https://https://github.com/Artessay/SAMA.git.
KaPO: Knowledge-aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models
Aug 06, 2024By integrating external knowledge, Retrieval-Augmented Generation (RAG) has become an effective strategy for mitigating the hallucination problems that large language models (LLMs) encounter when dealing with knowledge-intensive tasks. However, in the process of integrating external non-parametric supporting evidence with internal parametric knowledge, inevitable knowledge conflicts may arise, leading to confusion in the model's responses. To enhance the knowledge selection of LLMs in various contexts, some research has focused on refining their behavior patterns through instruction-tuning. Nonetheless, due to the absence of explicit negative signals and comparative objectives, models fine-tuned in this manner may still exhibit undesirable behaviors in the intricate and realistic retrieval scenarios. To this end, we propose a Knowledge-aware Preference Optimization, dubbed KaPO, aimed at achieving controllable knowledge selection in real retrieval scenarios. Concretely, we explore and simulate error types across diverse context combinations and learn how to avoid these negative signals through preference optimization methods. Simultaneously, by adjusting the balance between response length and the proportion of preference data representing different behavior patterns, we enhance the adherence capabilities and noise robustness of LLMs in a balanced manner. Experimental results show that KaPO outperforms previous methods for handling knowledge conflicts by over 37%, while also exhibiting robust generalization across various out-of-distribution datasets.
The ESPRIT algorithm under high noise: Optimal error scaling and noisy super-resolution
Apr 05, 2024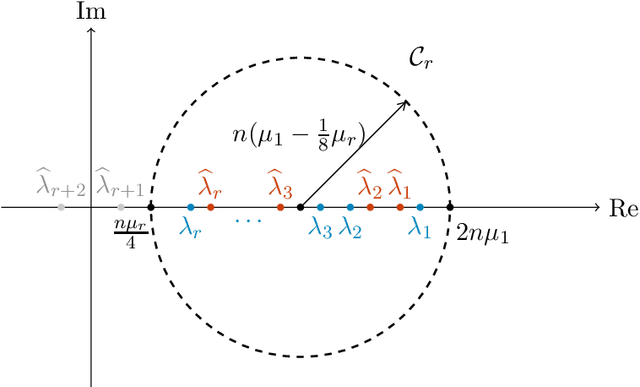
Subspace-based signal processing techniques, such as the Estimation of Signal Parameters via Rotational Invariant Techniques (ESPRIT) algorithm, are popular methods for spectral estimation. These algorithms can achieve the so-called super-resolution scaling under low noise conditions, surpassing the well-known Nyquist limit. However, the performance of these algorithms under high-noise conditions is not as well understood. Existing state-of-the-art analysis indicates that ESPRIT and related algorithms can be resilient even for signals where each observation is corrupted by statistically independent, mean-zero noise of size $\mathcal{O}(1)$, but these analyses only show that the error $\epsilon$ decays at a slow rate $\epsilon=\mathcal{\tilde{O}}(n^{-1/2})$ with respect to the cutoff frequency $n$. In this work, we prove that under certain assumptions of bias and high noise, the ESPRIT algorithm can attain a significantly improved error scaling $\epsilon = \mathcal{\tilde{O}}(n^{-3/2})$, exhibiting noisy super-resolution scaling beyond the Nyquist limit. We further establish a theoretical lower bound and show that this scaling is optimal. Our analysis introduces novel matrix perturbation results, which could be of independent interest.